


Зачем инструмент dbt нужен аналитику

Представляем подробный гайд по dbt — Data Build Tool — одному из лучших фреймворков для трансформации данных.
8К открытий17К показов
dbt — open-source инструмент, который решает проблему организации данных и открывает много возможностей для их трансформации и моделирования. В статье разберём функционал и характеристики фреймворка, а также опишем пошагово процесс его настройки и использования.

Илья Тищенко
архитектор хранилища данных «Ростелеком»
Что такое dbt: функционал и характеристики
dbt (Data Build Tool) — инструмент, который позволяет дата-инженерам и аналитикам автоматизировать процессы тестирования, внедрения, документирования в рамках трансформации данных. Проще говоря, dbt — это всё о букве T в акрониме ELT (Extract — Transform — Load). Этот фреймворк не выгружает данные из источников, но предоставляет огромные возможности по работе с теми данными, которые уже загружены в Хранилище (в Internal или External Storage).
dbt основан на языках SQL и Jinja, с версии 1.4.* также поддерживает Python.
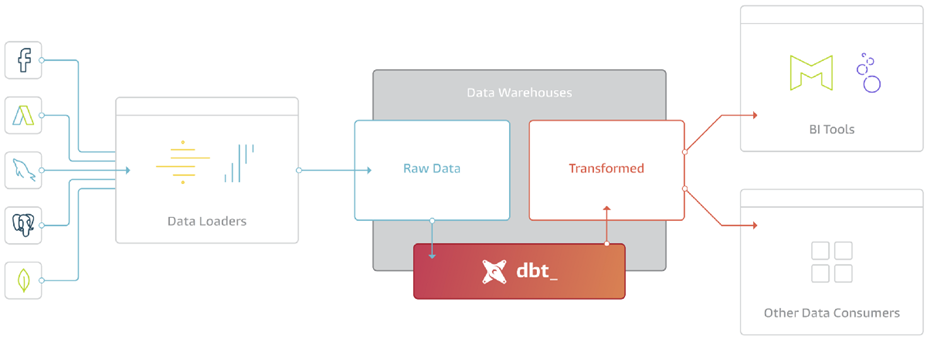
Основное назначение dbt — взять код, скомпилировать его в SQL, выполнить команды в правильной последовательности в хранилище.
Как можно использовать инструмент
Облачное решение:
● Веб-интерфейс
● Переменные окружения
● Планировщики, метаданные, IDE
● Интеграции с другими инструментами
Core:
● Открытый исходный код
● Работа через командную строку
Какие платформы поддерживает
Поддержка команды:
● AlloyDB
● Azure Synapse
● BigQuery
● Databricks
● Dremio
● Postgres
● Redshift
● Snowflake
● Spark
● Starburst & Trino
Поддержка сообщества:
● Athena
● Clickhouse
● IBM DB2
● Doris & SelectDB
● DuckDB
● и другие
Экосистема dbt
IDE инструменты:
● Visual Stusio Code
● deep channnel
● PopSQL
● Count
Инструменты разработки:
● dbt Power User
● SQLFluff
● Better Jinja
● dbt-osmosis
● poentry
● pre-commit
Чем полезен фреймворк
dbt — довольно универсальный инструмент, но в большей степени он используется в аналитических сервисах в любых отраслях: анализ и обработка данных, сборка любой отчетности и так далее.
Контроль качества. Для бизнеса важно получать качественные данные, а для этого, в свою очередь, нужны инструменты контроля качества. dbt как инструмент позволяет реализовать любые вариации тестирования: на этапе обновления каких-либо данных мы всегда можем собрать быструю статистику по любым метрикам.
Хранение данных. Даже из «коробки» этот фреймворк позволяет реализовать на уровне хранилища хранение данных с историей СКД-2 (хранения технической истории, изменение атрибутов). С ним можно выстраивать снэпшоты — детальные слои с историей данных. dbt помогает собрать любую историю данных, чтобы отвечать на вопросы аналитиков и бизнеса.
