Зачем разработчику знать SQL, если есть NoSQL? Разбираемся на примерах
Зачем разработчику знать SQL, если есть NoSQL. Показываем основные отличия SQL и NoSQL. Рассматриваем пошаговую инструкцию и важные особенности ✔ Tproger

Ключевые отличия SQL и NoSQL
Структура данных: реляционные таблицы vs. Документо-ориентированные, графовые, ключ-значение базы
SQL — язык запросов, с помощью которого мы можем обращаться к реляционным базам данных и манипулировать ими. Они имеют строгую структуру и отношения, логика их схемы напоминает таблицу или несколько связанных таблиц.
Рассмотрим пример таблицы ниже:

Это таблица excel, в которую занесены данные о различных персонажах. В ней мы можем фильтровать данные, искать их, сортировать содержимое, писать значения с разными типами, обращаться к данным во внешних таблицах. При помощи запросов SQL возможно всё то же самое в реляционной базе.
Давайте создадим нашу таблицу при помощи SQL:
Командой CREATE TABLE создаём таблицу, которую называем «Персонажи». В скобках прописываем название столбцов, напротив указываем тип данных, который здесь будет храниться. Например, VARCHAR(50) — это текст до 50 символов, DATE — дата, INT — число. PRIMARY KEY — первичный ключ строки. Он нужен, чтобы у каждой строки таблицы был свой уникальный номер.
Далее заполним нашу таблицу при помощи команды INSERT INTO Персонажи VALUES:
Заполняем значениями в кавычках, через запятую. Запятые отделяют столбцы друг от друга.
А теперь добавим ещё одного персонажа и отфильтруем значения по столбцу «Фильм_Сериал»:
Команда INSERT INTO добавляет нового персонажа в уже существующую базу.
В скобках после INSERT INTO мы перечисляем столбцы, которые хотим заполнить. VALUES — значения для этих столбцов.
Эта команда выбирает все столбцы в таблице «Персонажи», проверяя, что новое значение добавилось.
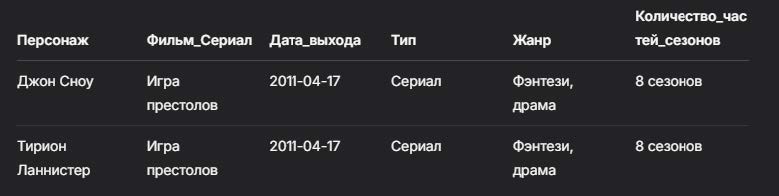
Далее проводим фильтрацию по сериалу: «Игра престолов»:
- SELECT — выбирает данные из столбцов.
- После SELECTпишем, какие именно столбцы хотим видеть (не всё, а только эти шесть).
- FROM Персонажи — указываем таблицу, из которой берём данные.
- WHERE Фильм_Сериал — выбираем столбец, по которому будем искать данные.
В результате получим вот такие данные:
NoSQL в сравнении с SQL не просто другой язык, а целая философия организации базы данных. Никаких строгих таблиц — всё зависит от того, с чем работаем. В NoSQL есть много видов данных, под каждый из них существуют свои системы управления базами данных (СУБД). Вот основные из них:
Документо-ориентированные базы (MongoDB): данные лежат в виде документов, похожих на JSON, но это не совсем он, а BSON. Различия кроются в том, что это его бинарная версия.
Пример:
Слева в кавычках мы пишем название наших полей, например, «Персонаж». Далее через двоеточие указываем значение (тоже в кавычках) и заканчиваем запись для поля запятой. Всё это внутри фигурных скобок.
Ключ-значение (Redis): это тип NoSQL баз данных, где информация хранится в виде пар «ключ-значение», как в словаре: ключ — уникальный идентификатор, значение — любые данные, связанные с ним. Например, запись Джона Сноу будет выглядеть так:
Внутри фигурных скобок прописываем ключ в кавычках. Далее через двоеточие пишем значение. Отделяем поля между собой при помощи запятой.
