


Практика Data Science: где искать датасеты и что с ними делать — отвечают эксперты

Начинающие специалисты в Data Science порой не знают, где искать датасеты и что с ними делать. Узнали у экспертов, что они могут посоветовать.
13К открытий15К показов
В процессе изучения Data Science важна практика, для которой нужны данные. Узнаём у экспертов, где эти данные брать и что с ними делать.

Сергей Афанасьев
исполнительный директор, начальник управления статистического анализа «Ренессанс Кредит»
Для изучения методов машинного обучения доступно большое количество материалов: книги, курсы, статьи, видеолекции, конференции и т. д.
Многие библиотеки Python содержат в себе наборы данных, на которых можно практиковаться начинающим датасаентистам. Например, библиотека sklearn.datasets содержит 26 наборов данных для новичков: предсказание видов ириса, предсказание цен на жилье в Бостоне, пассажиры Титаника и другие. Фреймворк Keras содержит набор рукописных цифр MNIST, на котором можно изучать алгоритмы для работы с изображениями.
Во многих соревнованиях по машинному обучению разрешается использовать выложенные в открытый доступ датасеты — для обучения, научных исследований и т. п. На самой популярной соревновательной площадке Kaggle есть отдельный раздел с датасетами на самые разные тематики — от кредитного скоринга до распространения коронавируса. Кроме табличных структурированных данных есть также наборы текстов и изображений, на которых можно обучать глубокие нейронные сети.
Для работы с изображениями самыми известными открытыми базами данных являются ImageNet и CIFAR. Для работы с текстами среди популярных датасетов можно отметить: IMDB dataset of 50k movie reviews, Wikipedia dataset, SMS spam collection dataset, Twitter sentiment analysis dataset и другие.
Помимо известных баз данных на различных интернет-ресурсах можно найти подборки датасетов на самые разные узкоспециализированные тематики: данные смертей и сражений из игры престолов, глобальная база данных терроризма, данные для распознавания пола по голосу, данные о студенческом потреблении алкоголя, рентгенография грудной клетки (пневмония), датасет с обзорами вин, данные рейтингов шоколадных батончиков, датасет с данными звуков сердцебиения, база данных рекомендаций аниме, датасет с данными FIFA-19 и многое другое.

Алексей Найдёнов
заместитель руководителя отдела анализа данных хостинг-провайдера REG.RU
Из открытых наборов данных можно выделить три группы. Первая — традиционные, которые используются для исследования статистических методов на практике. Такие наборы включены в некоторые фреймворки по машинному обучению, например scikit-learn.
Вторая группа — уже ставшие классическими наборы данных для сравнения SOTA-методов и получения предобученных моделей на практике. Сюда можно отнести Open Images Dataset для классификации моделей или Netflix Prize data для рекомендаций.
В третью группу входят датасеты на Kaggle — собранные большими компаниями или просто любителями и предоставленные в открытый доступ. Здесь можно найти данные на любой вкус и цвет. Также стоит упомянуть основной портал открытых данных в России data.gov.ru, на котором всё сложно структурировано, но максимально приближено к «реальной жизни».
Что с ними можно делать? Очевидно, всё, что угодно. Нужно определить цель анализа, чтобы получить какой-то профит.
Например:
- в исследовательском анализе (EDA) акцент больше идёт на визуализацию и описание данных;
- в статистическом анализе, например сравнении групп, чаще требуется применение статистических критериев;
- в прогнозном анализе уже необходимы навыки построения моделей и их интерпретации.

Николай Бурныков
системный архитектор Orange Business Services Россия и СНГ
Площадка Kaggle предоставляет несколько соревнований для обучения и совершенствования навыков начинающих специалистов по анализу данных. Например это соревнование, где нужно предсказать стоимость дома, основываясь на данных, содержащих 79 хорошо описанных признаков. В этом соревновании требуется применить навыки выделения новых признаков в данных (feature engineering) и работы с алгоритмами градиентного бустинга. Площадка предоставляет все необходимые наборы данных для практики, и, более того, предоставляет доступ к множеству опубликованных решений в формате IPython Notebook с подробными пошаговыми описаниями манипуляций с данными. Если этого недостаточно, то всегда можно задать вопрос в разделе дискуссий. Таким образом начинающий специалист получает практически всё, что необходимо для развития своих навыков в области Data Science.

