


6 шагов по созданию проектов машинного обучения

Статья расскажет, как приступить к созданию проекта с машинным обучением. Какие данные необходимо собирать, как правильно моделировать и развёртывать.
30К открытий33К показов
Машинное обучение — обширная тема, а медиа ещё и представляют его как волшебство. Цель этой статьи — изменить ваше представление о машинном обучении. Вы познакомитесь с кратким обзором наиболее распространённых задач, которые можно решить с его помощью.
Сначала разберёмся с некоторыми определениями.
Чем отличаются машинное обучение, искусственный интеллект и наука о данных?
Эти три темы могут быть трудными для понимания, потому что формальных определений нет. Я проработал инженером по машиностроению больше года, и у меня до сих пор нет точного ответа на этот вопрос.
Чтобы избежать путаницы, будем говорить простыми словами. В этой статье вы можете рассматривать машинное обучение как процесс поиска шаблонов в данных с целью понять общую картину или предсказать какое-то будущее событие.
Проходя эти 6 шагов, мы будем учиться в процессе: выполнять построение чего-то или наблюдать, как это работает.
6 шагов по созданию вашего следующего проекта
Конвейер машинного обучения можно разбить на три основных этапа: сбор данных, моделирование и развёртывание. Все они влияют друг на друга.
Вы можете начать проект со сбора данных, затем смоделировать их, понять, что собранных данных недостаточно, и вернуться к сбору, смоделировать данные снова, найти хорошую модель, развернуть её, обнаружить, что она не работает, создать другую модель, развернуть и её, обнаружить, что она тоже не работает, и вернуться к сбору данных. Это целый цикл.
Что значит модель? Что такое развёртывание? Как собирать данные?
Способ сбора данных будет зависеть от вашей задачи. Например, можно собирать в таблицу списки покупок ваших клиентов.
Под моделированием понимается использование алгоритма машинного обучения для поиска информации в собранных вами данных.
В чём разница между обычным алгоритмом и алгоритмом машинного обучения?
Как и рецепт приготовления вашего любимого блюда, обычный алгоритм — это набор инструкций о том, как превратить набор ингредиентов в шедевр.
Отличительная особенность алгоритма машинного обучения заключается в том, что вместо набора инструкций вы начинаете с ингредиентов и готового блюда. Затем алгоритм рассматривает ингредиенты и финальное блюдо и разрабатывает набор инструкций.
Есть много различных типов таких алгоритмов, некоторые из них работают лучше других, но у всех них одна цель — найти шаблоны или наборы инструкций в данных.
Развёртывание берёт ваш набор инструкций и использует его в приложении. Это приложение может делать что угодно — от рекомендаций продуктов в вашем интернет-магазине до сервиса для больницы, пытающегося лучше предсказать наличие заболевания.
Когда вы будете применять эти шаги для своего проекта, они могут немного меняться в зависимости от специфики, но принципы будут схожими.
Эта статья посвящена моделированию данных. Предполагается, что вы уже собрали данные и хотите с их помощью получить прототип проекта с машинным обучением. Разберёмся, как вы можете подойти к этому.

- Определение задачи — какую бизнес-проблему вы пытаетесь решить? Как это можно сформулировать в виде задачи машинного обучения?
- Данные — какие данные у вас есть? Как это соответствует определению задачи? Данные структурированы или нет? Данные статические или потоковые?
- Оценка — что определяет успех? Достаточно ли хороша модель машинного обучения с точностью 95 %?
- Особенности — какие части данных будут использованы для модели? Как может то, что уже известно, повлиять на это?
- Моделирование — какую модель выбрать? Как вы можете улучшить модель? Как вы сравниваете это с другими моделями?
- Эксперименты — что ещё можно попробовать? Развёрнутая модель работает так, как ожидалось? Как другие шаги меняются в зависимости от того, что вы обнаружили?
Рассмотрим немного подробнее каждый пункт.
