


Японская головоломка KenKen: разбор задачи и алгоритм автоматической генерации таблиц

Разбор правил головоломки KenKen, её решение, а также пример программной реализации.
9К открытий12К показов

Дмитрий Беляев
Perl-разработчик хостинг-провайдера и регистратора доменов REG.RU
Мои критерии интересной задачи:
- Она, попав в голову, осталась там надолго, даже получив своё решение.
- К ней интересно мысленно возвращаться в минуты скуки или творческого настроения.
- Целью задачи не должен быть лишь правильный ответ (поэтому школьные, олимпиадные или задачки с собеседований лично для меня редко становятся любимыми). Мне нравится когда задача — некий процесс творения.
- Задача должна быть как-то связана с реальностью. Или с тем, чем я мог бы заниматься в реальности, пусть даже играя. Я бы вряд ли крутил в голове задачу из разряда «У Пети есть неубывающий массив натуральных чисел, а вы ему завидуете и с помощью XOR-пушки хотите его разрушить…».
- У неё не должен быть слишком высокий порог входа, чтобы она помещалась в оперативку в голове и не переполняла стек.
При этом очень важно не гуглить решение, чтобы не спугнуть интерес. Именно в придумывании разнообразных вариантов решения и состоит всё удовольствие, пусть даже я изобретаю велосипед.
Такие задачи часто нас окружают, важно их заметить, что можно сравнить с тем, как идеи должны находить изобретателя. Очередной случай произошёл спонтанно, когда я объяснял одному моему товарищу правила решения головоломки KenKen. Разобраться в них довольно непросто, сам я сделал это только с третьего раза, когда мне объясняли правила мои дети.
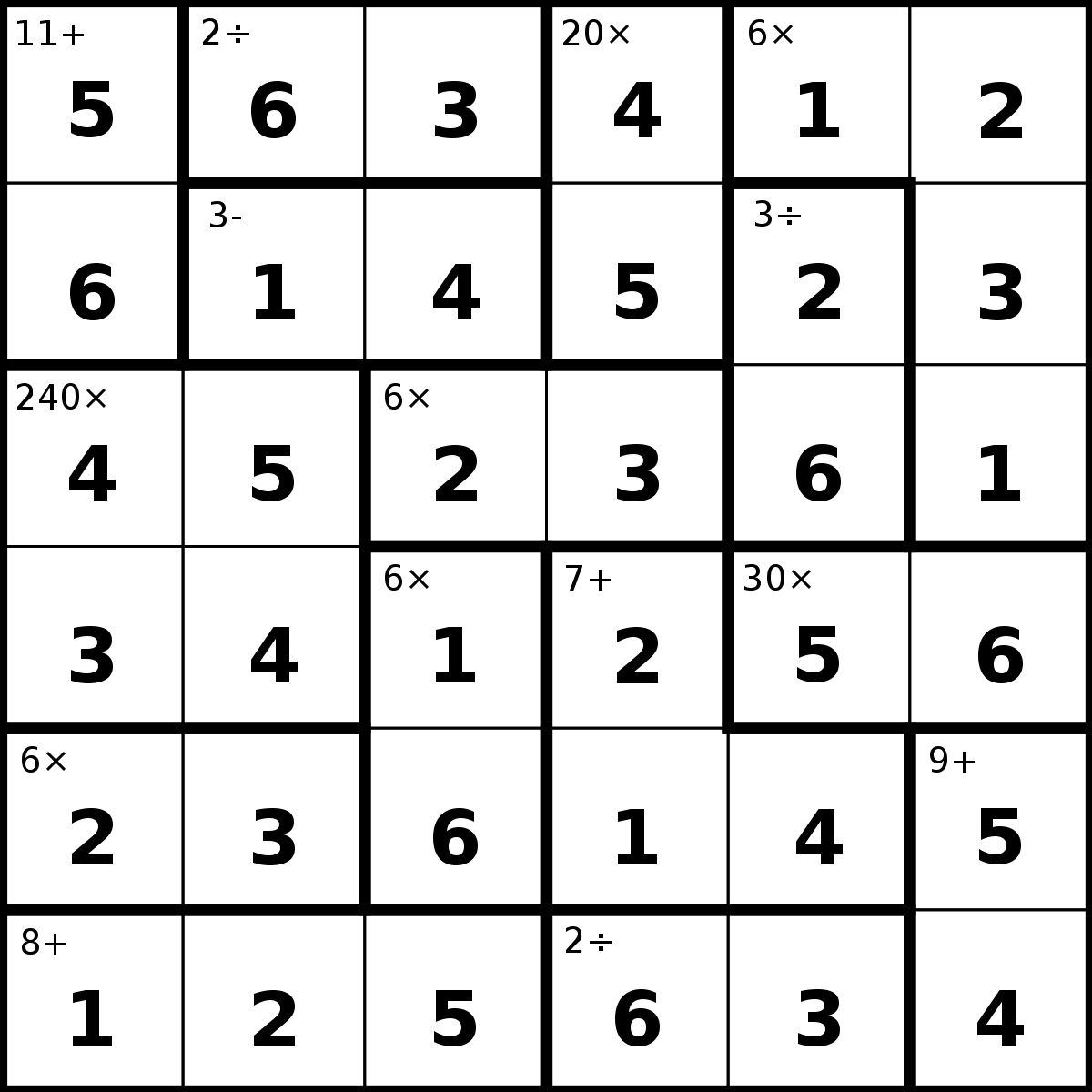
KenKen — это таблица с одинаковым числом клеток в рядах и колонках, которую нужно заполнить цифрами, используя только цифры от единицы до N, где N — количество ячеек в одном из рядов таблицы. При этом нужно, чтобы, во-первых, ни в одной отдельно взятой строке и ни в одном отдельно взятом столбце числа не повторялись. Во-вторых, в обведённых жирными линиями группах ячеек результат математической операции, произведённой над всеми ячейками группы, должен совпадать с требуемым результатом.
Требуемый результат записывается как условие в левом верхнем углу одной из ячеек мелким шрифтом в виде числа, а операция — в виде знака математической операции.
Так, если, например, жирным обведены две ячейки вместе, а в уголке написано «6x», это значит, что мы должны получить результат равный шести путем умножения ячеек друг на друга. Варианты заполнения ячеек будут такие: 3 и 2 или 6 и 1. Но если мы еще раньше пришли к выводу, что в одной ячейке должно стоять 6, то во второй ячейке остаётся поставить только 1.