Денис Голубцов
директор по развитию акселератора таргетированных продаж Selvery
Если мы говорим о Data Science, то мы говорим о репрезентативных выборках в огромных массивах данных. О миллиардах, сотнях миллиардов единиц релевантной информации. Такие данные сегодня можно искать в самых разных источниках. Во-первых, можно скачать уже готовый датасет в соответствии с темой своего исследования. Visual Genome, к примеру, позволяет выбирать датасеты из достаточно большой базы, и это не единственный пример.
Во-вторых, готовый набор данных легко получить от крупных коммерческих структур вроде «Сбербанка» или «Газпрома». Компании часто представляют датасеты для их обработки на хакатонах или ML-конкурсах. Кстати, там же часто можно найти себе и работу. Заходите на какой-нибудь Kaggle и следите за расписанием мероприятий.
Наконец, проще всего массивы можно найти там, где их хранят — на государственных сайтах вроде data.gov.ru, data.mos.ru или того же Росстата. А вот что с этой информацией делать — уже вопрос, может быть, даже философский. Сегодня найти большой объём информации — не проблема, а значит, перед тем, как искать датасет, нужно чётко определить цель своих изысканий.

Михаил Сеткин
вице-президент «Райффайзенбанка»
В зависимости от целей, которые перед собой ставят начинающие специалисты, датасеты могут различаться.
В случае, если мы говорим про узкоспециализированные задачи, требующие профильной подготовки (биоинформатика, астрофизика и т. д.), вокруг таких областей как правило существуют достаточно компактные сообщества, и специалистам скорее всего стоит искать ответы внутри таких сообществ.
Когда же мы говорим про задачи, не требующие от начинающих специалистов предварительной углублённой подготовки, и позволяющие в относительно короткие сроки разобраться в предметной области по мере решения задачи (клиентский отток, цена на недвижимость и т. д.), де-факто самая обширная коллекция открытых датасетов собрана на Kaggle.
Формальных ограничений, какие действия можно совершать с датасетом, нет, однако каждая DS задача, как правило, состоит из стандартных шагов, включающих Exploratory Data Analysis (EDA), Feature Engineering (FE), моделирование (modelling), валидацию (validation).
Наибольший фокус на ознакомление с данными, как правило, приходится на этап EDA. На профильных ресурсах, в частности Kaggle, Towards Data Science или в сообществе ODS в Slack, можно найти много примеров и практик по EDA.

Сергей Андрон
старший аналитик данных Биржи грузоперевозок ATI.SU
Начинающему специалисту по Data Science лучше всего практиковаться, решая конкретные практические задачи. Обычно их ставит перед вами бизнес: как увеличить прибыль, привлечь новых клиентов, какие будут продажи, какие особенности у наших пользователей, откуда они приходят. Но во время самостоятельной практики вы можете выбрать задачу по желанию. Определиться с направлением работы очень важно: если вы выбрали область, в которой интересно прокачиваться, и потренировались на соответствующих датасетах, впоследствии будет проще найти подходящую работу.
Соответственно, если вы хотите заниматься прогнозированием, нужно использовать одни датасеты и инструменты, если распознаванием или классификацией — другие. Неплохие наборы данных, собранные из реальных источников, есть на FigureEight. Там можно выбрать набор данных, подходящий для решения интересующей вас задачи: проблема дорожного трафика, проблема задержки рейсов и так далее. Однажды я увидел там специфическую задачу: по лайкам в Instagram нужно было определить, какие детали на фотографиях пользователи считают наиболее привлекательными и наоборот. Датасеты на этом ресурсе относительно чистые и красивые, с ними можно работать без предварительной очистки. Кстати, если вы получаете неподготовленные данные, подготовительная работа займет 70–80% времени, необходимого для решения задачи.
Вы получили датасет и не знаете, как к нему подступиться? Начните исследование. План работы с данными в процессе решения Data Science задачи может быть следующим.
Получение данных
- Определите объёмы данных (обычно чем больше, тем лучше: можно использовать только данные компании либо добавить к ним данные из открытых источников или данные сторонних организаций, предлагающих такую услугу).
- Охарактеризуйте данные: по количеству, по качеству.
Исследование и визуализация данных для их понимания
- Определение характера взаимосвязи между данными (особенно с целевой переменной).
- Визуализация (столбчатая диаграмма, линейная, лучевая, гистограмма – вариантов очень много).
Подготовка данных
- Определение основных проблем с данными: аномалии, пропуски, выбросы и другие.
- Оцените необходимость трансформации (после очистки можно использовать различные виды группировки, чтобы привести данные к требуемому для конкретной задачи виду).
- Нормализация и стандартизация (приведение данных к значениям в ограниченных диапазонах, для чувствительных к флуктуациям моделей это очень важно).
- Создание новых признаков на основе старых (стоимость дома лучше будет выражаться через площадь дома, чем через длину и ширину стен).
- Редуцирование данных (использовать, если признаков очень много или есть подозрения на мультиколлениарность).
Выбор и обучение модели
- Определите тип моделей под решаемую задачу с учётом характера данных.
- Обучите несколько моделей на скорую руку и измерьте их эффективность.
- Проанализируйте наиболее значимые переменные.
- Проанализируйте типы ошибок, допускаемых моделями (и как их можно исправить).
- Пройдитесь ещё раз по моделям, используя наиболее значимые признаки и исправив ошибки.
- Выберите до пяти разных наиболее эффективных моделей, отдавая предпочтение более простым и более масштабируемым (принцип бритвы Оккама).
Точная настройка модели
- Проведите точную настройку гиперпараметров с применением перекрестной проверки.
- Отбор значимых атрибутов.
- Экспериментируйте с ансамблями.
После построения модели и её валидации вы можете приступить к последнему этапу — представление данных в удобном для бизнеса виде. Это могут быть таблицы, предсказанные роли, отметки на фотографиях, также можно создать отдельное хранилище или сгенерировать новые данные.