Связывание данных в единую цепочку. Инструмент описывает ациклические зависимости (DAG) и связи, что позволяет легко анализировать цепочку преобразований данных. Когда мы используем и переиспользуем данные, выполнение этих задач связано: если что-то где-то меняется, то сказывается на других сущностях. С помощью dbt мы решаем задачу консистентности данных — устраиваем зависимость выполнения, чтобы одна сущность была рассчитана только после другой, без задержек и потери актуальности данных. Фреймворк помогает собрать в одном месте и связать всю логику — от исходных данных до итоговых результатов и их переиспользования.
Перенос в другие среды. Фреймворк позволяет легко переносить и настраивать разные подходы к работе моделей в различных средах: тестовые модели, продуктовый уровень, промышленный слой.
Настройка дополнительных возможностей. С dbt можно вписать документацию данных и работать с ними, можно настроить логирование стандартными способами и отслеживать аналитику исполнения запросов. Всё это реализуемо, поскольку у фреймворка на основе SQL и Jinja нет ограничений, кроме возможностей самих хранилищ и уровня знаний исполнителя.
Что нужно знать, чтобы использовать dbt
Для анализа самих моделей достаточно знать SQL и обзорную документацию по работе с dbt. И если дата-инженеры внедрили фреймворк со всеми функциями, то аналитику кроме знаний SQL и работы с браузером ничего не потребуется. Он легко сможет пользоваться сервисами dbt, анализировать цикличный граф зависимости и смотреть код преобразования.
До знакомства с фреймворком я никогда не работал с Jinja, языком шаблонов, который применяется в dbt для реализации настроек моделей, обработки дополнительной функциональности SQL-кода. Разобраться помогла обширная документация и хорошее комьюнити: есть, например, русскоязычный канал в Telegram.
Структура проекта dbt
Проект состоит из директорий и файлов двух типов:
● модель (.sql) — единица трансформации, выраженная SELECT-запросом;
● файл конфигурации (.yml) — параметры, настройки, тесты, документация.
На базовом уровне работа строится следующим образом:
● пользователь готовит код моделей в любой удобной IDE;
● с помощью CLI вызывается запуск моделей, dbt компилирует код моделей в SQL;
● скомпилированный SQL-код исполняется в Хранилище в заданной последовательности (граф).
Модели — это гибрид SQL + Jinja, которые ограничены лишь объёмом хранилища и уровнем знаний пользователя.
В dbt применяется Jinja версии два. Сам язык имеет очень большую функциональность, ознакомится с ним подробнее можно в этой статье.
Как работать с dbt: установка, настройка, использование
Устанавливаем фреймворк
dbt поддерживает 4 варианта установки:
● pip;
● Docker;
● source.
Рассмотрим установку подробнее на примере pip.
Установка
- Открываем терминал.
- Запускаем команды:
- pip install dbt-core #Установка
последней версии; - pip install dbt-core==1.4.0
#Установка конкретной версии. - dbt —version #Проверка установленной
версии.