Поначалу товарищ никак не мог ухватить суть правил, тогда я сказал: «Чтобы понять, как они устроены, давай составим собственный KenKen, как если бы его решать потом не нам, а кому-то другому. Следи за руками».
Дальше расчертил квадрат на клетки, расставил числа так, чтобы сохранялась уникальность в рядах и колонках.
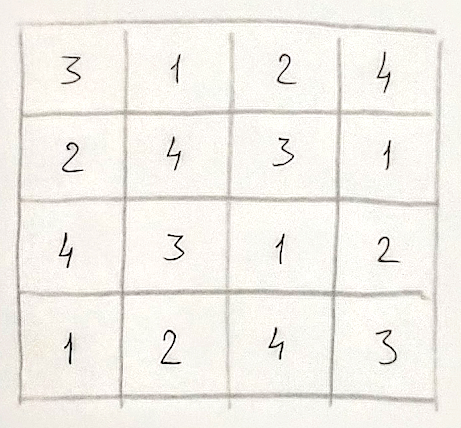
Потом случайным образом обвёл некоторые ячейки, группируя их по две-три, обвёл жирной линией. Получился квадрат, сложенный из эдаких кривых доминошек.
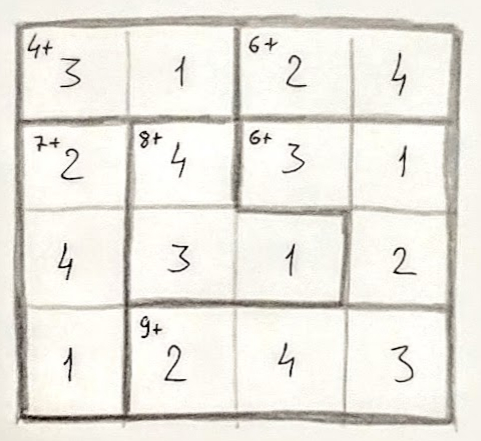
Потом в углу каждого такого домино поставил цифру, равную сумме цифр в ячейках в обведённой области. Для простоты объяснения я использовал только операцию сложения. Мы оба убедились, что полученный таким образом KenKen выполняет все правила решённого. Потом я стёр цифры в ячейках, чтобы тот кому достанется решать, не знал ответа заранее.
Как только я это объяснил другу, тут же и сам всё понял: это же алгоритм автоматической генерации KenKen! Я мог бы создать сайт, на котором любой желающий может решать бессчётное количество автоматически созданных KenKen. Вот она задачка!
Первое, что интересно в ней — сам алгоритм формирования головоломки, а не веб-программирование, как таковое. Второе — как программа в процессе заполнения ее пользователем будет определять, решён KenKen или нет? Третье — уже совершенно новая задача: может ли другая программа решить такой KenKen, сгенерированный другой программой?
Я знаю, что задача уже решена до меня, стоит только погуглить, но я этого не делаю. В ней нет единственного правильного ответа: все варианты хороши, если они работают, и это мне нравится. Но если какой-то алгоритм будет генерировать более интересные головоломки KenKen, чем другой, то я выберу лучший.
Поэтому, решив её однажды, не спешу выбрасывать задачку из головы. Более того, я её запрограммировал, не смог удержаться. Это были две недели удовольствия по вечерам. У этой задачки нет заумных формул и она меня не подвешивает в «параличе разработчика». Я знаю как использовать такой алгоритм на практике. И наконец, я знаю, кто и зачем может воспользоваться этим алгоритмом. Важно, что занимаясь этим, можно одновременно и отдыхать, и развлекаться, и развиваться
Решение задачи
Заполняем заготовку KenKen числами с сохранением уникальности в рядах и колонках
Пусть N — это число ячеек в одном ряду/колонке KenKen.
Можно заметить правило: в любом ряду или колонке должны присутствовать по одному разу все числа от 1 до N.
Как это доказать? Разрешено использовать числа от 1 до N. Если в ряду длиной N отсутствует вхождение какого-либо из чисел от 1 до N, то на его место придётся вставить другое число от 1 до N, а это будет повторением одного из уже присутствующих в ряду чисел. К примеру, в ряду 1, 2, 3 если убрать 2, то на его место придется поставить или 1, или 3.
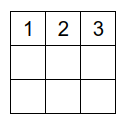
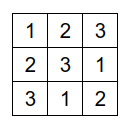
Простейший ряд для KenKen, при N=3 — это: [ 1, 2, 3 ]. (см. рис. ниже).
Второй ряд, чтобы обеспечить уникальность в колонках может быть циклически смещен относительно первого. Простейший случай — смещение на 1 шаг: 2, 3, 1:

Третий ряд — на два шага относительно первого ряда: 3, 1, 2:
Перемешивание первого ряда
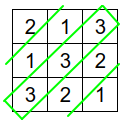
Если первый ряд во всех KenKen будет возрастающей последовательностью от 1 до N, то даже ребёнок быстро сообразит, в чём тут система.
Чтобы добавить KenKen непредсказуемости, первый ряд можно перетасовать случайным образом: из [ 1, 2, 3 ] он может превратиться в [ 2, 1, 3 ]:

Второй и последующие ряды уже не тасуем — просто берем первый ряд и делаем относительно него циклические смещения, как это было описано выше:

Перемешиваем сдвиг
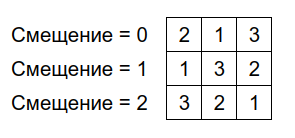
Постоянный сдвиг рядов тоже даёт картину с явно выраженной закономерностью:
Как варьировать сдвиг очередного ряда?
Ряды можно сдвигать и случайным образом, главное, чтобы ни один ряд не был сдвинут на одинаковое количество шагов относительно какой-то точки отсчёта. Мы могли бы для каждого ряда получать случайное число сдвига в пределах от 0 до N-1, а потом проверять, не было ли уже такого сдвига в предыдущих рядах, но можно сделать проще.
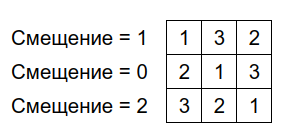
По-математически обобщая, можно сказать, что все ряды так или иначе смещены: третий ряд смещён на два шага относительно первого, второй ряд — на один шаг, а первый ряд — на ноль шагов. То есть смещения рядов от верхнего к нижнему можно описать последовательностью [ 0,1,2 ], или обобщённо: для KenKen размерностью N: [ от 0 до N-1 ] (см. рис. ниже).
Чтобы варьировать смещения рядов, достаточно перетасовать случайным образом последовательность смещений и уже потом идти по ней в цикле, сдвигая каждый следующий ряд на текущее значение смещения.
Теперь количество шагов смещения для каждого последующего ряда относительно предыдущего будет вариабельным. (см. рис. ниже).
Заполняем KenKen правилами
Как мы помним, на KenKen накладываются правила заполнения.
Можно выделить две группы правил:

