


Выпущена СУБД EuclidesDB с элементами машинного обучения
Новости
СУБД EuclidesDB позволяет подключать модели машинного обучения и использовать их для индексирования и обработки результатов поиска.
1К открытий2К показов

Доступна первая экспериментальная сборка СУБД EuclidesDB, написанная на языке C++. Эта система позволяет задействовать модели машинного обучения во время индексирования и выборки данных из базы.
Что умеет СУБД?
К СУБД EuclidesDB можно подключать модели машинного обучения и использовать их для выдачи результатов. Это позволяет задействовать модель, которую натренировали распознавать определённые объекты на фото, после чего выбирать из базы подходящие изображения автоматически.
Подобное пригодится в крупных базах данных, например, для интернет-магазинов в качестве системы рекомендаций или для тех же задач в потоковых сервисах. СУБД сможет выбирать данные в зависимости от того, чем заинтересовался пользователь. При этом можно подключать несколько моделей, обученных на разные категории данных.
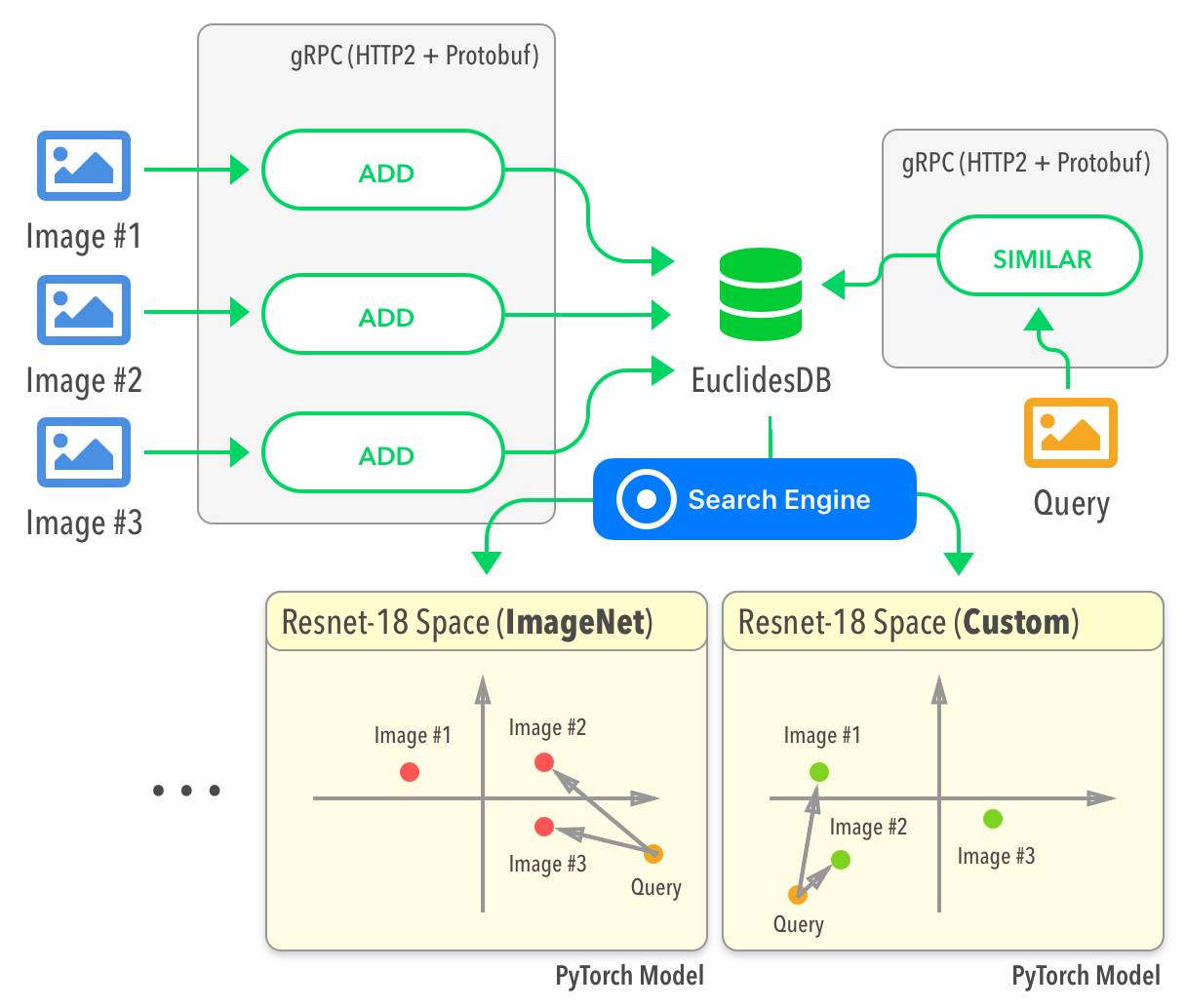
При добавлении новых данных требуется указывать модель машинного обучения для каждого изображения. Система обрабатывает информацию и сохраняет ключ в локальное хранилище. На основе этих результатов формируется индекс запросов. В случае сходства элементов в запросе нужно указать допустимый диапазон моделей для поиска. На выходе система вернёт перечень аналогичных элементов с указанием уровня релеватности.
Как это работает?
EuclidesDB использует фреймворк gRPC для вызова удалённых процедур, протокол HTTP/2 — для сетевого взаимодействия и Protocol Buffers — для сериализации. Низкоуровневое хранение реализовано с помощью системы LevelDB, а работа моделей машинного обучения построена на библиотеке PyTorch.
В комплекте идёт три готовые модели — resnet101, resnet18 и vgg16 — для распознавания и классификации фотографий объектов. В будущем планируется добавить обработку и других видов информации.
При этом используется различные способы индексирования и поиска:
- annoy — система нечёткого поиска на базе одноимённой библиотеки. Она используется в музыкальном сервисе Spotify для создания списка рекомендаций. Библиотека решает задачу поиска ближайшего соседа, при этом алгоритм оптимизирован, чтобы уменьшить потребление памяти и файла подкачки;
- faiss — система для поиска похожих элементов с большим количеством настроек;
- exact_disk — система для поиска точных совпадений. В этом случае индекс сразу сохраняется на диск, что минимизирует потребление ОЗУ.
В ноябре 2018 года Apple выпустила первую стабильную версию открытой распределённой СУБД FoundationDB. Она рассчитана на обработку крупных наборов структурированных данных. СУБД относится к категории NoSQL-систем и работает с большим количеством языков программирования.

1К открытий2К показов

Telegram интегрирует чат-бота Grok от xAI Илона Маска. Пользователи получат доступ к ИИ прямо в мессенджере — для чатов, модерации, фактчекинга и редактирования сообщений. Партнёрство принесёт Telegram $300 млн и долю от подписок.

Почему микросервисная архитектура нужна не во всех случаях. Причины популярности микросервисов — маркетинг, хайп и законы рынка.

Учёные DeepMind предлагают заменить тест Тьюринга на «эпоху опыта» — ИИ должен действовать, ошибаться и учиться на своём прошлом

Что делать, если хочется бросить программирование? Разбираем, как выгорание подкрадывается к разработчикам, почему одна 5-минутная привычка может вернуть интерес к коду и почему не надо гнаться за продуктивностью, чтобы остаться в профессии.