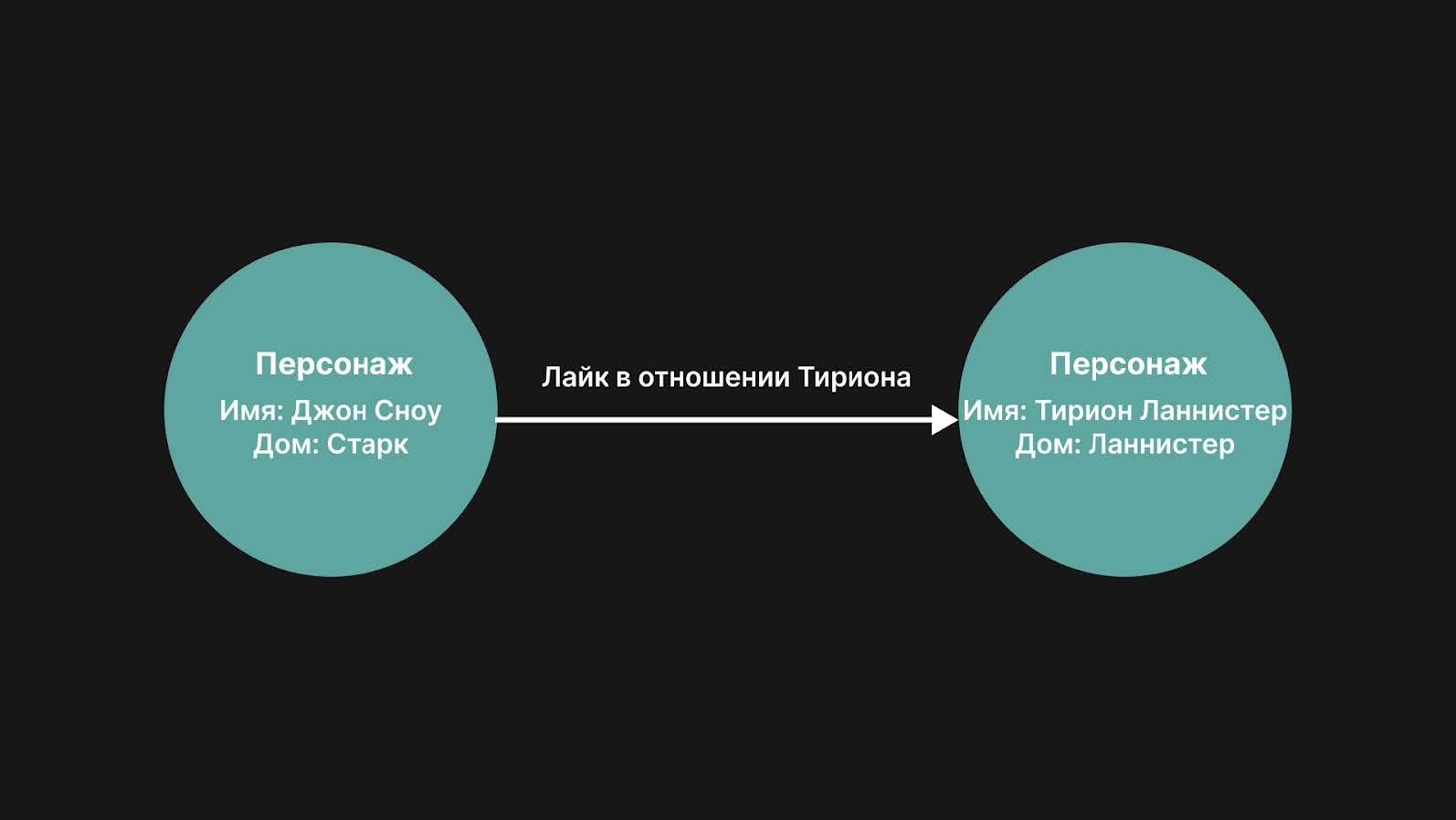
Графовые базы (Neo4j): здесь данные — это узлы.
CREATE (Джон:Персонаж {имя: "Джон Сноу", дом: "Старк"});
Создаётся узел с меткой Персонаж, который представляет Джона Сноу. Узел имеет два свойства: имя со значением «Джон Сноу» и дом со значением «Старк». Переменная Джон — временное имя для ссылки на узел.