Шаг первый: определение задачи — перефразируйте свою задачу как задачу машинного обучения
Чтобы понять, может ли ваш бизнес использовать машинное обучение, первым делом нужно сопоставить решаемую бизнес-проблему с задачей машинного обучения.
Четырьмя основными типами машинного обучения являются: контролируемое обучение (обучение с учителем), неконтролируемое обучение (обучение без учителя), трансферное обучение и обучение с подкреплением (также есть частичное обучение, но его мы не рассматриваем). В бизнес-приложениях чаще всего используются контролируемое, неконтролируемое и трансферное обучение.
Контролируемое обучение
Оно называется так, потому что у вас есть данные и метки. Алгоритм машинного обучения пытается выяснить, какие шаблоны данных приводят к меткам. Контролируемая часть происходит во время тренировки. Если алгоритм угадывает неправильную метку, он пытается исправиться.
Например, вы пытаетесь предсказать болезнь сердца у нового пациента. В качестве данных вы можете использовать анонимные медицинские карты 100 пациентов и указывать, есть ли у них заболевание сердца.
Алгоритм машинного обучения может посмотреть на медицинские записи (входные данные) и определить, имел ли пациент заболевание сердца (выходные данные), а затем выяснить, какие закономерности в медицинских записях приводят к заболеванию сердца.
После того как вы получили обученный алгоритм, вы можете просмотреть через него карту (входные данные) нового пациента и получить прогноз, есть ли у него сердечные заболевания (выходные данные). Важно помнить, что этот прогноз не совсем верный. Он возвращается лишь как вероятность.
Алгоритм говорит: «Исходя из того, что я видел раньше, похоже, что медицинские записи нового пациента на 70 % совпадают с теми, у кого есть болезнь сердца».
Неконтролируемое обучение
Неконтролируемое обучение — это когда у вас есть данные, но нет меток. Например, данными могут быть истории покупок клиентов в онлайн-магазине видеоигр. Используя эти данные, можно объединить схожих клиентов, чтобы предложить им специальные условия. Можно использовать алгоритм машинного обучения для группировки клиентов по истории покупок.
После проверки групп создаются метки. Групп может быть множество: одна заинтересована в компьютерных играх, другая предпочитает консольные игры, а третья состоит из покупателей более старых игр со скидкой. Это называется кластеризацией.
Важно помнить, что алгоритм не предоставляет метки. Он находит шаблоны между похожими клиентами и, используя знания предметной области, вы сами сопоставляете эти метки.
Трансферное обучение
Трансферное обучение — это когда вы берёте информацию, которую уже изучила существующая модель машинного обучения, и адаптируете её к своей задаче.
Обучение модели с нуля может быть дорогостоящим и трудоёмким. Хорошо, что это не всегда необходимо. Когда алгоритмы машинного обучения находят шаблоны в одном виде данных, эти шаблоны могут использоваться и в другом виде.
Допустим, компании по страхованию автомобилей нужно создать модель текстовой классификации, определяющую, виновен ли человек, подающий запрос на страховое возмещение (если он спровоцировал аварию) или нет (если не спровоцировал).
Вы можете начать с существующей текстовой модели, которая прочитала всю Википедию и запомнила все паттерны между разными словами. Например, проанализировала, какое слово с большей вероятностью будет следовать за другим. Затем, используя заявления пострадавших на страховые выплаты (данные) вместе с их результатами (метками), можно настроить существующую текстовую модель под свою проблему.
Если в бизнесе можно использовать машинное обучение, скорее всего, оно подпадает под один из этих трёх типов обучения.
Разберём их дальше в классификации, регрессии и рекомендации.
- Классификация — определение чего-либо в одну или другую категорию. Например, будет ли отток клиентов или нет? Есть ли у пациента болезнь сердца или нет? Обратите внимание, что категорий может быть больше, чем две. Два класса — бинарная классификация, более двух классов — мультиклассовая классификация. Мульти-метка — это когда элемент может принадлежать более чем одному классу.
- Регрессия — определение конкретного числа чего-либо. Например, за сколько будет продаваться дом? Или сколько клиентов посетит ваш сайт в следующем месяце?
