«Истории» в YouTube позволяют менять фон в режиме реального времени без хромакея
Исследователи из Google разработали нейронную сеть, умеющую менять фон в кадре в режиме реального времени без дополнительного оборудования. Новинка внедрена в «Истории» YouTube в ограниченной бете для смартфонов.
Сегментация видео — популярная техника, позволяющая отделять передний план видеороликов от фона и обрабатывать их как разные визуальные слои. Благодаря ей монтажёры могут менять сцену, на которой развиваются основные события. Традиционно этот процесс производится вручную и отнимает много ресурсов. А для создания таких роликов в режиме реального времени требуется специальное студийное оборудование, включающее хромакей — зелёный фон, на который накладывается нужное изображение.
В ответ на эти сложности команда исследователей из Google разработала новую технику, с помощью которой пользователи смартфонов могут быстро путешествовать между мирами в своих видео без какого-либо дополнительного оборудования. Новинкой оснастили «Истории» в YouTube, которые на момент написания новости находятся в режиме ограниченного бета-тестирования.
Сложности разработки
Для создания этой системы потребовалось применить свёрточные нейронные сети. В частности, исследователи разработали специальную нейронную архитектуру и особую процедуру обучения, оптимально функционирующие в рамках ограничений, которые накладываются особенностями мобильных устройств:
- мобильное решение должно быть легковесным и в то же время работать в 10 — 30 раз быстрее самых современных моделей сегментации, чтобы обеспечить онлайн-отрисовку со скоростью 30 кадров в секунду;
- видеомодель должна усиливать временную избыточность (соседние кадры должны быть похожи друг на друга) и в то же время обладать временной целостностью (соседние результирующие кадры должны быть одинаковыми);
- высококачественные результаты сегментации требуют высококачественных входных данных.
Набор данных
Чтобы обеспечить модель достаточным набором данных высокого качества, исследователи собрали большую базу из десятков тысяч снимков, отображающих широкий диапазон возможных объектов переднего и заднего плана. Данные с точностью до пикселя описывали стандартное расположение элементов переднего плана: волосы, очки, кожа, губы и т.п. А общий фон по результатам перекрёстной проверки описывался практически полностью (98 % IoU).
На данный момент этот блок не поддерживается, но мы не забыли о нём!Наша команда уже занята его разработкой, он будет доступен в ближайшее время.
Перед разработчиками стояла конкретная задача: научить сеть вычислять бинарный шаблон для каждого входного кадра (по трём каналам, RGB), чтобы отделять фон от переднего плана, не теряя при этом временной целостности. Существующие подходы вроде LSTM и GRU не годились, так как требовали слишком больших вычислительных мощностей. Но исследователи нашли выход: они решили передавать уже вычисленный шаблон предыдущего кадра следующему по четвёртому каналу, «прикрученному» к уже идущему потоку RGB:
Процедура обучения
Для создания системы видеосегментации необходимо добиться непрерывности кадрового потока. В то же время нужно научить сеть обрабатывать различные неожиданные помехи (например, в поле зрения камеры внезапно появляются другие люди). Для этого набор описательных данных для каждого фото был задан тремя разными способами, чтобы сеть могла подставлять полученные кадры как шаблоны:
- пустой предыдущий шаблон обучает сеть корректно обрабатывать первый кадр и новые объекты на сцене (имитация события, когда кто-то внезапно появляется на сцене);
- аффинное преобразование шаблона обучает сеть передавать и корректировать предыдущий шаблон кадра (минорное преобразование) или выявлять и отбрасывать неподходящие шаблоны (мажорное преобразование);
- преобразованное изображение обучает сеть сглаживать оригинальный кадр для эмуляции быстрых движений камеры.
