Google научила нейросеть распознавать отдельные голоса в толпе

Искусственный интеллект анализирует видео, на котором говорят одновременно несколько человек и выдает отдельные аудиодорожки для каждого голоса.
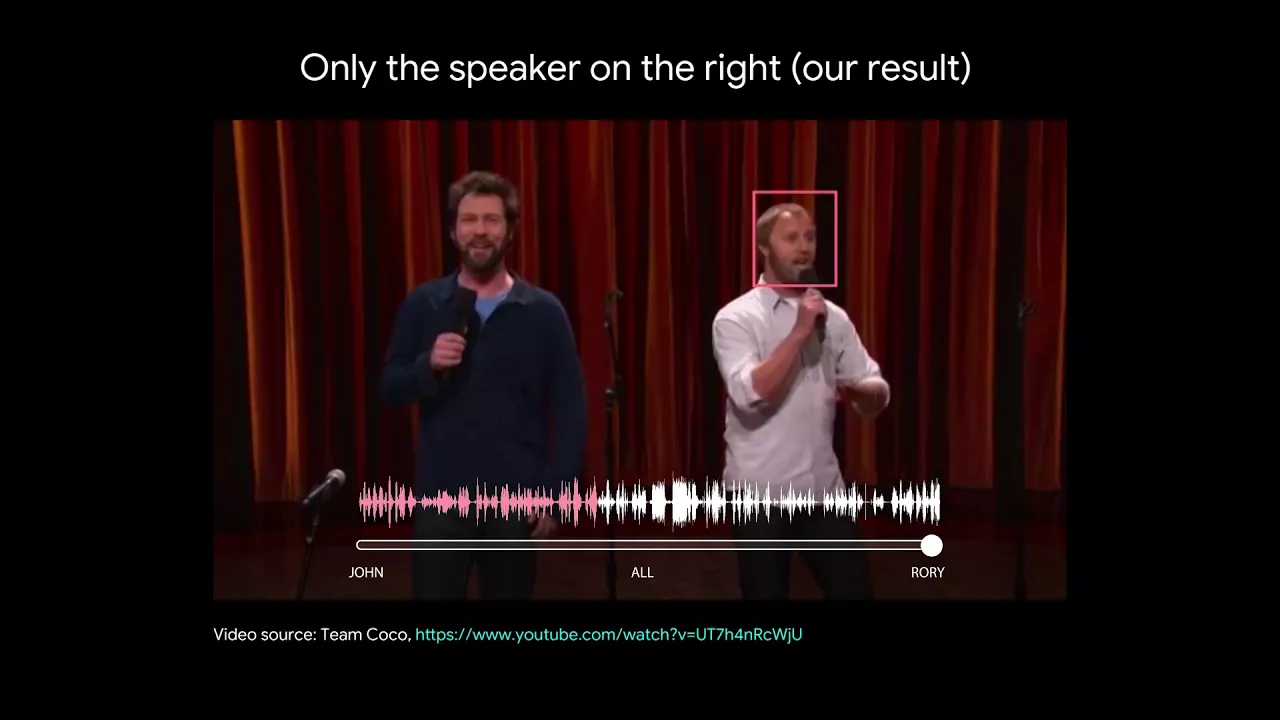
Google представила систему ИИ, анализирующую видео, на котором говорят одновременно несколько человек, и выдающую отдельные аудиодорожки для каждого голоса.
Как это работает?
Нейронная сеть распознает лица и речь, сопоставляет звук с мимикой и выделяет отдельный канал для каждого говорящего. Она умеет выделять и усилять голос, заглушать посторонний шум. Для корректной работы звуковая и видеодорожка должны быть синхронизированы.
Чтобы обучить искусственный интеллект, исследователи собрали коллекцию из 100 000 видеороликов на YouTube и извлекли из них сегменты с речью без помех. К получившимся 2000 часов видео добавили фоновый шум с AudioSet. Сначала сеть училась читать по губам, затем — отсеивать смех, кашель и другие посторонние звуки. Потом её научили различать мимику в диалогах и в том случае, если лицо частично закрыто. В завершение системе показали, как сортировать полученную информацию.
Google собирается использовать функцию в видеочатах Hangouts и Duo: она поможет лучше понимать собеседника, если тот находится в толпе. В слуховых аппаратах система усилит звук голоса, если подключить к ней камеру. Среди других возможностей — применение технологии для точного автоматического составления субтитров. Также возможно использование в методах скрытого наблюдения и подслушивания.
В 2018 году команда Facebook AI Research с группой международных исследователей научила искусственный интеллект объяснять свои действия. В этом им помог тест на уровень развития девятилетнего ребенка: нейросеть идентифицировала объект на фото и объясняла правильность своего выбора.

1К открытий1К показов

Стартап под названием Inflection AI, который поддерживают компании LinkedIn и DeepMind, представил миру чат-бота Pi.

В Microsoft представили подробный отчёт о работе GPT-4, который заключил, что у языковой модели есть признаки человеческого мышления.

Рассказали, какие ошибки совершал Билл Гейтс и как это сказалось на успехе Microsoft. Во всём виноваты недальновидность и медлительность.

Составили подборку из 10 бесплатных нейросетей, которые генерируют текст, изображения и видео, и рассказали о каждой из них.