CREATE (Тирион:Персонаж {имя: "Тирион Ланнистер", дом: "Ланнистер"});
Далее создаётся ещё один узел с меткой Персонаж, представляющий Тириона Ланнистера. У него тоже два свойства: имя — «Тирион Ланнистер» и дом — «Ланнистер». Переменная Тирион позволяет ссылаться на этот узел.
CREATE (Джон)-[:ЛАЙК]->(Тирион);
Затем появляется направленная связь (ребро) между узлами Джон и Тирион. Она имеет тип ЛАЙК и указывает, что Джон «лайкает» Тириона. Скобки () обозначают узлы, а [:ЛАЙК] со стрелкой -> показывает направление отношения.
Гибкость схемы SQL против NoSQL: строгая схема vs динамическая структура
Представьте, что у нас есть база данных с персонажами из фильмов и сериалов — огромная таблица на миллион строк. Теперь мы решили добавить в неё нестандартную запись: включить в список реальную историческую личность, а заодно создать новый столбец «факты», чтобы указать, чем личность запомнилась. Сделать это можно при помощи команды CREATE, но есть проблема.
Дело в том, что если мы создадим новый столбец в большой базе данных и запишем туда значение только для одного персонажа, то остальные строки в столбце для других примут значение null. И это не очень удобно, так как большое количество null усложняет запросы и может запутать разработчика при обработке данных.
В этом фундаментальное различие SQL и NoSQL. Первый плохо подходит для работы с неструктурированными данными.
В NoSQL мы можем при помощи MongoDB прописать значение только для одного персонажа, не трогая других:
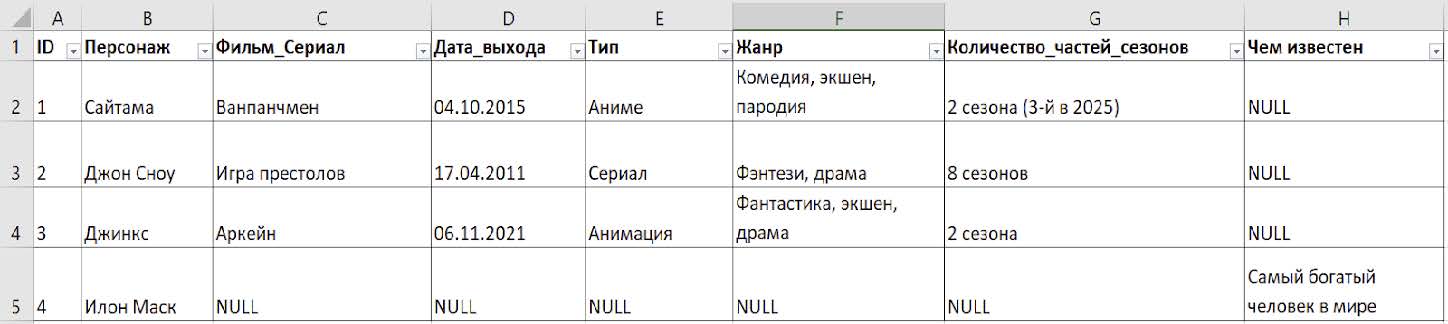
Сравните данные Илона Маска и Сайтамы, у них есть различия в схеме.
Для такой записи в SQL нам пришлось бы добавлять поле «Чем известен» для всех персонажей в базе. Другие бы тогда получили значение null:
Из-за строгой схемы надо заранее продумывать логику структуры. Если база данных уже большая и её логику надо поменять, это чревато неудобствами.
У NoSQL, в отличие от SQL, нет строгой схемы, благодаря этому он отлично подходит для работы с плохо структурированными данными.
Транзакции в SQL и NoSQL: ACID (SQL) vs. BASE (NoSQL)
Транзакция — набор тех операций, которые либо выполняются полностью, либо не выполняются совсем. Представим перевод денег: снимаем 500 рублей с нашего счёта и отправляем их на другой. Если что-то сломается на полпути, транзакция либо отменится, либо завершит оба шага. В базах данных транзакции нужны, чтобы данные оставались надёжными. Рассмотрим основные различия транзакций SQL и NoSQL.
