


Самые популярные книги по версии Stack Overflow — разработчик рассказал о создании удобного сервиса и поделился месячным отчётом

7К открытий8К показов

Пользователь ресурса freeCodeCamp Влад Ветцель решил выяснить, как найти «свою» книгу по программированию.
Свободное время разработчика ограничено, а для чтения его нужно много. Поэтому очень важно выбрать хорошую книгу, после прочтения которой не возникнет ощущения потерянного времени.
К счастью, Stack Exchange (родительская компания Stack Overflow) опубликовала дамп своей базы данных, которым и воспользовался Ветцель. Он запустил сервис dev-books.com, который позволяет изучить все собранные и отсортированные им данные о книгах, когда-либо упомянутых на Stack Overflow. Сайт уже посетило более 100 000 человек.
Кроме того, Влад поделился историей создания этого сервиса. Передаём ему слово.
Рассказывает Влад Ветцель
Получение и импорт данных
Я взял данные Stack Exchange из archive.org.
С самого начала было ясно, что нельзя выложить XML-файл размером 48 ГБ в новую базу данных (PostgreSQL), используя популярные методы, такие как myxml := pg_read_file('path/to/my_file.xml'), потому что на моем сервере не было 48 ГБ ОЗУ. Поэтому я решил использовать парсер SAX.
Все значения хранились в тегах <row>, так что для парсинга я использовал скрипт на Python:
После трех дней загрузки (за это время загрузилась почти половина XML), я понял, что допустил ошибку: атрибут ParentID на самом деле должен был быть задан как ParentId.
Ждать еще неделю мне не хотелось, и я перешел с AMD E-350 (2×1.35GHz) на Intel G2020 (2×2.90GHz). Но и это не ускорило процесс.
Следующим решением стала пакетная вставка:
StringIO позволяет использовать переменную вместо файла для обработки функции copy_from, которая использует COPY. Таким образом, весь процесс импорта данных занял всего одну ночь.
После этого я занялся созданием индексов. Обычно индексы GiST медленнее, чем GIN, но они занимают меньше места. Поэтому я решил использовать GiST. На следующий день у меня был индекс объёмом 70 ГБ.
Когда я запустил пару тестовых запросов, я понял, что для их обработки нужно слишком много времени. Причина была в чтении с диска, и тут меня выручил новый SSD на 120 ГБ.
Я создал новый кластер PostgreSQL:
Затем я позаботился о том, чтобы скорректировать файл конфигурации (я использовал Manjaro OS):
Я перезагрузил конфиг и запустил PostgreSQL:
На этот раз для импорта потребовалась пара часов, но я использовал GIN. Индексы заняли 20 ГБ пространства на SSD, а выполнение простых запросов занимало меньше минуты.
Извлечение книг из базы данных