- Рекомендация — совет для кого-либо. Например, продукты для текущей покупки на основе предыдущих или статьи для ознакомления на основе истории чтения.
Следующий шаг — определить бизнес-задачу в терминах машинного обучения.
Вернёмся к примеру компании по страхованию автомобилей. Она получает в день тысячи запросов, которые читают сотрудники. Они решают, виновен человек или нет.
Теперь запросы начинают поступать чаще, чем ваши сотрудники могут их обработать. Зато у вас есть тысячи прошлых обработанных заявлений с определёнными пометками.
Может ли здесь помочь машинное обучение?
Ответ в принципе известен, но рассмотрим подробнее. Эта проблема вписывается в любой из трёх типов выше? Классификация, регрессия или рекомендация? Перефразируем.
«Мы — компания по страхованию автомобилей, которая хочет классифицировать входящие страховые претензии по виновности/невиновности.»
Наличие слова «классифицировать» поможет определить тип наверняка. Но определение задачи в терминах машинного обучения потенциально может быть проблемой при выборе одного из типов. Потенциально, потому что есть шанс, что это может не сработать.
Когда дело доходит до определения вашей бизнес-задачи как задачи машинного обучения, начните с простого: формулировка задачи должна занимать не более одного предложения. Усложняйте лишь по мере необходимости.
Шаг второй: данные — какие данные у вас есть?
Данные, которые у вас есть или которые вы соберёте, будут зависеть от задачи, которую вы хотите решить.
Если у вас уже есть данные, скорее всего, они будут в одной из двух форм: структурированные или неструктурированные. Внутри каждой из них есть статические или потоковые данные.
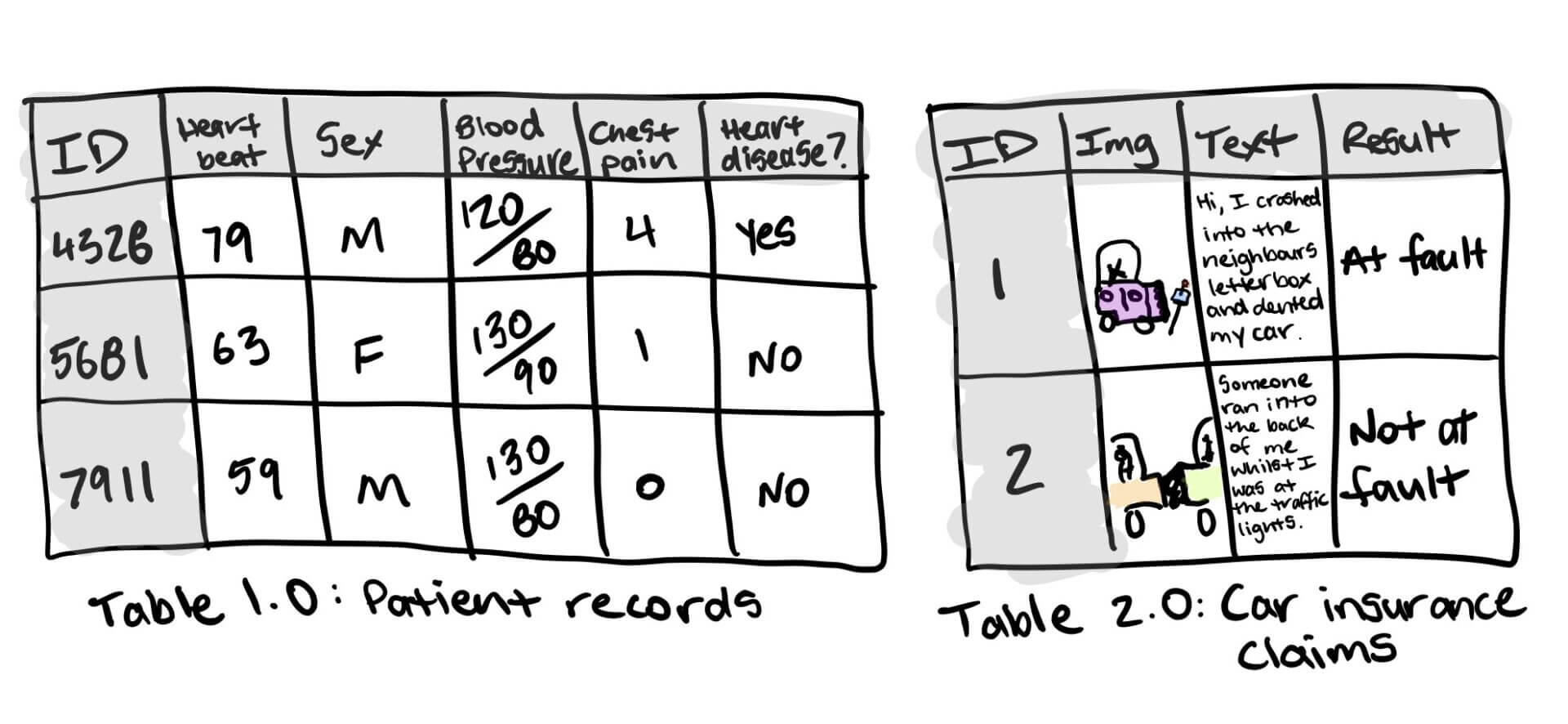
- Структурированные данные — представьте себе таблицу строк и столбцов, электронную таблицу транзакций клиентов, базу данных записей пациентов. Столбцы могут быть числовыми вроде средней частоты сердечных сокращений, категориальными вроде пола человека или порядковыми вроде интенсивности болей в груди.
- Неструктурированные данные — всё, что не может быть сразу помещено в формат строки и столбца: изображения, аудиофайлы, текст на естественном языке.
- Статические данные — существующие исторические данные, которые вряд ли изменятся. Хороший пример — история покупок.