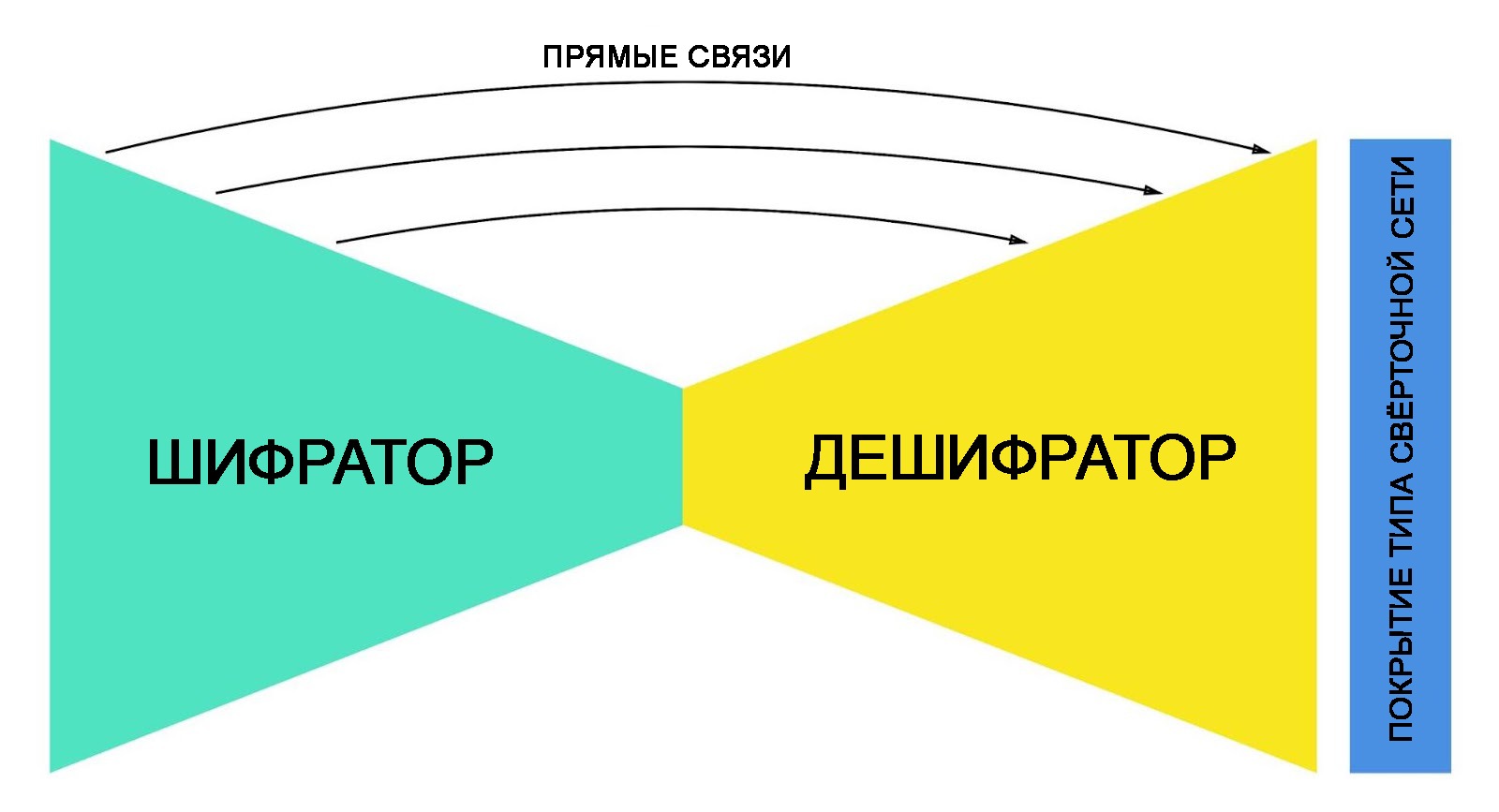
Архитектура сети
Система построена на основе архитектуры сегментации типа «песочные часы» с некоторыми улучшениями. Так, для увеличения качества обработки было принято решение использовать большие свёрточные ядра с увеличенным шагом. Для разгона модели были применены техники субдискретизации в сочетании с прямыми связями.Для пущего увеличения скорости исследователи решили применить агрессивный коэффициент сжатия. Тестирование показало, что сжатие кадров в 32 раза (в противовес принятым 4 в методологии остаточного обучения) практические не отражается на качестве результата. А точность определения контуров удалось повысить наложением на готовую модель нескольких дополнительных слоёв свёрточной сети. Благодаря этому шагу общая точность покрытия кадра выросла на 0,5 %. Несмотря на маленькую цифру, специалисты утверждают, что она серьёзно отразилась на качестве восприятия сегментации.
Результаты
В итоге исследователям удалось создать довольно быструю сеть для мобильных устройств. На iPhone 7 частота смены кадров превосходит 100, а на смартфоне Pixel 2 — 40, при этом качество покрытия кадра составляет 94,8 % IoU.

После завершения бета-тестирования Google планирует распространить новую сеть на собственные сервисы для работы с дополненной реальностью.













{kind=link}
