


Алгоритм, который генерирует целое число, отсутствующее в файле

16К открытий17К показов
Дан входной файл, содержащий четыре миллиарда целых 32-битных чисел. Предложите алгоритм, генерирующий число, отсутствующее в файле. Имеется 1 Гбайт памяти для этой задачи. Дополнительно: а что если у вас всего 10 Мбайт? Количество проходов по файлу должно быть минимальным.
В нашем распоряжении 232 (или 4 миллиарда) целых чисел. У нас есть 1 Гбайт памяти, или 8 млрд бит.
8 млрд бит — вполне достаточный объем, чтобы отобразить все целые числа. Что нужно сделать?
- Создать битовый вектор с 4 миллиардами бит. Битовый вектор — это массив, хранящий в компактном виде булевы переменные (может использоваться как int, так и другой тип данных). Каждую переменную типа int можно рассматривать как 32 бита или 32 булевых значения.
- Инициализировать битовый вектор нулями.
- Просканировать все числа (num) из файла и вызвать
BV.set(num, 1). - Еще раз просканировать битовый вектор, начиная с индекса 0.
- Вернуть индекс первого элемента со значением 0.
Следующий код реализует наш алгоритм:
Решение для 10 Мбайт памяти
Можно найти отсутствующее число, воспользовавшись двойным проходом по данным. Давайте разделим целые числа на блоки некоторого размера (мы еще обсудим, как правильно выбрать размер). Пока предположим, что мы используем блоки размером 1000 чисел. Так, blоск0 соответствует числам от 0 до 999, block1 — 1000 — 1999 и т.д.
Нам известно, сколько значений может находиться в каждом блоке. Теперь мы анализируем файл и подсчитываем, сколько значений находится в указанном диапазоне: 0-999, 1000-1999 и т.д. Если в диапазоне оказалось 998 значений, то «дефектный» интервал найден.
На втором проходе мы будем искать в этом диапазоне отсутствующее число. Можно воспользоваться идеей битового вектора, рассмотренного в первой части задачи. Нам ведь не нужны числа, не входящие в конкретный диапазон.
Как же выбрать размер блока? Давайте введем несколько переменных:
- Пусть rangeSize — размер диапазонов каждого блока на первом проходе.
- Пусть arraySize — число блоков при первом проходе. Обратите внимание, что arraySize = 232/rangeSize.
Нам нужно выбрать значение rangeSize так, чтобы памяти хватило и на первый (массив) и на второй (битовый вектор) проходы.
Первый проход: массив
Массив на первом проходе может вместить 10 Мбайт, или 223 байт, памяти. Поскольку каждый элемент в массиве относится к типу int, а переменная типа int занимает 4 байта, мы можем хранить примерно 221 элементов.
Второй проход: битовый вектор
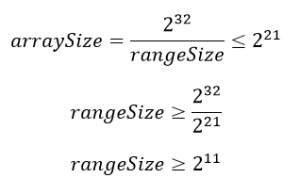
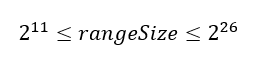
Нижеприведенный код предоставляет одну реализацию для этого алгоритма:
А что если вам нужно решить задачу, используя более серьезные ограничения на использование памяти? В этом случае придется сделать несколько проходов. Сначала пройдитесь по «миллионным» блокам, потом по тысячным. Наконец, на третьем проходе можно будет использовать битовый вектор.
Разбор взят из перевода книги Г. Лакман Макдауэлл и предназначен исключительно для ознакомления.Если он вам понравился, то рекомендуем купить книгу «Карьера программиста. Как устроиться на работу в Google, Microsoft или другую ведущую IT-компанию».

16К открытий17К показов

GPU для бизнеса: окупаемость и выбор стратегии. Расчет ROI, сравнение CAPEX vs OPEX для AI, рендеринга и HPC. Аренда мощностей NVIDIA V100/P100.