- Потоковые данные — данные, которые постоянно обновляются, старые записи могут быть изменены, новые записи постоянно добавляются.
Стоит отметить, что здесь могут быть перекрещивающиеся типы данных.
Статическая структурированная информационная таблица может иметь столбцы, которые содержат текст на естественном языке и фотографии, и при этом постоянно обновляться.
Для прогнозирования сердечных заболеваний один столбец может содержать пол, другой — средний сердечный ритм, третий — среднее артериальное давление, четвёртый — интенсивность боли в груди.
Для примера со страховым возмещением один столбец в таблице может быть с текстом, отправленным клиентом в заявлении, другой столбец может быть с изображением, которое он отправил вместе с текстом, и в последнем столбце — результат иска. Эта таблица ежедневно обновляется новыми заявками или изменёнными результатами старых заявок.
Принцип сохраняется. Вы хотите использовать данные, которые у вас есть, чтобы получить понимание общей картины или прогноз чего-либо.
Для контролируемого обучения это включает в себя использование переменных особенностей для прогнозирования целевых переменных. Переменной особенностей для прогнозирования заболеваний сердца может быть пол, а целевой — прогноз, есть ли у пациента болезнь сердца.

При неконтролируемом обучении у вас не будет меток. Но всё ещё нужно найти шаблоны. А значит будет использоваться группировка похожих образцов и поиск образцов, которые отличаются.
Трансферное обучение — это то же контролируемое обучение, за исключением того, что вы используете алгоритмы машинного обучения для шаблонов, извлечённых из других источников данных, отличных от ваших собственных.
Помните, что, если вы используете данные о клиентах для улучшения своего бизнеса или для предоставления им более качественного сервиса, важно сообщить им об этом. Вот почему вы часто видите всплывающие окна «этот сайт использует куки». Веб-сайт собирает информацию о том, как вы просматриваете сайт, вероятно, наряду с этим использует машинное обучение, чтобы улучшить предложение.
Шаг третий: оценка — что определяет успех? Достаточно ли хороша модель машинного обучения с точностью 95 %?