1. Общие — это уникальность в рядах и колонках
2. Частные правила, которые меняются от одного KenKen к другому: это, к примеру, ячейки (1,1) и (1,2) должны в сумме давать 4

Любое правило, и общее и частное, распространяется на конкретный список ячеек, применяет к ним некую операцию и сверяет полученный результат с ожидаемым результатом.
Примем за обозначение координат запись (row,col), где row — номер ряда сверху, а col — номер колонки слева. Запись (1,3) будет означать «ряд 1, колонка 3».
Так, например, правило уникальности первого ряда в KenKen размерностью N условно формально можно выразить так:
ячейки: [ (1,1), (1,2), (1,3) ]; операция: уникальность; ожидаем: истину.
Аналогично и для остальных рядов и ячеек.
Частное правило можно выразить, например, так:
ячейки:[ (1,1), (1,2) ]; операция: сумма; ожидаем: 4.
Вот пример полного списка правил для (уже заполненного по правилам и решённого) KenKen, нарисованного ниже:
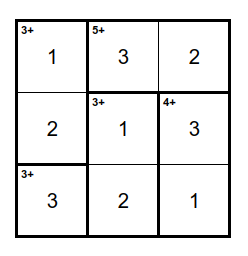
Теперь понятно, к чему мы стремимся, но пока список правил мы еще не составили.
Составить список общих правил очевидно легко: для этого нужно лишь знать размерность KenKen, считаем, что мы это сделали.
Начнём заполнять KenKen частными правилами, предполагая, что цифры в ячейках уже расставлены, как это было описано выше. Выбираем случайную ячейку в пределах KenKen. Решаем, на какое количество ячеек распространять это правило.
На какое количество ячеек распространять правило?
Минимум = 1, а максимум — сколько? Глядя на разные KenKen, можно увидеть, что обычно частное правило распространяется не более чем на длину одной стороны, а чаще — на ещё меньшее число ячеек. Можно взять максимум равный int( N / 2 ) + 1. Для кенкена N=3 максимум будет равен 2, для N=4 максимум = 3, для N=5 максимум = 3.
Как распространить правило на K ячеек?
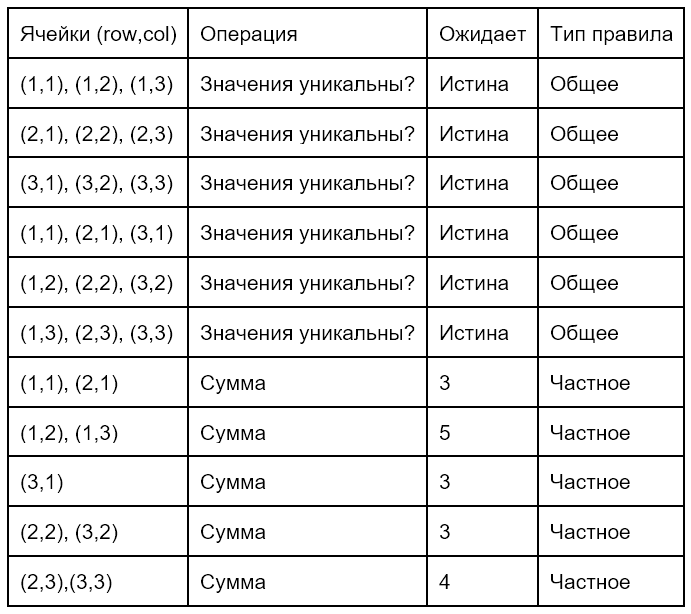
Пусть K — количество ячеек, на которое мы хотим распространить правило. Случайная стартовая ячейка уже выбрана. Смотрим на ячейку справа от текущей, если она не занята каким-либо правилом и если она находится в пределах KenKen, то включаем её в текущее правило.
См. рис. ниже, где стартовой ячейкой является ячейка (2,2) (центральная):
