


Google выложила на GitHub инструмент для создания систем, распознающих синтаксис естественных языков
Новости Отредактировано
19К открытий19К показов
Сегодня Google выложила на GitHub фреймворк SyntaxNet, работающий на нейронных сетях, на основе которого можно строить системы для синтаксического разбора предложений на естественных языках. Вместе с ним они выложили уже “натренированный” парсер Parsey McParseface, который уже распознаёт предложения на английском языке с поразительной точностью.
По статистике, которую приводит Google, парсер определяет синтаксическую структуру предложений с точностью в 94%. Вот как это выглядит, если ему подать предложение “Alice saw Bob” (Алиса увидела Боба):

Как видно, система правильно определила “Alice” как субъект действия, “Bob” как объект, а “saw” как глагол, т.е. само действие. Что будет если отдать Parsey что-нибудь посложнее, например “Alice drove down the street in her car” (Алиса поехала вниз по улице в своей машине)?
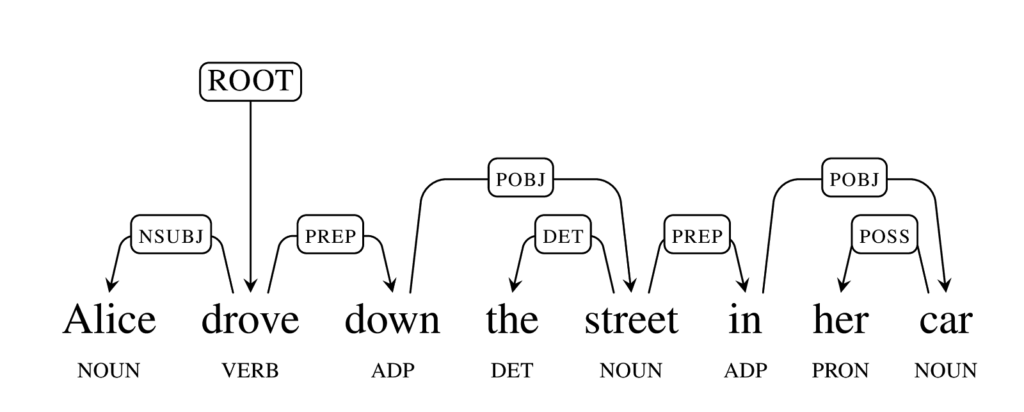
Система опять отлично определила связи между словами в предложении. Последний пример, который мы приведём: “Alice, who had been reading about SyntaxNet, saw Bob in the hallway yesterday” (Алиса, читающая про SyntaxNet, увидела вчера Боба в коридоре):
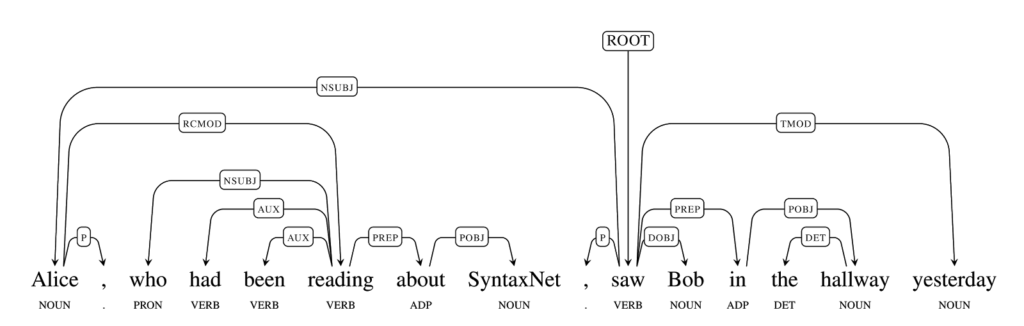
После того, как я смотрю на этих схемы, мне кажется, что эта программа понимает английский лучше, чем я. Возможно, вы сейчас задумались, а так ли вообще необходима система, которая распознаёт синтаксис предложений. Дело в том, что конструкции на натуральных языках могут иметь разные синтаксические структуры в зависимости от контекста. Этих вероятных схем может быть не две-три, а двадцать, тридцать или сотня, — если говорить о предложениях, в которых несколько десятков слов. И создание системы, которая может распозновать их с вероятностью в 94% — большой шаг на встречу созданию настоящего искусственного интеллекта.
Больше технических деталей можно найти в заметке в блоге Google Research.

19К открытий19К показов

Хакеры нашли способ обмануть ChatGPT и получить доступ к личным данным через «отравленные» документы
Исследователи показали, как ChatGPT можно обмануть для кражи данных Google Drive с помощью скрытых инструкций в «отравленном» документе. OpenAI устранила уязвимость, но риск остаётся.

Алексей Власов, партнер и коммерческий директор ИТ-интегратора Notamedia, рассказывает, с какими киберугрозами сталкиваются B2B- и B2G-сектора и как организациям защитить свои данные.

Разбираемся, зачем они нужны и когда их использовать

Cобрали опыт зарплат айтишников из пяти стран и узнали, как вписаться в местную культуру и где комфортнее жить.