Допустим, вы определили задачу своего бизнеса в терминах машинного обучения и у вас есть данные. Теперь нужно выяснить, что определяет успех.
Существуют различные метрики оценки для задач классификации, регрессии и рекомендаций. Какую из них вы выберете, будет зависеть от вашей цели.
Перефразируем.
«Чтобы этот проект был успешным, модель должна быть точной более чем на 95 % в том, что кто-то виноват в аварии или нет.»
Модель с точностью 95 % может показаться довольно хорошей для предсказания виноватого в страховом иске. Но для прогнозирования сердечно-сосудистых заболеваний вы, вероятно, захотите более точных результатов.
Есть и другие вещи, которые нужно принять во внимание при классификации задач.
- Ложное отрицательное срабатывание — модель прогнозирует отрицательный вариант, а на самом деле он положительный. В некоторых случаях, таких как прогнозирование спама в электронной почте, ложные срабатывания не так уж и страшны. Но будет гораздо хуже, если система компьютерного зрения для автомобилей с автопилотом не распознает пешехода, когда на самом деле он есть.
- Ложное положительное срабатывание — модель предсказывает положительный вариант, а на самом он отрицательный. Если человеку предскажут болезнь сердца, от которой он на самом деле не страдает, может показаться не таким уж страшным. Лучше перестраховаться, верно? Нет, если это отрицательно влияет на образ жизни человека или устанавливает для него план лечения, в котором он не нуждается.
- Истинное отрицательное срабатывание — модель прогнозирует отрицательный вариант, который на самом деле таковым и является. Это хорошо.
- Истинное положительное срабатывание — модель предсказывает положительный вариант, который на самом деле таковым и является. Это тоже хорошо.
- Точность — какая доля положительных прогнозов была правильной? Модель, которая не даёт ложных срабатываний, имеет точность 1.0.
- Полнота — какая доля фактических положительных вариантов была предсказана правильно? Модель, которая не даёт ложных отрицательных вариантов, имеет отзыв 1.0.
- Оценка F1 — сочетание точности и полноты. Чем ближе к 1.0, тем лучше.
- Кривая рабочих характеристик приёмника (ROC) и площадь под этой кривой (AUC) — кривая ROC представляет собой график, сравнивающий соотношение истинных положительных и ложных положительных вариантов. Метрика AUC — это площадь под кривой ROC. Модель, чьи прогнозы на 100 % неверны, имеет AUC 0.0, а модель, чьи прогнозы являются 100 % правильными, имеет AUC 1.0.
Для задач регрессии (где необходимо предсказать число), допустим, если вы хотите минимизировать разницу между тем, что предсказывает ваша модель, и тем, что является фактическим значением. Если вы пытаетесь предсказать цену, по которой дом будет продаваться, вы захотите, чтобы ваша модель максимально приблизилась к фактической цене. Для этого используйте MAE или RMSE.
Средняя абсолютная ошибка (MAE) — средняя разница между предсказаниями вашей модели и фактическими числами.
Среднеквадратичная ошибка (RMSE) — квадратный корень из среднего квадратов разностей между предсказаниями вашей модели и фактическими числами.
Используйте RMSE, если хотите, чтобы большие ошибки были более значительными. Например, иметь предсказание о продаже дома по цене 300 000 долларов вместо 200 000 и быть лишенным 100 000 долларов более чем вдвое хуже потери 50 000 долларов.
Проблемы с рекомендациями сложнее проверить экспериментально. Один из способов сделать это — взять часть ваших данных и спрятать их. Когда ваша модель построена, используйте её, чтобы предсказать рекомендации для скрытых данных и посмотреть, как они выстраиваются.
Допустим, вы пытаетесь рекомендовать покупателям продукты в своём интернет-магазине. У вас есть архивные данные о покупках за 2010–2019 гг. Вы можете построить модель на основе данных за 2010–2018 гг., а затем использовать её для прогнозирования покупок в 2019 г. Тогда это становится проблемой классификации, потому что вы пытаетесь определить, может ли кто-то купить что-либо.
