


Знать Scala — желательно, Spark — обязательно. Что нужно уметь начинающим и опытным дата-инженерам: исследование Яндекс Практикума
Яндекс Практикум изучил самые востребованные навыки для junior, middle и senior дата-инженеров. Разбираемся, где и как себя прокачивать, чтобы войти в профессию и расти в ней.
906 открытий19К показов
Инженер данных — направление, которое подразумевает владение множеством инструментов. Поэтому один из главных вопросов — какие из них осваивать прежде всего. Продуктовый исследователь Русана Талыбова вместе с командой Яндекс Практикума изучила около тысячи вакансий для начинающих и опытных дата-инженеров на hh.ru, провела серию интервью с нанимающими менеджерами и специалистами разных грейдов и составила список самых востребованных навыков в этом направлении. Разбираемся, где и как себя прокачивать, чтобы войти в профессию и расти в ней.
Потребность в дата-инженерах ежегодно растёт: согласно данным Indeed, число вакансий для них увеличилось на 400% за пять лет. Компании собирают больше данных, чем когда-либо прежде, оттого им нужны специалисты, способные управлять этой растущей махиной: разрабатывать хранилища и витрины, проектировать пайплайны, заниматься сбором, очисткой и структурированием данных и так далее.
В IT-сообществе справедливо вырос интерес к профессии. Сегодня в дата-инженеры чаще всего переходят разработчики и дата-аналитики. Если вы рассматриваете для себя это направление, то вам будут полезны выводы исследования.
Главные навыки начинающего дата-инженера