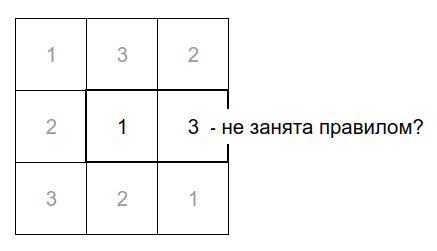
Если она занята или вне пределов KenKen, то смотрим на соседнюю снизу ячейку по отношению к текущей ячейке:
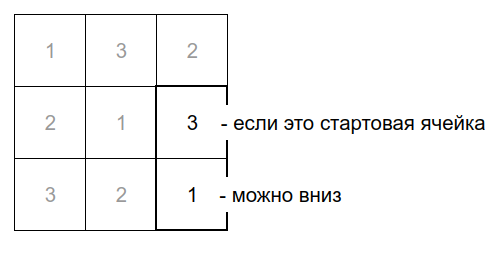
Если и тут нет — то на соседа слева и потом на соседа сверху. Так до тех пор, пока не наберётся K ячеек для правила или пока не будет отрицательного ответа по всем четырём направлениям.
Как только распространение правила остановилось — считаем общую сумму значений в ячейках и записываем в ожидаемый результат. В нашем случае мы решили, что максимум количества ячеек для правила будет равен 2, значит остановимся после заполнения двух ячеек. Например, так:
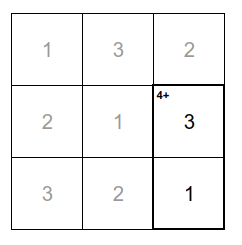
Заполняем остальные частные правила
С какой ячейки начать следующее частное правило? Если опять выбирать случайную ячейку из всего KenKen, то есть вероятность попасть в ячейку, принадлежащую другому правилу. Можно взять первую ячейку из списка ячеек, не включённых в частные правила или что лучше: взять случайную ячейку из списка ячеек, которые не включены в частные правила. Распространяем правило так же, как описано выше.
Продолжаем добавлять частные правила, пока в KenKen есть ячейки, не включённые ни в одно частное правило:
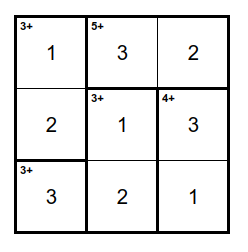
Остаётся стереть числа из ячеек и KenKen готов, за исключением некоторых мелочей, которые к задаче генерации отношения не имеют, но имеют отношение к задаче его отрисовки. Так, в KenKen в одиночной ячейке обычно не пишут правило, а сразу ставят число, но мы сейчас не занимаемся отображением KenKen, а представляем его структуру.
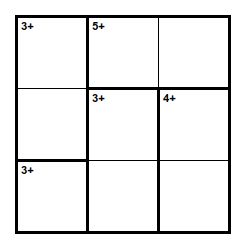
Что если будут другие операции, кроме суммы?
Хороший KenKen имеет, кроме суммы, ещё операции умножения, вычитания и деления. Рассматривая KenKen, можно обратить внимание, что операции суммы и умножения охватывают разное количество ячеек, а операции деления и вычитания всегда охватывают ровно две ячейки. Этому есть объяснение: применение операции вычитания или деления к трём и более ячейкам создает неоднозначность при решении. Если это так, то придётся каждой операции поставить в соответствие количество ячеек, к которому она может быть применена.