Однако традиционные метрики классификации не лучший вариант для задач с рекомендациями. Точность и полнота не имеют понятия порядка.
Если ваша модель машинного обучения вернула список из 10 рекомендаций, которые будут показаны клиенту на вашем веб-сайте, вы бы хотели, чтобы лучшие из них отображались первыми, верно?
Точность @ k (точность до k) — то же, что и обычная точность, однако вы выбираете отсечение k вариантов. Например, точность 5 означает, что вам важны только 5 лучших рекомендаций. У вас может быть 10 000 продуктов, но вы не можете рекомендовать их всем своим клиентам.
Для начала у вас может не быть точной цифры для каждого из них. Но зная, на какие метрики вы должны обращать внимание, вы получите представление о том, как оценить ваш проект машинного обучения.
Шаг четвёртый: особенности — какие особенности есть в ваших данных и какие вы можете использовать для построения своей модели?
Не все данные одинаковы. И когда кто-то ссылается на особенности, они в свою очередь ссылаются на различные виды данных в данных.
Три основных типа особенностей — категориальные, непрерывные (или численные) и производные.
- Категориальные особенности — например, у проблемы с сердцем — это пол пациента. Или для интернет-магазина — сделал ли кто-то покупку или нет.
- Непрерывные (или численные) особенности — числовые значения вроде средней частоты сердечных сокращений или число входов в систему.
- Производные особенности — особенности, которые вы создаёте из данных. Часто упоминаются как конструирование признаков. Конструирование признаков (особенностей) — это когда эксперт предметной области берёт свои знания и кодирует их в данные. Можно объединить количество входов в систему с временными метками, чтобы создать особенность и дать ей название «время с момента последнего входа». Или превратить даты из чисел в «это будний день (да)» и «это будний день (нет)».
Текст, изображения и почти всё, что вы можете себе представить, также может быть особенностью. Все они превращаются в числа, прежде чем алгоритм машинного обучения сможет их смоделировать.
Стоит отметить также некоторые важные аспекты, которые нужно помнить, когда речь идёт об особенностях.
- Сохраняйте их одинаковыми во время экспериментов (обучения) и продакшна (тестирования) — модель машинного обучения должна быть обучена на особенностях, максимально приближенных к тому, для чего она будет использоваться в реальной системе.
- Работа с экспертами определённой предметной области — что вы уже знаете о задаче и как это может повлиять на используемые особенности? Ваши инженеры машинного обучения и эксперты по данным должны это знать.
- Они того стоят? — если только у 10 % ваших образцов есть особенности, стоит ли включать их в модель? Лучше выбрать особенности с наибольшим охватом, те, где множество образцов имеют данные.
- Идеально значит сломано — если у вашей модели идеальная производительность, то где-то вы, вероятно, допустили утечку особенностей. Это означает, что данные, на которых обучалась ваша модель, используются для их проверки. Ни одна модель не идеальна.
Вы можете использовать особенности для создания простой базовой метрики. Специалист по вопросам оттока клиентов знает, что кто-то с вероятностью 80 % откажется от членства через 3 недели после входа в систему. Или агент по недвижимости, который в курсе цен продающихся домов, знает, что дома с более чем 5 спальнями и 4 ванными комнатами продаются за 500 000 долларов.
Эти особенности упрощены и не должны быть точными. Но именно это вы будете использовать, чтобы увидеть, может ли машинное обучение улучшиться или нет.
Шаг пятый: моделирование — какую модель выбрать? Как вы можете улучшить её? Как вы сравниваете её с другими моделями?
После того как вы определили задачу, подготовили данные, критерии оценки и характеристики, можно начинать моделировать.
Моделирование делится на три части: выбор модели, улучшение модели, сравнение её с другими.
Выбор модели
При выборе модели вы должны принять во внимание следующее: интерпретируемость и простота отладки, объём данных, ограничения на обучение и прогнозирование.