ACID (SQL)
SQL-базы данных работают по принципу ACID-транзакций, что гарантирует стабильность и предсказуемость работы с данными. Этот набор правил включает атомарность, согласованность, изоляцию и долговечность.
Атомарность (Atomicity) — транзакция выполняется как единое целое. Если хоть одна операция внутри неё не удалась, всё отменяется. Например, если при переводе денег сервер внезапно отключился, система откатит изменения, и средства не исчезнут.
Согласованность (Consistency) — данные всегда соответствуют правилам базы. Если на счёте 80$, а мы пытаемся перевести 100$, система просто не даст выполнить такую операцию.
Изоляция (Isolation) — параллельные транзакции не мешают друг другу. Пока одна выполняется, другая видит только конечный результат. Например, если один процесс переводит 100$ со счёта A на счёт B, а другой в этот момент проверяет баланс, он увидит либо старое состояние, либо уже обновлённое, но никогда промежуточное.
Долговечность (Durability) — завершённая транзакция остаётся в базе навсегда, даже в случае сбоя. Если мы пополнили счёт на 100$, эта информация будет сохранена, независимо от того, что произойдёт с сервером после.
BASE (NoSQL)
BASE-модель, которую используют NoSQL-базы данных, строится на трех принципах: базовая доступность, мягкое состояние и конечная согласованность. В отличие от строгих ACID-правил, здесь делается упор на скорость и масштабируемость, даже если это временно снижает точность данных.
Базовая доступность (Basically Available) — система всегда отвечает на запросы, даже если часть данных ещё не синхронизирована. Например, ставя лайк, мы сразу видим его, даже если информация ещё не дошла до сервера.
Мягкое состояние (Soft State) — данные могут временно быть несогласованными. Ради высокой доступности система допускает, что информация изменяется без нашего участия. Например, когда у нового видео на YouTube лайков больше, чем просмотров — это результат того, что одни данные обновились быстрее других.
Конечная согласованность (Eventual Consistency) — если систему оставить в покое, она сама «додумает» и согласует данные между всеми узлами. Допустим, у поста 50 лайков, но у разных пользователей отображаются разные числа: кто-то видит 49, кто-то 53. Через некоторое время система синхронизируется, и у всех будет одинаковое значение.
BASE-жизнь — это про скорость и гибкость. Главное, чтобы данные в итоге сошлись, а не были идеальными в каждый момент времени.
Масштабируемость: вертикальное (SQL) vs горизонтальное (NoSQL) масштабирование
Вертикальное масштабирование (SQL)
Реляционные базы данных изначально проектировались для работы на одном сервере (или кластере серверов) с использованием строгой структуры данных (таблицы, строки, столбцы) и поддержки ACID-транзакций.
Если наше «железо» не справляется с обработкой реляционной базы, то проще его прокачать, например, установить больше памяти, либо купить новый сервер помощнее и перенести на него данные. При таком масштабировании мы как бы гонимся вверх, стараемся получить больше памяти и производительное «железо».
Конечно, можем купить второй сервер или кластер серверов и распределить на них часть нагрузки, но это будет сложно из-за архитектуры реляционных баз.
Горизонтальное масштабирование (NoSQL)
При горизонтальном масштабировании мы докупаем дополнительные сервера и распределяем между ними нагрузку. NoSQL базы данных изначально проектировались для работы на множестве серверов. Здесь не нужна строгая схема хранения данных, и они лучше оптимизированы для работы с большим объёмом информации.
Благодаря этому мы можем распределять нагрузку NoSQL среди множества серверов. Это значит, что если нам не хватает производительности, то можно просто докупить новые устройства.
Вертикальное масштабирование здесь тоже возможно, но оно часто дороже, хуже подходит для больших баз данных и, в целом, менее удобно из-за архитектуры NoSQL.
Первое и главное преимущество SQL — строгая структура данных и операций. У базы есть контракт, который ты обязан соблюдать при добавлении, изменении или запросе данных. Правило простое: «Либо всё, либо откат». Второе преимущество — мощный и популярный язык запросов. Сложные аналитические задачи ему по плечу. Уверен, реляционные БД будущего будут опираться на опыт SQL.