Основное требование к джуну — специалисту без опыта работы — знать Python и SQL. Те, кто переходит в направление из других специальностей, как правило уже владеют либо обоими инструментами, либо одним из них, плюс знают что-то ещё дополнительное — например, умеют работать с дашбордами.
Именно с Python и SQL мы в первую очередь знакомим студентов, которые приходят в Яндекс Практикум осваивать профессию инженера данных с нуля. А более опытным – помогаем систематизировать и углубить знания.
На третьем месте по востребованности — английский язык (встречается в 24% вакансий для кандидатов без опыта). В крупных компаниях с международными командами обязательно знание письменного и разговорного английского.
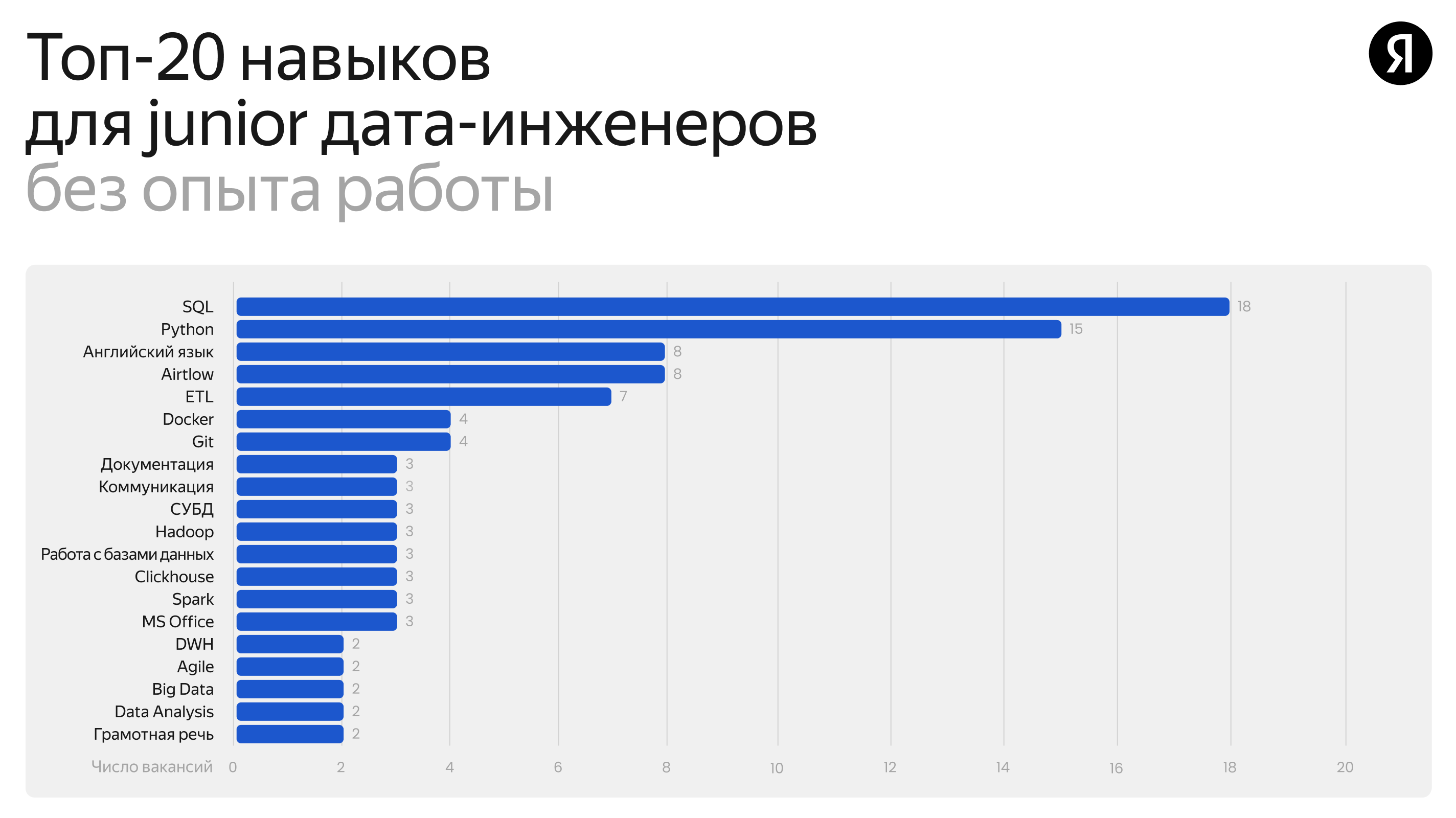
В минимальный скиллсет опытного джуна и мидла дата-инженера в зависимости от компании и опыта, входят следующие инструменты:
— Apache Hadoop
— Apache Spark
— Apache Airflow
— Greenplum
— HDFS
— ETL/ELT инструменты в целом
— DWH
Что добавляется к джунам+/мидлам
Зачастую рост в грейде не связан с увеличением технологий в стеке. Через серию интервью с дата-инженерами и анализ разницы позиций в вакансиях не обнаружено чётких отличий в инструментарии и спектре задач для джунов, мидлов, сеньоров — они универсальны для всех инженеров данных. По мере того как специалист начинает выполнять всё более сложные и многоступенчатые задачи, в его стеке могут появляться новые инструменты, но это сильно зависит от сферы, в которой он работает. В компаниях, где основной упор не на диджитал-продуктах и нет IT-специфики, что-то могут начать использовать позднее.