- Интерпретируемость и простота отладки — почему модель приняла решение, которое она приняла? Как исправить ошибки?
- Количество данных — сколько данных у вас есть? Изменится ли их количество?
- Ограничения в обучении и прогнозировании — это связано с вышеизложенным: сколько времени и ресурсов у вас есть для обучения и прогнозирования?
Чтобы решить эти проблемы, начните с простого. Сделать свою модель идеальной — заманчивая цель. Но если для обучения требуется в 10 раз больше вычислительных ресурсов, в 5 раз больше времени прогнозирования, а показатель оценки увеличится на 2 %, это будет не лучшее решение.
Линейные модели, такие как логистическая регрессия, обычно легче интерпретировать, они очень быстро обучаются и прогнозируются быстрее, чем более глубокие модели, такие как нейронные сети.
Но, скорее всего, ваши данные взяты из реального мира. Данные из реального мира не всегда линейны.
Что делать в таком случае?
Наборы деревьев решений и алгоритмов повышения градиента (модные слова, определения, которые пока не важны) обычно лучше всего работают со структурированными данными, такими как таблицы Excel и датафреймы. Обратите внимание на случайные леса, XGBoost и CatBoost.
Глубокие модели, такие как нейронные сети, обычно лучше всего работают с неструктурированными данными вроде изображений, аудиофайлов и текстов на естественном языке. Тем не менее, компромисс заключается в том, что они обычно дольше обучаются, их сложнее отлаживать и прогнозирование занимает больше времени. Но это не значит, что вы не должны их использовать.
Трансферное обучение — это подход, который использует преимущества глубоких и линейных моделей. При трансферном обучении берётся предварительно обученная глубокая модель и шаблоны, которые она изучила, используются в качестве входных данных для вашей линейной модели. Это значительно экономит время настройки и позволяет вам экспериментировать быстрее.
Где можно найти предварительно обученные модели?
Такие модели доступны в PyTorch hub, TensorFlow hub, model zoo и в fast.ai framework. Это хорошие ресурсы, которые стоит посмотреть перед созданием вашего прототипа.
Что насчёт других видов моделей?
Для создания прототипа вам вряд ли когда-нибудь понадобится создавать собственную модель машинного обучения. Люди уже написали код для них.
Вам нужно сосредоточиться на подготовке ваших входных и выходных данных таким образом, чтобы их можно было использовать с существующей моделью. Это означает, что ваши данные и метки должны быть строго определены. А вы должны понимать, какую задачу вы пытаетесь решить.

Настройка и улучшение модели
Первые результаты модели не являются финальными. Как и в случае с тюнингом автомобиля, модели машинного обучения можно настраивать для повышения производительности.
Настройка модели включает изменение гиперпараметров вроде скорости обучения или оптимизатора. Или специфические для модели архитектурные факторы, такие как количество деревьев для случайных лесов и количество и тип слоёв для нейронных сетей.
Раньше приходилось настраивать их вручную, но они всё больше автоматизируются. И должны быть автоматизированными везде, где это возможно.
Использование предварительно обученной через трансферное обучение модели часто даёт дополнительное преимущество всех этих шагов.
Приоритетами для настройки и улучшения моделей должны быть воспроизводимость и эффективность. Кто-то должен быть в состоянии воспроизвести шаги, которые вы предприняли для повышения производительности. И поскольку вашим главным узким местом будет время обучения модели, а не новые идеи для улучшения, ваши усилия должны быть направлены на повышение эффективности.
Сравнение моделей
- Модель 1, обученная на данных X, оценена на данных Y.
- Модель 2, обученная на данных X, оценена на данных Y.
Где-то модели 1 и 2 могут отличаться, но не в данных X или Y.
Шаг шестой: эксперименты — что ещё можно попробовать? Как другие шаги меняются в зависимости от того, что вы обнаружили? Развёрнутая модель работает так, как вы ожидали?
Этот шаг включает в себя все остальные шаги. Поскольку машинное обучение — это итеративный процесс, вам нужно убедиться, что ваши эксперименты эффективны.
