


В Google признали, что сортировка больших данных не нужна
Новости Отредактировано
12К открытий12К показов
Компания Google поделилась в своем блоге, посвященном облачным вычислениям историей развития фреймворка MapReduce с точки зрения применения его для сортировки больших данных.
С момента появления технологии, разработчикам удалось существенно снизить временные затраты на работу алгоритма Petasort, специализировавшегося на данных объемом порядка нескольких Петабайт (1024 Терабайта). На представленном графике показано соотношение затрачиваемого времени на сортировку 1PB данных за каждый год работы над технологией.
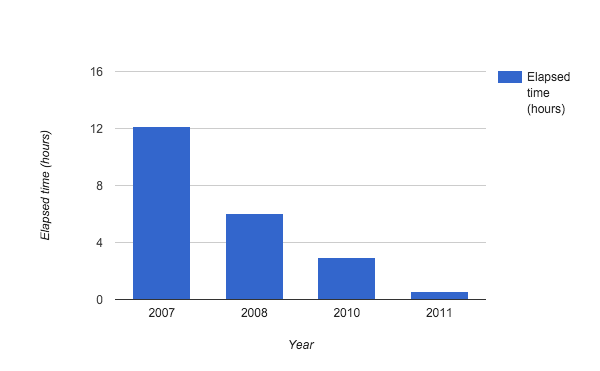
В 2012 объем тестов увеличился до 50PB. И этот процесс занял менее суток — 23 часа 5 минут.
Также в оригинальном посте автор поделился сделанными командой выводами. Их два:
- Необходимости в сортировке таких объемов данных нет. Не удалось найти ни единого практического применения технологии.
- Система способна работать действительно хорошо, однако достигнутые результаты не стоили тех усилий, которые были вложены в нее. «MapReduce пришлось слишком долго подстраивать».
В связи с этим в дальнейшем разработчики обратили внимание на области, где предварительная настройка не сопряжена с таким объемом работы. Например, Dataflow способен сам разбить данные на независимые куски (и динамически менять разбиение, если требуется), таким образом избавляя программиста от ручной настройки.

12К открытий12К показов

Google включила ИИ-анализ писем Gmail по умолчанию. Узнайте, как полностью запретить обучение Gemini на ваших письмах и отключить скрытые «умные функции»

Google Pixel получил встроенный Linux-терминал с Android 15. Пользователи могут запускать Debian в изолированной среде прямо на смартфоне

Разработчица изучила 900 open source ИИ-проектов и выявила ключевые тренды: оптимизация инференса, сжатие моделей и рост ИИ-агентов

Chrome перестал запускаться на Windows 11 с Family Safety — Microsoft считает его небезопасным, решение проблемы требует ручной настройки