Также можно заметить, что, например, операцию деления нельзя использовать, если значения не делятся нацело. К примеру, нельзя применить деление к ячейкам со значениями 2 и 3. Поэтому, каждой операции можно поставить в соответствие функцию проверки её применимости к списку значений. Например, для операции деления такая функция возвращает истину только если в списке значений два элемента, и если деление большего на меньшее не дает остатка.
Каков алгоритм выбора операции для следующего частного правила?
Как сказано выше, когда мы распространяем частное правило на ячейки KenKen, нет гарантии, что мы найдем нужное количество ячеек для данного правила. Как быть?
С точки зрения программиста, можно поместить все операции в список: сначала самые требовательные к количеству ячеек и их значениям (деление), в конце — самые нетребовательные (сумма).

Итак, после того, как мы распространили частное правило на K ячеек: при выборе операции для частного правила идти от самых требовательных операций к менее требовательным. На каждом шаге проверить применимость операции к значениям ячеек, на которые удалось распространить правило и, если применить нельзя, то переходить к следующему (менее требовательному) правилу. В худшем случае мы упрёмся в первую операцию, которая примет любой список значений. Значит, нужно, чтобы такая операция всегда присутствовала и была последней.
Как можно ещё улучшить выбор операции?
Если операцию умножения никак не ограничивать, то для KenKen размером 6х6 можно получить правило умножения с ожидаемым результатом, равным 720 (6*5*4*3*2). В KenKen огромных чисел обычно не делают.
Вторая причина ограничить умножение — если эта операция будет нетребовательна, то она будет слишком часто встречаться в KenKen.
Возможно, функцию применимости умножения придётся доработать, добавив в неё некий максимум ожидаемого результата:

В целом, описанный алгоритм заполнения KenKen частными правилами может быть улучшен во многих местах. Критерием качества, думаю, может быть то, насколько интересным и сбалансированным получается сгенерированный KenKen.
Существуют ли KenKen, допускающие более одного варианта решения?
Да, если правила недостаточно жестко накладывают ограничения на значения.
Вопрос, на который я еще не нашёл ответа: как убедиться, что сгенерированный KenKen имеет одно решение?
Что должна уметь делать программа, кроме генерации KenKen?
Как программа поймет, когда KenKen решён?
Вот пользователь заполняет ваш KenKen, и если только он не распечатал его на бумаге, то программа в состоянии оповестить его, когда KenKen решён. Как это сделать?
Мы говорили, что есть общие и частные правила. Любое правило может либо выполняться, либо быть нарушенным. Для проверки нарушенности правило применяется к ячейкам, на которые оно распространяет свою операцию и сравнивает результат с ожидаемым результатом. Объединяем правила в один список и выбираем из списка те правила, которые нарушены. Если полученный список пуст — то ни одно правило не нарушено, и значит KenKen решён.
Что потребуется программе, изображающей сгенерированный KenKen?
Программа, изображающая KenKen, скорее всего, будет поочередно перебирать ячейки слева-направо и сверху вниз, и отрисовывать каждую ячейку.
Для того чтобы нарисовать ячейку, программе нужно знать, какие из её сторон рисовать простой линией, а какие — жирной линией. Простые линии разделяют ячейки внутри одного частного правила. Жирные линии — границы между частными правилами, а также границы всего KenKen.
В какой ячейке из охваченных частным правилом печатать собственно само правило? Т.е. где печатать «5+» или «6*» ? Ответ: из всех ячеек, охваченных правилом, можно выбрать самую верхнюю, а если верхних несколько, то потом самую левую.
Нужно помнить, что на общих правилах (требующих уникальность в рядах и столбцах) никаких правил не пишется. То есть не нужно в начале каждого ряда писать, что-то вроде «истина, уникальность с (1,1) по (1,3)». И общие правила не обводятся жирными границами.
Откуда программа знает, каким знаком закодировать операции в частных правилах? Например, откуда она знает, что если операция — «сумма», то в правиле нужно напечатать знак «+» ? Можно поставить в соответствие каждой операции — символ, которым она обозначается в правиле.
Закладываем фундамент на будущее
Помните, был вопрос о том, сможет ли программа решить KenKen? Уверен, что да, но как — я пока не знаю. Но понятно, что, как минимум, программа должна уметь получить KenKen в каком-то формате, в виде входных данных и уметь перевести его в своё внутреннее представление. Соответственно, понадобятся функции сериализации KenKen в этот формат (для генерирующей программы) и десериализации его (для решающей). Формат JSON вполне подходит.
Программирование
Важно отметить — задача запрограммирована не на языке Perl. Это связано с тем, что, с точки зрения автора, подобный код удобнее писать на статически-типизированном языке, так что ни Perl, ни Python, ни другой динамический язык не будут удобными для этой задачи.
Также хотелось написать универсальную библиотеку, которую потом можно использовать и в консольных, и в десктопе, и в одностраничных веб-приложениях (даже для мобильных). В Dart это всё возможно, поэтому выбор был очевиден.
Программирование задачи можно найти здесь, а пример использования — в этом файле.

9К открытий12К показов

Продолжаем нашу серию о хакерах и тайнах программирования. Сегодняшние пациенты — Cicada 3301.

Программист с 40-летним опытом проверил ChatGPT и другие ИИ в разработке: ИИ ускоряет работу и вдохновляет, но не заменяет опыт инженера