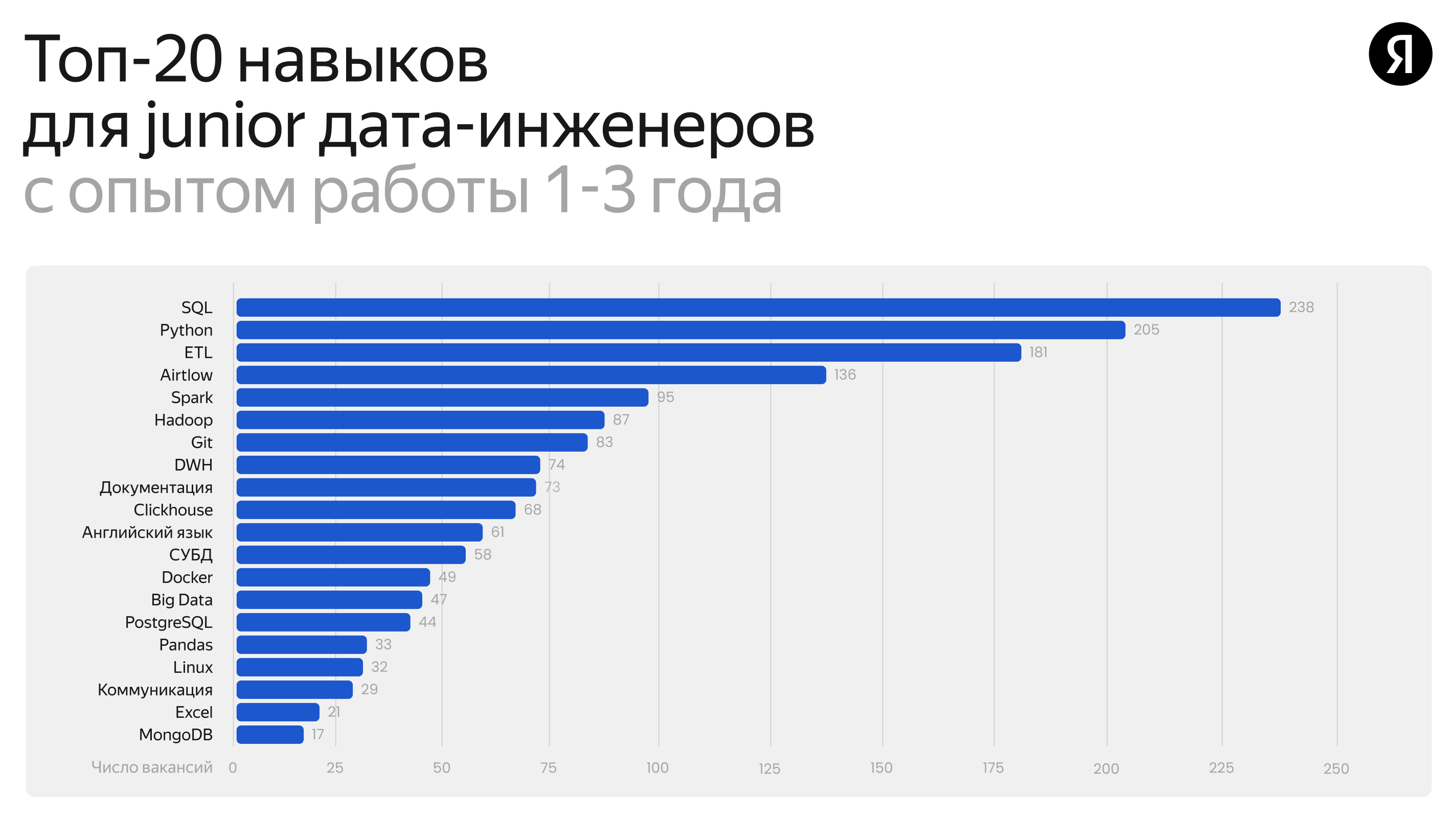
Среди новых востребованных навыков для джунов+ и мидлов — это язык программирования Scala и фреймворк Spark, нужные для работы с большими данными, которых сейчас много в разных компаниях. Умение работать со Scala существенно повышает шансы на трудоустройство. Scala пока ещё нечасто встречается в описаниях вакансий, но уже на слуху в индустрии. Даже если язык не упомянут в требованиях к кандидату, вопрос о нём может возникнуть на собеседовании и стать веским преимуществом для работодателя. А Spark часто называют необходимым для дата-инженера начальных грейдов.
