


Нейросеть научилась воссоздавать трехмерные сцены по фотографиям
Новости Отредактировано
Алгоритм из генеративной и репрезентативной сетей наблюдает сцену с нескольких ракурсов, а затем создает ее трехмерную модель с произвольного угла обзора.
2К открытий3К показов
Разработчики из DeepMind представили алгоритм Generative Query Network (GQN) на нейросетях, который исследует двумерную сцену и определяет, как она будет выглядеть в трехмерном пространстве.

Обучение
GQN состоит из генеративной и репрезентативной сетей. Репрезентативная нейросеть кодирует информацию о полученных двумерных изображениях и представляет ее в виде вектора. Затем генеративная сеть предсказывает, как будет выглядеть окружение с новой точки наблюдения, и создает трехмерный рендер.

Если нейросеть видит один и тот же объект много раз, то запоминает его характеристики и использует при последующих взаимодействиях. По словам разработчиков, ИИ способен воспроизвести лабиринт, просканировав несколько сделанных изнутри фотографий.
Эксперименты
Тесты в виртуальном трехмерном мире показали, что GQN создает качественные изображения без знаний о законах перспективы или освещения. Также система классифицирует частично скрытые объекты и считает их количество.
Разработчики обучали нейросети только на искусственно созданных данных, однако в перспективе они намерены использовать реальные сцены.
В мае 2018 года исследователи из Google представили алгоритм Stereo Magnification, который из двух снятых с близких ракурсов кадров воссоздает новые снимки с других ракурсов. В отличие от GQN, он не создает изображения с принципиально другого угла обзора, но работает с реальными фотографиями.

2К открытий3К показов

Обзор лучших альтернатив Notion для ведения базы знаний в IT-проектах в 2025 году. Сравнение функционала, интеграций и удобства для разработчиков и команд.
Искусственный интеллект продолжает становиться все «интеллектуальнее», а новые инструменты удивляют своей мощью. Рассказываем о пяти решениях, которые уже переворачивают рынок.
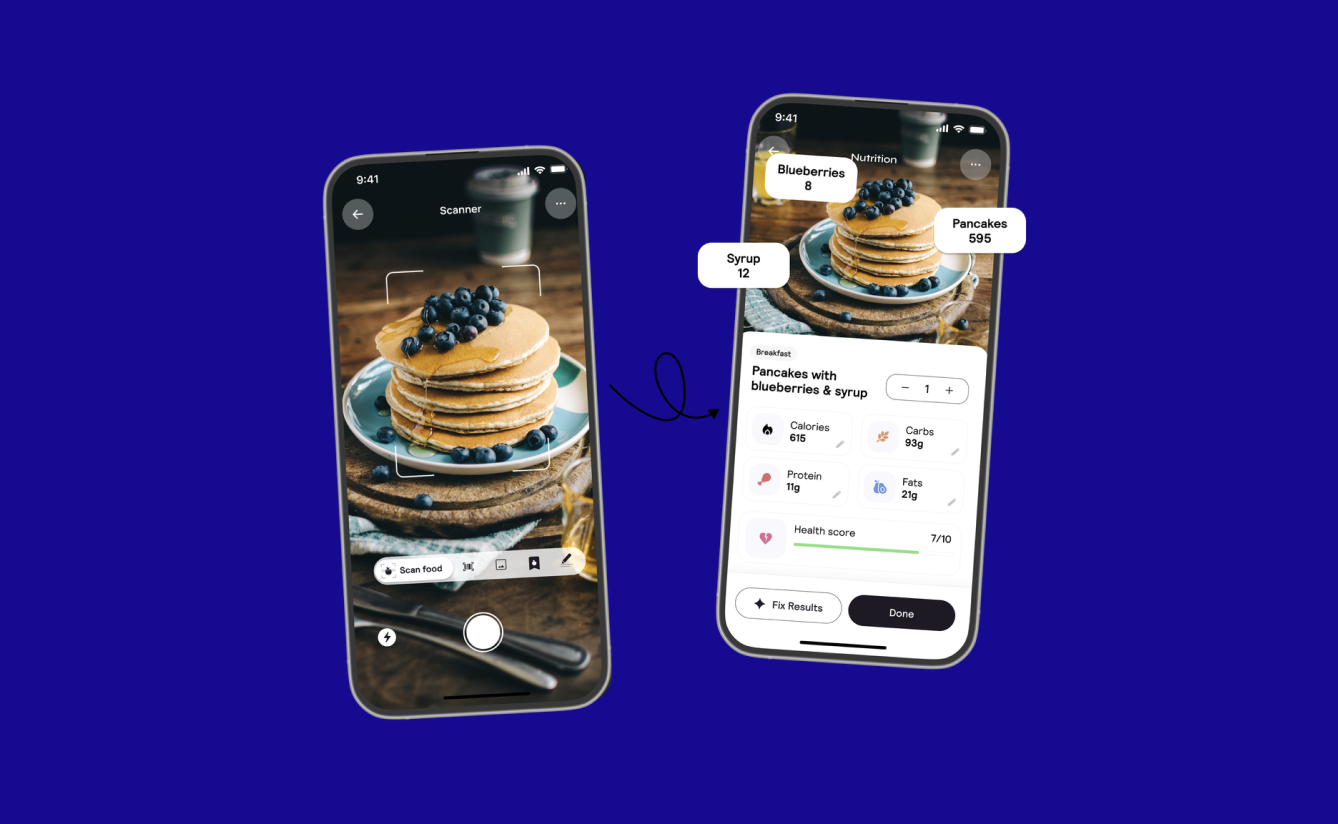
Приложение для подсчета калорий Cal AI, разработанное тинейджерами из США, скачали более 5 млн раз — оно принесло ребятам более миллиона долларов.

Узнайте, какие нейросети помогут быстро создавать видео без опыта и дорогого оборудования. Обзор 12 онлайн-сервисов: от Sora и Runway до «Шедеврума». Сравнение возможностей, языков и тарифов.