


Google AI представила BERT, метод предварительной тренировки для обработки естественного языка
Новости Отредактировано
BERT подразумевает начальную тренировку на большом массиве неразмеченных данных, чтобы дать модели «общее представление о языке».
7К открытий7К показов

Команда Google AI разработала новую методику предварительной тренировки систем обработки естественного языка. BERT (Bidirectional Encoder Representations from Transformers) помогает ИИ-моделям получить «общее представление о языке» на больших корпусах неразмеченного текста, например из «Википедии». Затем эти алгоритмы можно использовать для конкретных задач.
Пока BERT работает только с английским языком.
Причины для появления BERT
Как отмечает команда Google AI, для разных задач, связанных с обработкой естественных языков, требуются различные наборы данных, объёмом не превышающие обычно пары тысяч или пары сотен тысяч образцов. Однако современные языковые системы работают эффективнее, если их тренировать на миллионах или миллиардах размеченных примеров. Для этого исследователи разрабатывают методики предварительной тренировки ИИ-моделей на неразмеченных данных, которые можно просто найти в Интернете.
После обучения на небольших специфических наборах такие модели хорошо справляются с конкретными задачами — анализом тональности текста или вопросно-ответным тестом.
Особенности BERT
Google AI приводит такую условную классификацию способов обработки языка:
- контекстно-свободная;
- контекстно-зависимая (однонаправленная или двунаправленная).
BERT предлагает двунаправленную контекстно-зависимую обработку. Это значит, что языковая модель учитывает в определении контекста конкретного слова то, что стоит в предложении перед ним и после него. Однонаправленная учитывает только предстоящие слова.
К примеру, в предложении «I accessed the bank account» однонаправленная языковая модель представит слово «bank» относительно «I accessed the», а двунаправленная — «I accessed the … account».
Это не первый метод двунаправленной обработки — его использует также система ELMo, разработанная Институтом искусственного интеллекта Пола Аллена. Однако BERT демонстрирует более сложную связь между слоями представления языка, так что она считается глубоко двунаправленной, а ELMo — поверхностно двунаправленной. Для сравнения Google AI привела визуализацию архитектуры нейросетей соответствующих типов, где также можно увидеть пример метода однонаправленной обработки — OpenAI GPT:
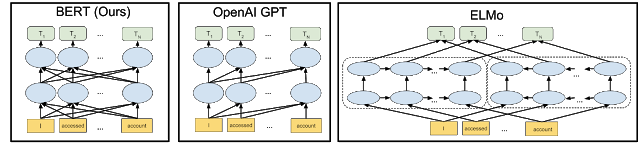
Помимо прочего, BERT учит улавливать логические связи между предложениями. К примеру, нейросеть сможет понять, действительно ли второе предложение должно следовать за первым или оно случайное.
Оценка эффективности
Команда Google AI сравнила свой метод с другими современными системами обработки естественного языка по тесту SQuAD (Stanford Question Answering Dataset) версии 1.1 для вопросно-ответных систем. F1 показывает оценку аккуратности ответа, а EM (ExactMatch) — точное совпадение. Первая строка отражает показатели людей.

Кроме того, результаты показали, что успехи BERT практически не связаны с тем, какую архитектуру нейросети выбирали для конкретного задания.
Открытый код
Google AI опубликовала основанный на TensorFlow код модели архитектуры Transformer и несколько предварительно натренированных языковых алгоритмов. Используя открытый код, каждый может обучить свою вопросно-ответную систему за 30 минут на мощностях Google Cloud TPU или за несколько часов на единственном графическом процессоре.
В своей работе команда Google AI опиралась на разработанную годом ранее архитектуру Transformer. Нейросеть с таким строением учится сопоставлять слова в предложении друг с другом, улавливая таким образом его общий контекст.

7К открытий7К показов

OpenAI и xAI допустили утечку личных переписок из-за открытых ссылок: в индекс Google попали имена, телефоны, адреса и даже API-ключи. Что нашли исследователи, чем это грозит пользователям и как защитить свои данные — рассказываем.

ИИ-модель s1, обученная за $50 и 26 минут, обошла ChatGPT в математике. Это ставит под вопрос необходимость миллиардных вложений в ИИ

Google сняла запрет на использование ИИ в оружии и слежке, объясняя это гонкой технологий. Решение вызвало недовольство сотрудников

Некоторые психотерапевты начали использовать ChatGPT для анализа сессий и ответов пациентам — тайно. Что стоит за этой тенденцией, какие риски она несёт для конфиденциальности и почему пациенты чувствуют себя преданными.