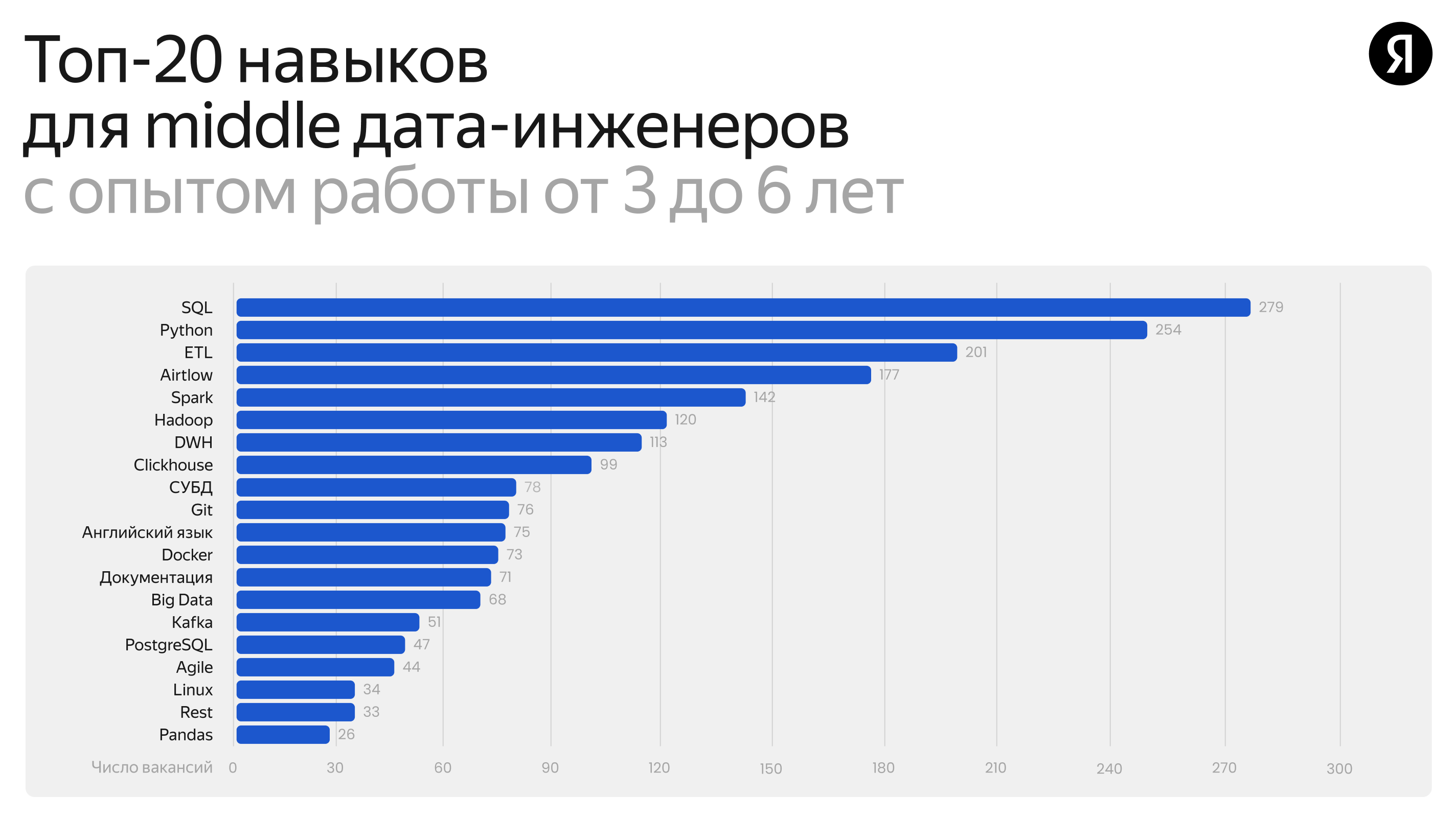
Главные навыки дата-инженера уровня мидл
В список навыков для опытных мидлов добавляются два навыка:
- Автоматизация и Python
- MongoDB как новый источник данных.