Для обновления можно использовать следующие команды:
● pip install —upgrade dbt-core #Установка последней версии;
● pip install —upgrade dbt-core==1.4.0 #Установка конкретной версии.
Установка пакетов платформ
Для работы с конкретными платформами необходимо установить пакет платформы, с которой вы планируете работать:
● pip install dbt-clickhouse #Установка последней версии
Проверка установленных пакетов
Выполняем команду dbt —version

Настройка проекта
Для начала работы настроим окружение взаимодействия с dbt, установив VS Code. Обязательно проверяем наличие установленного Git и Python 3.
Для удобства работы с фреймворком стоит рассмотреть установки и настройки дополнительных расширений для VS Code:
● vscode-dbt;
● dbt Power User:
Настроим параметры VS Code для работы с dbt. Открываем settings.json по пути File-Preferences-Settings.
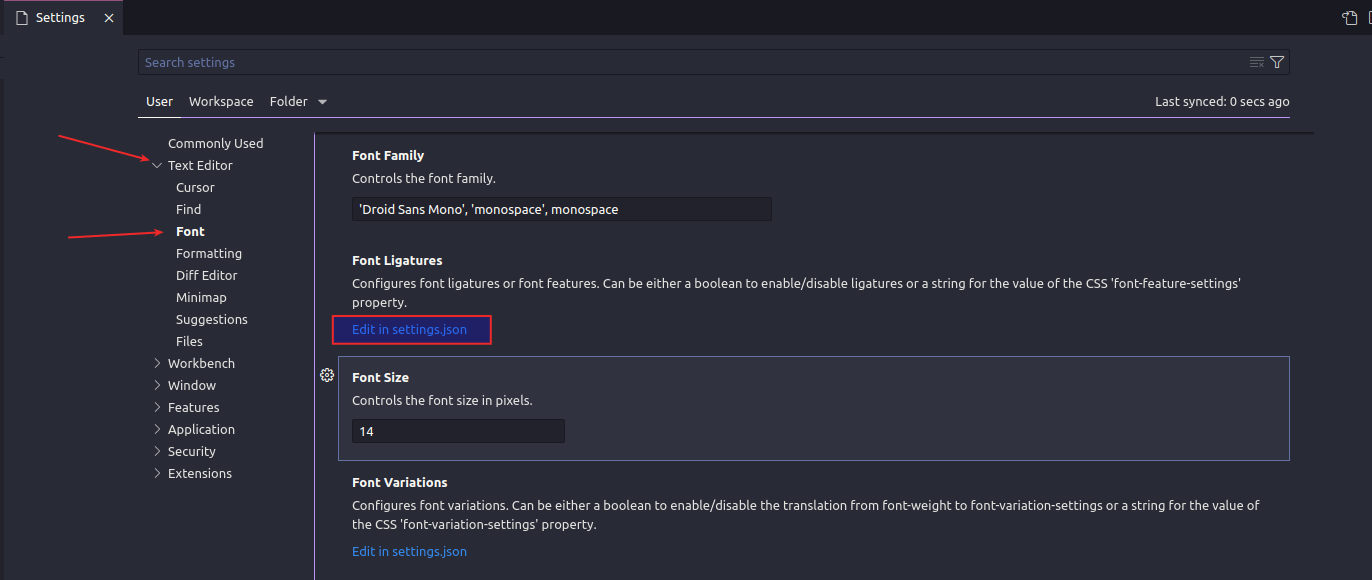
Добавляем настройки ассоциации файлов:
Закрываем файл.
Инициализация проекта
1. Создаем каталог проекта. К примеру, dbt_example.
2. Открываем терминал и переходим в каталог:

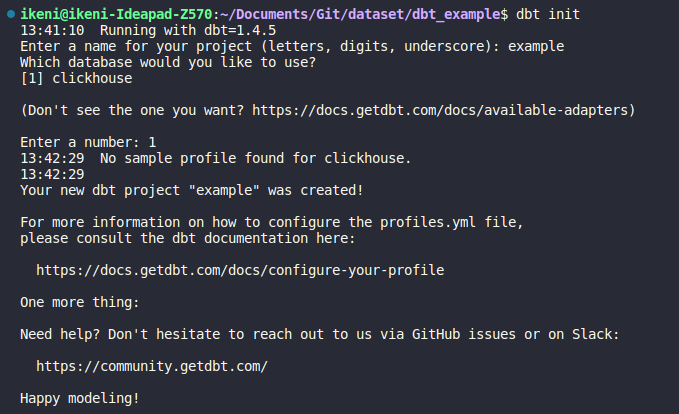
3. Инициализируем новый проект командой dbt init:

4. Указываем название нашего проекта: если мы уже установили платформу для взаимодействия, нам предложат выбрать из списка, после чего проект будет создан:
5. Типовая структура проекта:

6. Проверяем состояние модели командой dbt debug:
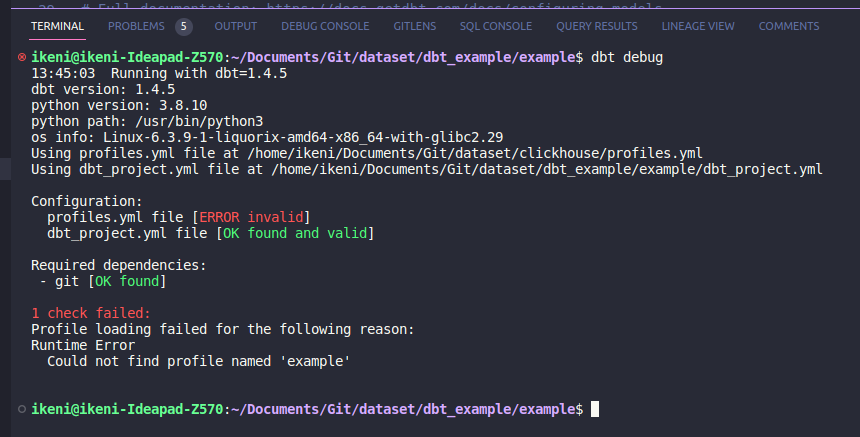
Готово — можем приступать к созданию модели.
О чем важно помнить при работе с dbt
● Основное — так как проект живой, нужно всегда следить за функциональностью, за обновлениями версий. Не всегда стоит использовать последнюю версию, но тестировать все изменения модели — важно.
● Помнить о том, что любая стандартизация и шаблонизация, с одной стороны, облегчает работу, а с другой — усложняет анализ. С помощью шаблонов мы можем любой SQL-код, который состоял из 3000 строк, сократить до условных 100, но нужно понять, как потом это всё прочитать.
● Поскольку инструмент гибкий и позволяет самостоятельно расширять функциональность, любые разработки придётся тестировать на работоспособность для каждой базы данных отдельно. В основном мы используем Postgres, Redshift, Spark, но также есть Greenplum, Clickhouse, MySQL, и синтаксис у всех отличается. Например, текущая версия адаптера для Clickhouse не поддерживает создание материализованных представлений.
● Расширение функциональности у dbt фактически безгранично, потому что ядро фреймворка сделано на Python. Если в команде есть разработчики Python, они смогут дописать любую функциональность.
Полезные ссылки и материалы
- DBT documentation — Introduction — официальная документация.
- What, exactly, is dbt? — обзорная статья одного из авторов dbt.
- Building a Mature Analytics Workflow — взгляд на будущее работы с данными и аналитику.
- Getting started with DBT tutorial — практика, пошаговые инструкции для самостоятельной работы.
- Jaffle shop — Github DBT Tutorial — Github, код учебного проекта.
- Hub.getdbt.com — открытая база готовых пакетов для dbt.
- Telegram-канал по dbt — здесь всегда можно почитать подробнее о фреймворке, задать вопрос, обсудить какие-то новости и проблемы.
В любом случае, dbt — лишь инструмент в руках дата-инженеров, которые могут построить структуру хранения моделей на свое усмотрение. При правильном использовании этот инструмент может сильно оптимизировать работу с данными, а значит — повысить эффективность всего бизнеса.

8К открытий17К показов
Раскрываем все карты: что делают RnD-специалисты на работе и как устроены исследования в RnD-отделе Ростелекома.

Рассказываем, откуда взялся термин DevOps, в чём заключается суть методологии, чем занимается DevOps-инженер и кому эта профессия точно не подойдёт.
Рассказываем о Karma Framework — инструменте, который позволяет команде эффективно работать по принципу самоорганизации
Потребность в специалистах по Data Office растёт. В статье рассказали, кто эти люди — и как устроена сфера в целом.