Разработчики Facebook создали датасет персонажей для диалоговых нейросетей

Диалоги подборки составлены на основе общения пользователей Reddit. Сет персонажей позволил улучшить качество работы чат-ботов на основе ИИ.

Исследователи из Facebook создали подборку учебных данных для повышения эффективности обучения нейросетей, специализирующихся на общении с живыми пользователями. Она включила в себя 5 миллионов персонажей и 700 миллионов диалогов.
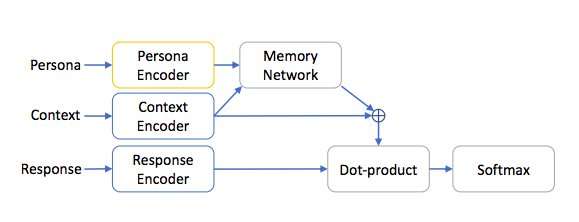
Создание набора персонажей
В основу датасета разработчики заложили подборку PERSONA-CHAT, разработанную совместно специалистами Facebook и учеными Монреальского института алгоритмов обучения. В первую очередь в глаза бросается увеличение объема данных на три порядка — базовый датасет содержал всего около тысячи личностей. Но исследователи обращают внимание на более важный аспект. Контент PERSONA-CHAT был создан искусственно, а новый сет сформирован на базе диалогов пользователей Reddit.
Диалоговая нейросеть, прошедшая обучение на новом наборе данных, ведет более увлекательные диалоги, чем сети, не имевшие доступа к коллекции личностей. Более того, обучение систем на базе персонажей происходит быстрее.
Выбор подходящего набора данных для обучения искусственного интеллекта — одна из ключевых задач для разработчиков. От него зависит точность и производительность создаваемого ПО. В сентябре 2018 года Google в тестовом режиме запустила специальный инструмент для поиска подходящих подборок.

829 открытий830 показов

Рассказываем про React, Angular и Vue.js — трёх слонов, на которых держится мир современной веб-разработки.

Команда MediaSoft разобралась, в чем разница между функциональным и нефункциональным тестированием и какие инструменты пригодятся.
Собрали лучшие материалы по Python с 1 по 15 мая. Узнайте, что такое PandasAI и как сделать языковую модель на Python.
В статье рассказываем, как определить уровень интеллекта человека по его данным со страницы в VK с помощью ИИ.