Когда мои данные, наконец, были импортированы, я начал искать сообщения, в которых упоминались книги, а затем скопировал их в отдельную SQL-таблицу:
Следующим шагом нужно было найти все гиперссылки:
Тут я понял, что StackOverflow проксирует все ссылки так: rads.stackowerflow.com/[$isbn]/
Я создал еще одну таблицу со всеми постами, содержащими ссылки:
Все номера ISBN я извлёк при помощи регулярного выражения. Я поместил теги Stack Overflow в другую таблицу через regexp_split_to_table.
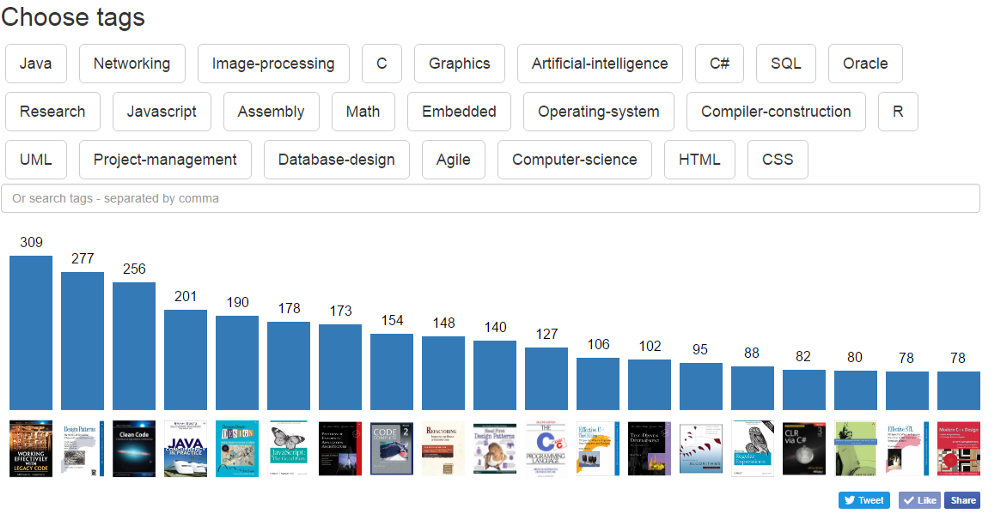
Как только самые популярные теги были извлечены и подсчитаны, топ-20 книг по всем тегам почти совпадал. Поэтому я решил улучшить систему рейтинга.
Идея заключалась в том, чтобы брать 20 самых популярных книг для каждого тега и исключать книги, которые уже были обработаны.
Поскольку это была «разовая» работа, я решил использовать массивы PostgreSQL. Примерный план создания запроса:
Создание веб-приложения
Поскольку я не веб-разработчик и, конечно, не эксперт по пользовательским интерфейсам, я решил создать простое одностраничное приложение, основанное на Bootstrap.
Я создал опцию «Поиск по тегу» и извлёк самые популярные теги, чтобы сделать результаты поиска кликабельными.
Для визуализации результатов поиска я использовал столбчатую диаграмму. Сперва я попробовал Hightcharts и D3, но у них были проблемы с отзывчивостью и настройкой, поэтому я создал свою отзывчивую диаграмму на основе SVG:
Заключение
Этот сервис весьма полезен для людей, у которых нет времени изучать огромные списки книг о программировании, особенно учитывая их разнонаправленность, а поиск по тегам делает работу с проектом очень быстрой и удобной. Автор обещает опубликовать полный отчет в конце марта.
Обновление 25.03: Автор опубликовал полный отчёт из Google Analytics и Amazon вместе со своей историей. Слово Владу.
Как сайт приносит прибыль
Для этого проекта я выбрал партнерскую программу Amazon, потому что Amazon — это самый большой известный мне книжный магазин. Регистрация учетной записи была довольно простой, поэтому я получил свой тег в партнерской программе для использования в ссылках на моем веб-сайте менее чем за час.
Начальный запуск
После запуска я разместил ссылку на dev-books.com на сайтах Hacker News и Reddit, пытаясь привлечь внимание некоторых разработчиков к моему проекту.
К сожалению, это не привлекло широкой аудитории, на которую я надеялся. Но я начал получать отзывы, исправил некоторые ошибки и получил предложения о том, как продвинуть мой проект.
В конце дня я получил сообщение от преподавателя freeCodeCamp Куинси Ларсона. Он предложил мне написать рассказ о моем проекте и о его создании, чтобы сделать его более доступным для людей.
