


Разработчики Facebook создали датасет персонажей для диалоговых нейросетей
Новости
Диалоги подборки составлены на основе общения пользователей Reddit. Сет персонажей позволил улучшить качество работы чат-ботов на основе ИИ.
842 открытий860 показов

Исследователи из Facebook создали подборку учебных данных для повышения эффективности обучения нейросетей, специализирующихся на общении с живыми пользователями. Она включила в себя 5 миллионов персонажей и 700 миллионов диалогов.
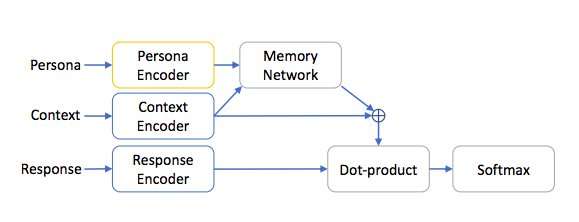
Создание набора персонажей
В основу датасета разработчики заложили подборку PERSONA-CHAT, разработанную совместно специалистами Facebook и учеными Монреальского института алгоритмов обучения. В первую очередь в глаза бросается увеличение объема данных на три порядка — базовый датасет содержал всего около тысячи личностей. Но исследователи обращают внимание на более важный аспект. Контент PERSONA-CHAT был создан искусственно, а новый сет сформирован на базе диалогов пользователей Reddit.
Диалоговая нейросеть, прошедшая обучение на новом наборе данных, ведет более увлекательные диалоги, чем сети, не имевшие доступа к коллекции личностей. Более того, обучение систем на базе персонажей происходит быстрее.
Выбор подходящего набора данных для обучения искусственного интеллекта — одна из ключевых задач для разработчиков. От него зависит точность и производительность создаваемого ПО. В сентябре 2018 года Google в тестовом режиме запустила специальный инструмент для поиска подходящих подборок.

842 открытий860 показов

Syncora.ai выпустила открытый синтетический датасет из 5000 записей о продуктивности и выгорании разработчиков — с метриками фокуса, встреч, кода и стресса

Спойлер: лидер не всегда очевиден, а самая быстрая модель обходит топовые решения по скорости в 4 раза

Как найти и устранить архитектурные bottleneck'и: причины тормозов, типовые ошибки и пошаговая методика диагностики.

Собрали 45 самых популярных AI-моделей декабря 2025 года с Hugging Face — от генерации изображений за секунду до агентов, которые играют в видеоигры. Разобрали по категориям — языковые модели, кодинг, генерация картинок и видео, 3D, аудио и агенты.