Intel AI Lab открыла библиотеку обработки языка для диалоговых систем

Библиотека поддерживает работу с фреймворками машинного обучения Intel Nervana™ graph, Intel neon, TensorFlow, Dynet и Keras.
Intel AI Lab открыла исходный код библиотеки для обработки естественного языка, основанной на наборе моделей глубинного обучения. Библиотека создана для совершенствования чат-ботов и виртуальных помощников. Например, она учит распознавать категории объектов, понимать намерения пользователя и то, каких он ждёт действий.
Код библиотеки написан на языке Python и распространяется под лицензией Apache 2.0. Она поддерживает работу с фреймворками машинного обучения Intel Nervana™ graph, Intel neon, TensorFlow, Dynet и Keras.
Состав
В NLP Architect входят:
- набор базовых моделей NLP для обработки информации на естественном языке;
- модули NLU для распознавание смысла информации на естественном языке;
- модули для семантического разбора;
- компоненты для создания диалоговых систем с элементами искусственного интеллекта, таких как чат-боты;
- шаблоны для построения готовых сервисов и примеры приложений с реализацией отвечающих на вопросы автоинформаторов, систем машинного чтения и интерфейсов для визуализации взаимосвязи между словами.
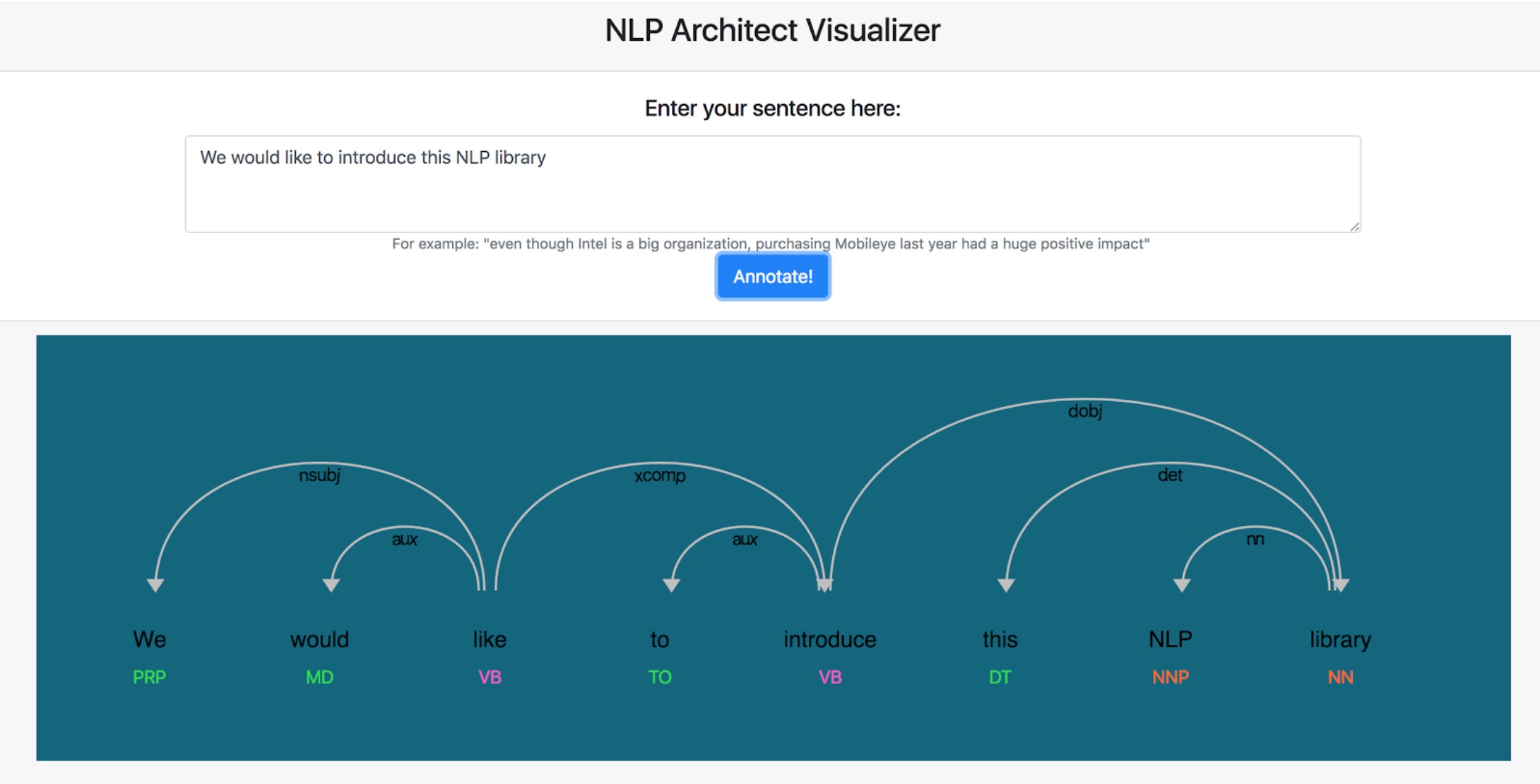
Задачи
По словам разработчиков, NLP Architect будет полезна:
- в тренировках моделей с использованием предоставляемых алгоритмов, эталонных наборов данных и собственных данных;
- при создании новых доступных моделей и расширении существующих;
- в исследованиях применимости моделей глубинного машинного обучения для решения задач обработки информации на естественном языке;
- в оптимизации алгоритмов машинного обучения;
- для интеграции в проекты готовых модулей и утилит, предоставляемых библиотекой.
Модели библиотек NLP и NLU пригодны для разбора зависимостей между языковыми конструкциями, определения смысловых примитивов и маркировки слотов, применения сетей памяти для построения диалогов, применения сетей ключ/значение для организации взаимодействия в форме вопрос/ответ, использования моделей векторов для расстановки слов.
NLP и NLU используются при проведении семантической сегментации словосочетаний, выделении терминов, определении смысловой информации и разбивке текста на структурные элементы.
Модели обработки естественного языка
В библиотеке реализовали набор моделей глубинного обучения, ориентированных на работу с естественной речью. Функции не фокусируются на выполнении задач определенной специфики, но Intel думает над вариантами.
Некоторые инструменты в библиотеке созданы на наборах, обычно используемых в исследовательских кругах для тестов производительности. Она также обучает модели с помощью пользовательских данных или открытых баз, разработанных на основе TensorFlow от Google или PyTorch от Facebook.
С библиотекой Intel AI Lab разработчики смогут загружать тренировочные наборы, обучать на них нейросеть Intel. После — запускать тренировку самостоятельно вне языковой библиотеки и использовать модель в качестве входных данных приложения.
Разработка диалогового искусственного интеллекта с помощью ряда крупных компаний сейчас поставлена на поток. Создавать собственных голосовых ассистентов помогает Watson Assistant от IBM. С Яндекс.Диалогами можно создавать собственные навыки для «Алисы». Также компании разрабатывают виртуальных помощников для врачей и композиторов.

1К открытий1К показов
В этой статье перечислены 7 самых быстрорастущих open-source репозиториев GitHub, о которых вам следует знать.

Google представила нейросеть Gemini, которая круче ChatGPT. Рассказываем, что это за нейросеть, что она умеет и как ее использовать в России.
Microsoft анонсировала внедрение ИИ в Windows 11: в операционную систему интегрируют языковую модель из Bing и ИИ-помощника Windows Copilot.

Исследование показало, что помощники, такие как Copilot, пишут код, который по качеству похож на «хаотичную работу неопытного аутсорсера».