Строгая структура — одновременно и ограничение. Добавление полей или связей может стать проблемой при реализации на клиенте. Второй момент — горизонтальное масштабирование. Реляционные базы данных очень сложно масштабировать горизонтально. Ты не можешь просто подключить ещё один кластер и продолжать спокойно существовать. Есть ещё определённые проблемы с производительностью, если между объектами существует много связей.
Плюсы NoSQL в гибкости, лёгкости масштабирования, высокой производительности при больших нагрузках и разнообразии предметно-ориентированных решений. Например, Redis — для кеширования, Firebase — для реалтайм-обновлений и так далее. Структуру данных можно менять на лету, идеально для проектов с частыми изменениями структуры данных.
Минусы в том, что у многих NoSQL свои системы команд и запросов — их приходится учить. Также есть сложности с консистентностью данных.
Где использовать SQL и NoSQL
Сценарии, где SQL незаменим
SQL хорош там, где важны точность, структура и сложные взаимосвязи данных.
Финансовые и банковские системы
Здесь цена любой ошибки — чьи-то деньги, поэтому важна точность. Транзакции по стандарту ACID гарантируют, что деньги не потеряются при сбоях. Связь между счетами, клиентами и операциями проще строить через реляционные базы данных.
Примеры систем: PostgreSQL, Oracle Database, Microsoft SQL Server.
Аналитика и сложные запросы
В аналитике нужно регулярно вытаскивать данные из таблиц и строить зависимости. В SQL есть операторы JOIN, GROUP BY и оконные функции, которые решают задачи, наподобие расчёта среднего чека за квартал, в пару строк.
Примеры систем: MySQL, Snowflake, Google BigQuery.
Работа с отчётами и BI-системами
Данные для бизнеса — это таблицы, сводки, графики. SQL легко интегрируется с инструментами вроде Power BI или Tableau. Строгая схема помогает избежать путаницы в метриках.
Примеры систем: PostgreSQL, SQL Server, Redshift.
Логирование и аудит данных
В этой сфере важно понимать, кто, что и когда изменил. Реляционные базы фиксируют историю изменений с точными связями. Триггеры и индексы ускоряют поиск по логам.
Примеры систем: SQLite, PostgreSQL, MariaDB.
Управление складом и инвентаризацией
Данные о товарах, поставках и остатках связаны между собой. Реляционная модель идеально описывает такие структуры. Запросы вроде «что заканчивается на складе» пишутся быстро и понятно.
Примеры систем: MySQL, Oracle Database.
Где NoSQL работает лучше?
NoSQL — это про скорость, гибкость и масштабирование. Там, где SQL требует строгих рамок, NoSQL даёт свободу и справляется с хаосом больших данных. Вот сценарии, где он выигрывает:
Высоконагруженные системы и real-time сервисы
Допустим, у нас стриминговый сервис, здесь миллионы запросов в секунду, а задержки недопустимы. Горизонтальное масштабирование размазывает нагрузку по серверам. Данные отправляются быстро, без сложных JOIN’ов.
Примеры систем: Cassandra, MongoDB, DynamoDB.
Гибкие структуры данных и работа с JSON
В реальной жизни данные далеко не всегда приходят в виде строгой схемы. У кого-то может быть указан email, у кого-то его нет, но есть телефон. Поэтому для работы с такой информацией лучше подходят документо-ориентированные базы, которые хранят JSON или BSON без строгой структуры. Если мы добавим новое поле, такая база не сломается.
Примеры систем: MongoDB, CouchDB, Firebase.
Графовые базы для рекомендаций и соцсетей
Иногда связи между объектами важнее самих данных. Графовые базы строят сети вроде «друзья друзей» или «похожие товары» за доли секунды. SQL для этой задачи медленнее.
Примеры систем: Neo4j, ArangoDB, OrientDB.
Почему SQL и NoSQL нужно знать вместе?