Александр Кобозев
старший менеджер блока BI ГК «Лига Цифровой Экономики»
Источники
Главные источники информации по Data Science — книги. Я бы посоветовал новичкам Elements of Statistical Learning и ML (Murphy). Надо прочитать их от корки и до корки — это займёт пару месяцев. Там подробно описывается вся классическая теория, почему и зачем всё это нужно.
Наборы данных
Есть типичные наборы данных для каждой области специализации: ImageNet (CV), COCO (CV), Wikidump (NLP), OpenTTD/Freesound (audio). С табличными данными нюансов много, классика — Titanic. Но типов задач с табличками существует великое множество, особенности данных решают. Чем больше датасетов вы изучите, тем проще потом будет. Также существует Kaggle, где очень много уже практически любых смоделированных данных.
Что делать с открытыми наборами данных
По общепринятым канонам реализовывать архитектуры, сравнивать с эталоном, пробовать улучшать/менять параметры, ускорять (метод MLE). Либо делать EDA, показывать их опытному чуваку, пробовать моделировать разные факторы/искать эвристики (DS). Группировки, в целом, по пути можно освоить — это несложно.
Визуализация
Визуализации бывают разные: подспорье для анализа и всякие темы (дашборды) для бизнеса. Первую можно делать и показывать кому-то опытному, вторую вам придется осваивать на боевых задачах/показывать менее подготовленным людям. Суть в том, что хорошая визуализация упрощает восприятие, понял дилетант — значит, суть хорошо передана. На Kaggle есть конкурсы на визуализацию/анализ данных. Можно смотреть лучшие работы и учиться. Более точно тяжело описать, ибо чёткого плана на эту тему нет для DS, обычно упор делается на то, что пригодится в работе в ближайшее время.
Касательно Kaggle
Там есть чётко поставленные задачи с метриками и лидербордом в рамках соревнований. Это научит делать пайплайны на 20–40%. Но там также взрослые дядьки выступают, хороших результатов не будет точно, это не должно расстраивать.
Постановка задач, гипотез, метрик
Самому это изучать очень тяжело. Гуглите литературу по научному методу, учите его на зубок, чтобы вас можно было ночью разбудить и спросить за методологию. Метрики придётся разбирать: какие бывают, какие особенности. Применение правильное придёт с опытом. Гипотезы тоже только с опытом придут, но надо пробовать на тех же датасетах.
Системы ML
Придётся собирать по крупицам инфу о том, как работают системы ML в бизнесе. Тут даже конкретную ссылку не могу привести, сложно советовать — компиляций хороших крайне мало. Надо гуглить, смотреть, общаться с коллегами — ходить на конференции, слушать и набираться разума.
Итого
Практика с датасетами даст небольшой процент необходимых знаний. Помимо неё важно строго понимать, зачем и почему применяется условные способ А и метрика Б. Для этого нужна теория, а она обычно плавает почти у всех, так что лишним не будет её повторно изучить. Даже если человек вышел из сильного вуза — всё равно стоит заново пройти курс по линейной алгебре, математической статистике.
Ну и важно понимать, кем вы себя видите. Условный DS близок к аналитику: меньше кодит и больше погружён в бизнес. Лучший способ получить бизнес-навыки — стажировка в компании с налаженными процессами.
Условный MLE хорошо программирует, максимально погружен в матанализ, мало общается с бизнесом. Ему важнее определиться с треком направления (зрение, тексты, звуки, временные ряды, прочее; но таблички на самом деле тут уже меньше подходят) и самому изучать все ключевые архитектуры — писать их самому, много читать.
Бывают уникумы, которые тянут и то, и то, но их очень мало.