Главные навыки senior дата-инженера
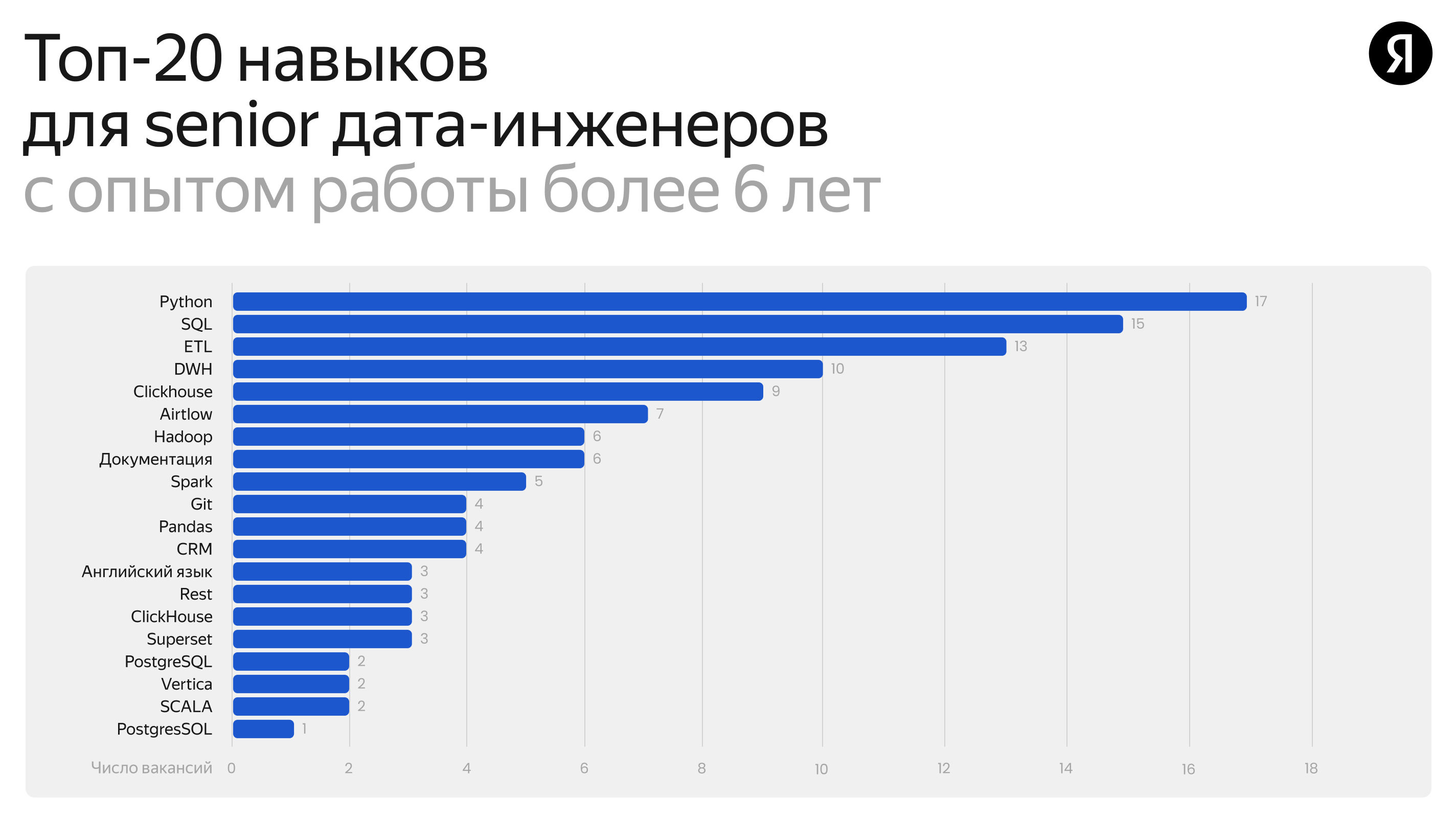
Что нужно знать, чтобы расти в грейде
Осваивать дополнительные инструменты можно самостоятельно или на специализированных курсах. Например, в Яндекс Практикуме программы для инженеров данных дополняются разделами об инструментах, набирающих популярность, а доступ к новым материалам получают в том числе те, кто уже завершил обучение.
В дата-инжиниринге, как и в других IT-направлениях, специалисты растут в двух вариациях:
1. Техническая. Специалист может выполнять более сложные задачи с имеющимися инструментами в минимальном стеке (например, более глубокое погружение в Python, Hadoop, Spark, др.). Кроме того, можно начать изучать навык, который даёт преимущество на рынке, или технолугию, которая сейчас развивается в сфере (например, Apache Kafka и другие инструменты, необходимые для работы со стримингом).
2. Софтовая. Предполагает развитие софт-скиллов — организационные скиллы, и как отдельный стрим — менеджмент для сеньорных дата-инженеров.