Прорыв
Я прочитал статью Куинси Ларсона и нашел очень полезный инструмент для создания заголовков, Headline Analyzer. Я проверил заголовок, который использовал для своих постов, и получил довольно низкую оценку. Я улучшил его для повторной отправки на мой сайт.
Довольно скоро я набрал 65 очков и опубликовал свежий заголовок для Hacker News и Reddit.
На этот раз, по данным Google Analytics, было зафиксировано более 750 одновременных посетителей в течение нескольких часов подряд, а мой пост в Hacker News был в топе.
На следующий день я узнал, что у dev-books.com более 5000 репостов на Facebook.
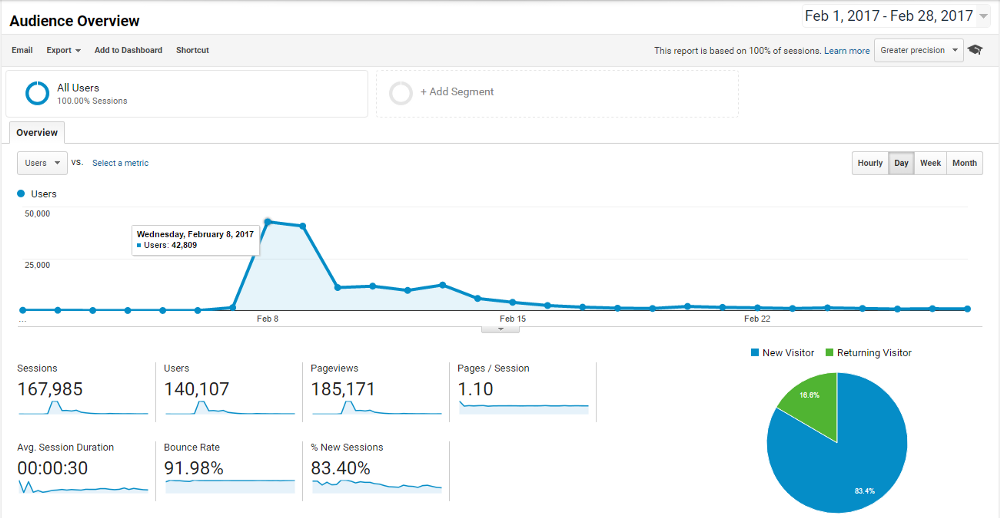
Геолокация
На следующий день я создал отчет по геолокации в Google Analytics и выяснил, что довольно много трафика идет из Азии и Европы, в особенности из России.
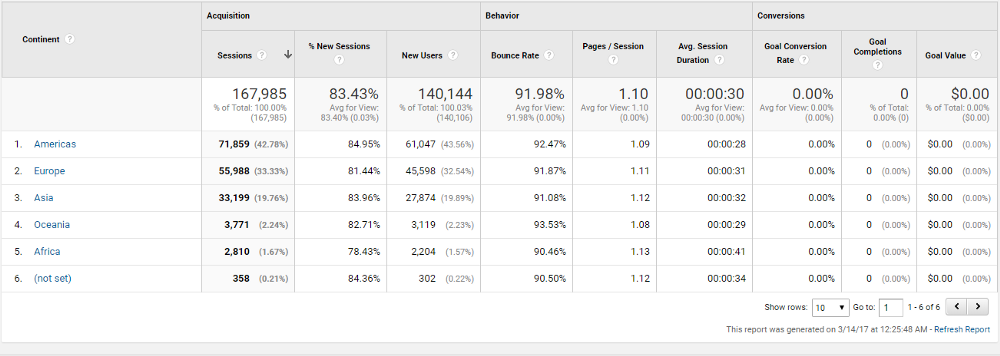
Мои азиатские и европейские посетители были вынуждены ожидать заказы из США. Чтобы избежать этого ожидания, я создал партнерские аккаунты на amazon.co.uk, amazon.de и amazon.fr. Из-за этой проблемы я потерял несколько заказов.
В ту же ночь мои посетители начали получать ссылки на ближайший магазин.
Самая интересная часть
На приведенных ниже рисунках вы можете увидеть статистику Amazon.com за февраль 2017 года. Из всего европейского кластера Amazon я получил чуть больше 250 долларов. Возможно, было бы больше, если бы я сделал ссылки на основе геолокации с самого начала.
Мой заработок за февраль: $2534,40.
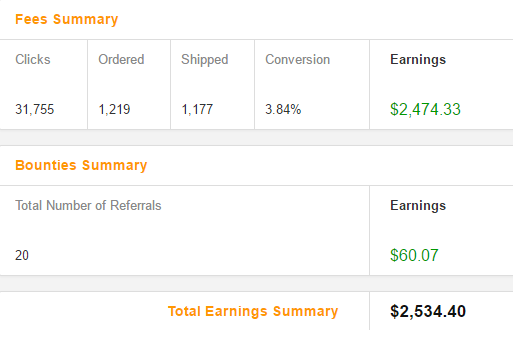
Доволен ли я результатом? Абсолютно.
Dev-books.com по-прежнему работает и продолжает получать заказы. За полтора месяца с момента запуска сервис принес мне более 3000 долларов.

7К открытий8К показов

Рассказываем, как встроить распознавание паспортов РФ, стран СНГ и других удостоверений личности, а также банковских карт и других объектов прямо в браузер.

Управляющие конструкции в программировании. Показываем, как работают if, else, switch, for, while. Рассматриваем пошаговую инструкцию и практические примеры ✔ Tproger

Microsoft запустил бесплатный практический курс по протоколу Model Context Protocol (MCP) с примерами на Python, C#, Java и TypeScript для разработки LLM-приложений и серверов MCP.

Авито проводит стажировку для аналитиков: присоединиться к ней могут студенты старших курсов и выпускники. Это возможность сделать первые шаги в карьере, получить опыт работы в крупной IT-компании и поработать с лучшими профессионалами на рынке. Рассказываем, какие этапы отбора надо пройти, чтобы попасть на программу, — а бонусом делимся советами от бывших стажёров и экспертов, которые общаются с потенциальными кандидатами.