Павел Колосов
ведущий разработчик программного обеспечения Тверского технологического центра Accenture в России
Как правило, изучение Data Science начинается с прохождения каких-либо курсов, включающих в себя практическую часть со всеми необходимыми датасетами, их описанием и инструкциями. После получения базовых знаний, Data Scientist пробует свои силы в более сложных практических задачах, близких к реальным, возникающим в бизнесе, науке или индустрии. Чаще всего это учебные задачи на Kaggle и подобных площадках.
Там же стоит искать и данные для следующего шага — участия в соревнованиях на датасетах с реальными данными.
Если не хочется участвовать в соревнованиях, стоит попробовать создать свой проект. В таком случае отталкиваться следует не от датасета, а от предметной области, в которой было бы интересно попробовать свои силы. Выбрав такую область необходимо определить в ней некоторую проблему (например задачу о фильтрации спама или о распознавании речи). При этом задача не обязательно должна быть новой и сложной, ведь мы говорим о начинающем специалисте, для которого основной целью является получение практических навыков. Главное — решить поставленную задачу самостоятельно.
Это может быть как задача машинного обучения, так и статистическая задача, либо даже интересная визуализация данных.
При этом собирать датасеты самостоятельно, например через парсинг сайтов, чаще всего сложно и неэффективно.
Существует множество публично доступных датасетов для исследований в различных прикладных направлениях.
Для поиска необходимых данных можно воспользоваться следующими ресурсами:
- проект Open Michigan от University of Michigan;
- текстовый корпус для исследований в области NLP и вычислительной лингвистики от Michigan State University;
- раздел датасетов на Kaggle содержит различные наборы данных, регулярно обновляемые сообществом;
- платформа Google Dataset Search;
- сообщество Open Data Science, к которому можно присоединиться и обратиться за советом в поиске нужных данных.
Итак, где брать данные и что с ними делать?
Откуда брать данные:
- государственные сайты вроде data.gov.ru, data.mos.ru;
- Visual Genome;
- FigureEight;
- Open Michigan;
- раздел датасетов на Kaggle;
- Google Dataset Search;
- датасеты для NLP.
Что с ними делать:
- писать свои модели, пытаться обойти эталонные;
- учиться исследовать и визуализировать данные;
- учиться предобрабатывать данные: нормализация, создание новых признаков и т. д.;
- попробовать реализовать свой проект, который будет использовать эти данные.
Напоминаем, что вы можете задать свой вопрос экспертам, а мы соберём на него ответы, если он окажется интересным. Вопросы, которые уже задавались, можно найти в списке выпусков рубрики. Если вы хотите присоединиться к числу экспертов и прислать ответ от вашей компании или лично от вас, то пишите на experts@tproger.ru, мы расскажем, как это сделать.