Скиллсеты дата-инженеров включают множество инструментов, и уверенно овладеть всеми технологиями, с которыми можно столкнуться, стало слишком сложно. Полезно представлять, на каком стеке работают компании, куда вы хотели бы устроиться и какие задачи предстоит выполнять чаще всего.
Сегодня дата-инженеры регулярно сталкиваются с потоковой и пакетной обработкой данных. Это два больших направления по работе с информацией, и каждое из них включает свой набор инструментов.
Пакетная обработка данных — то, с чего начинался дата-инжиниринг. При такой обработке изменения накапливаются на источнике и затем одновременно (пакетом) отправляются в аналитическую систему — например, раз в час или день. Что нужно знать для того, чтобы выполнять задачи в этом классическом подходе:
- SQL и классические реляционные СУБД — PostgreSQL, Oracle, MySQL и так далее. Список самых популярных баз данных можно отслеживать здесь. Кроме того, при работе с базами важно различать транзакционную (OLTP, точечная интенсивная модификация записей) и аналитическую (OLAP, обработка и анализ больших массивов записей) работу с данными.
- Также есть NoSQL и NewSQL — виды СУБД, которые отличаются от классических (документоориентированные, графовые, key-value и так далее).
- Инструменты хранения и обработки данных, которые включают поддержку параллельной обработки. Для этих процессов используются Hadoop, различные MPP-СУБД, а также Spark — открытый фреймворк для распределённой обработки неструктурированных и слабоструктурированных данных.
Второе направление — это стриминг (realtime streaming pipeline), который позволяет обрабатывать и анализировать потоки данных в режиме реального времени. Потоковая обработка данных — актуальный тренд в аналитике. Здесь совершенно другие принципы и мировоззрение. Технологии: NiFi, Kafka Streams, Spark Streaming, Flink.
Кроме перечисленного дата-инженеру, впрочем, как и любому человеку, который имеет дело с данными, важно уверенно владеть командной строкой Linux.
Дата-инженеру неизбежно придётся иметь дело с облачной архитектурой. Работа с инфраструктурой отличается от компании к компании, где-то используют решения, поставляемые облачными вендорами, — например, dataproc/data vault в Yandex Cloud. Где-то разворачивают opensource ПО или ПО сторонних вендоров в облаке или своих дата-центрах (дистрибутив Arenadata, Postgres Pro и другие). Некоторые международные компании всё ещё пользуются западными вендорами ПО и облачными провайдерами (Databricks, Cloudera, Snowflake; AWS, GCP). Какое решение вам попадётся, сильно зависит от компании, но переход между большинством вендоров достаточно прямолинейный: принципы в основе (да и технологии, тот же Postgres (-> Greenplum, Vertica, RedShift/Aurora), Hadoop) у многих одни и те же.
Софт-скиллы нужны не только тимлиду и менеджеру
Развитие софт-скиллов — это не только способ вырасти в тимлида, менеджера, организатора процесса. Мягкие навыки нужны для развития и в том случае, если специалист выбирает углубление в техническую сторону.
Уже в скиллсете джуна указано такое качество, как умение вести коммуникацию. Ведь без навыка запрашивать и получать обратную связь у него не получится освоиться в профессии и расти в грейде. Некоторые компании предпочитают организовывать работу так, чтобы специалист не просто закрывал задачи в Jira, а решал бизнес-задачи. Он должен понимать свою роль в компании, знать, куда движется команда и что за продукт она делает. Умение выполнять работу, исходя из бизнес-процессов компании, может быть критичным требованием для сотрудника любого грейда, от джуна до тимлида.

906 открытий19К показов
Инструменты DevOps, которые упрощают рабочие процессы и ускоряют труд инженеров. Топ-10 популярных платформ разного направления.

Big Data в 2025. Показываем основные технологии работы с большими данными. Рассматриваем пошаговую инструкцию ✔ Tproger

Microsoft сделала ИИ-ассистентов обязательными: теперь использование Copilot влияет на аттестацию и входит в систему оценки сотрудников

Microsoft представила Muse — ИИ, который генерирует графику, предсказывает действия игроков и тестирует игры. Разработчики опасаются сокращения рабочих мест