SQL даёт точность и структуру, данные в NoSQL — это про скорость и гибкость. В реальных проектах их часто используют вместе, чтобы закрыть слабые места друг друга.
Примеры гибридных архитектур: SQL и NoSQL в одном проекте
Работа с каталогами товаров, запросами и системой рекомендаций в интернет-магазинах
Представим интернет-магазин: каталог товаров и заказы лежат в SQL — там важны связи и точность. А рекомендации «похожие товары» или история просмотров — в NoSQL, чтобы быстро отдавать данные и не мучиться со схемой.
Например, PostgreSQL хранит данные о клиентах и транзакциях, а MongoDB — отзывы и пользовательские профили. Всё в одном проекте, каждый инструмент на своём месте.
Кеширование запросов с помощью Redis и SQL
SQL силён в сложных запросах, но в больших базах может тормозить. А если у нас есть операция, которая предполагает повторный подсчёт? Это будет долго. Здесь выручает Redis, NoSQL-база типа «ключ-значение».
Представим аналитику продаж: SQL вычисляет «топ-10 товаров за месяц» Готовый список сохраняем в Redis. Теперь, когда нам нужен этот топ, данные тянутся из Redis за миллисекунды, нам не надо заново проводить вычисления в SQL.
Использование NoSQL для логов, SQL — для отчётности
Логи — это поток данных: миллионы записей, структура не всегда предсказуема. NoSQL вроде Cassandra или MongoDB «переваривает» их без проблем благодаря скорости записи и горизонтальному масштабированию. А потом из этого хаоса SQL, например, MySQL, вытягивает нужное для отчётов: «сколько ошибок за день» или «кто чаще ломает систему». NoSQL собирает сырые данные, SQL их структурирует.
Стоит ли учить SQL? Мнение экспертов
Мы решили спросить у экспертов, что бы они посоветовали молодым разработчикам изучать в первую очередь, SQL или NoSQL. Делимся мнениями:
Мой совет — начинайте с SQL. Вот почему:
1) База знаний. SQL учит вас основам работы с данными — как их хранить и извлекать. Это фундамент, который пригодится в любом проекте, даже если вы потом перейдёте на NoSQL.
2) Широкое применение. SQL встречается повсюду — от стартапов до банков. Знание SQL сразу даёт вам больше шансов найти работу или понять, что происходит в существующем проекте.
Но это не значит, что NoSQL можно просто игнорировать. После SQL я бы рекомендовал изучить хотя бы одну NoSQL базу — например, Redis или MongoDB. Современные проекты часто требуют гибкости и скорости, которые дают NoSQL системы. Зная обе технологии, вы сможете выбирать инструмент под задачу, а не подстраиваться под то, что знаете.
Первым делом нужно освоить SQL. Это фундаментальный навык, который необходим в любой сфере, связанной с данными. Знание реляционных баз помогает понять, как правильно структурировать данные, оптимизировать запросы и обеспечивать их целостность. Независимо от того, с какой технологией будет иметь дело разработчик в будущем, понимание SQL даст ему прочную основу.
После освоения SQL я бы рекомендовал изучить и NoSQL. Важно понимать, какие задачи он решает, какие бывают типы нереляционных баз и в каких случаях их применение оправдано. Даже если специалист в своей работе чаще использует SQL, знание NoSQL поможет ему грамотно проектировать архитектуру и принимать взвешенные технологические решения.
Не существует как такового единого NoSQL как системы управления базы данных, зачастую это очень сильно различающийся набор решений, поэтому стоит начать с SQL, для разных СУБД он довольно мало отличается синтаксически. SQL — это фундамент. NoSQL даст более полное понимание того, как можно работать с базами данных. Можно отметить, что в SQL добавляются фичи NoSql и наоборот.
SQL и NoSQL желательно знать вместе. Как видно исходя из комментариев экспертов и примеров, SQL — первый ключ к базам данных, NoSQL — второй, для более сложных сценариев.










![Обложка: Как стать аналитиком данных за 6–12 месяцев [гайд]](https://media.tproger.ru/uploads/2025/12/1c7c4818-f579-4330-b4fe-56704d1972e0.jpg)