13К открытий15К показов

Максим Коновалов расскажет, как стал Data Scientist в МТС, пройдя школу аналитиков данных МТС и стажировку.
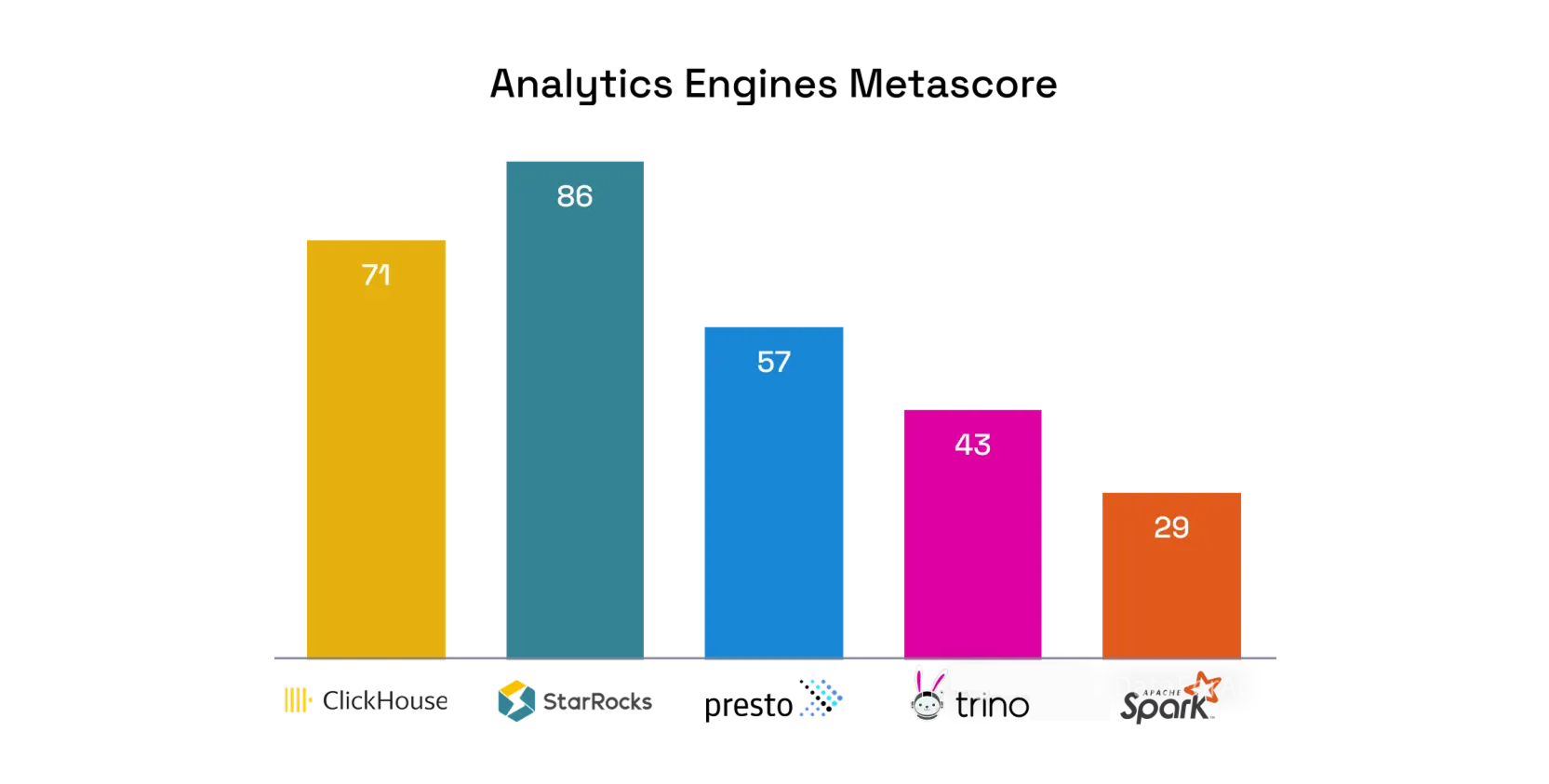
Эволюция от Hadoop к cloud‑native и ИИ‑архитектурам. Многомерное сравнение Spark, Presto, Trino, ClickHouse и StarRocks по скорости, масштабируемости, кэшам, SQL/Python, HA и др.

Специализации в Data Science — дата-сайентист, аналитик, дата-инженер, ML-инженер. Кем стать.

Учёные создали «периодическую таблицу» машинного обучения — инструмент, который помогает предсказывать появление новых ИИ-моделей и технологий. Рассказываем, как это работает.