Ваша главная цель — свести к минимуму время между автономными экспериментами и онлайн-экспериментами.
Автономные эксперименты — это шаги, которые вы предпринимаете, когда ваш проект ещё не ориентирован на клиента. Онлайн-эксперименты проводят, когда ваша модель машинного обучения находится в продакшне.
Все эксперименты должны проводиться на разных участках данных.
- Набор данных для обучения — используйте этот набор для обучения модели, рекомендуемый объём 70–80 % — ваших данных.
- Набор данных проверки/разработки — используйте этот набор для настройки модели, рекомендуемый объём — 10–15 % ваших данных.
- Набор тестовых данных — используйте этот набор для тестирования и сравнения моделей, рекомендуемый объём —10–15 % ваших данных.
Эти соотношения могут незначительно колебаться в зависимости от вашей задачи и имеющихся данных.
Низкая производительность по данным обучения означает, что модель не изучена должным образом. Попробуйте другую модель, улучшите существующую, соберите больше данных или соберите более подходящие данные.
Низкая производительность на тестовых данных означает, что ваша модель плохо обобщается. Ваша модель переобучилась (пере- в значении много) на данных для обучения. Используйте более простую модель или соберите больше данных.
Плохая производительность после развёртывания (в реальном мире) означает, что существует разница между тем, на чём вы обучали и тестировали свою модель, и тем, что происходит на практике. Повторите шаги 1 и 2. Убедитесь, что ваши данные совпадают с задачей, которую вы пытаетесь решить.
Когда вы реализуете большие экспериментальные изменения, документируйте «что» и «почему». Как и при настройке модели, помните, что любой человек, в том числе и вы в будущем, должен иметь возможность воспроизвести то, что вы сделали.
Это означает регулярное сохранение обновлённых моделей и наборов данных.
Подводим итоги
Многие компании заинтересованы в машинном обучении, но не знают, с чего начать. Одна из лучших возможностей начать — построить прототип, основываясь на описанных здесь шести шагах.
Прототип следует рассматривать не как нечто, что принципиально изменит работу вашего бизнеса, а скорее как исследование того, может ли машинное обучение повысить ценность вашего бизнеса.
Поставьте себе временные рамки для создания прототипа (2, 6 и 12 недель — хорошо подходят в качестве рамок). С подходящими данными хороший специалист по машинному обучению и науке о данных может получить 80–90 % окончательных результатов моделирования в относительно короткие сроки.
Пусть ваши эксперты предметной области, инженеры машинного обучения и учёные данных работают сообща. Нет ничего хуже, чем инженер по машинному обучению, создающий отличную модель, которая моделирует не то, что нужно.
Если веб-дизайнер может улучшить макет интернет-магазина, чтобы помочь в эксперименте по машинному обучению, заказчику стоит это знать.
Помните, что из-за природы прототипов может оказаться, что машинное обучение не может помочь вашему бизнесу (хотя это и маловероятно). Как менеджер проекта, убедитесь, что вы знаете об этом. Если вы инженер по машинному обучению или специалист по данным, будьте готовы принять факт, что ваши выводы ни к чему не приведут.
Но ещё не всё потеряно.
Ценность чего-то несработавшего заключается в том, что теперь вы знаете, что именно не работает, и можете направить свои усилия в другое русло. Вот почему полезно устанавливать временные рамки для экспериментов. Времени всегда не хватает, но дедлайны творят чудеса.
Если прототип машинного обучения оказался удачным — сделайте следующий шаг, если нет — сделайте шаг назад. Быстрее обучаться на практике, чем в теории.
Аспекты, не затронутые в статье
Каждый из этих аспектов заслуживает отдельной статьи. Но есть некоторые вещи, на которые стоит обратить внимание.
Дело всегда в данных. Без хороших данных вам не поможет ни одна модель машинного обучения. Если вы хотите использовать машинное обучение в своём бизнесе, оно начинается с хорошего сбора данных.
Развёртывание меняет всё. Хорошая модель в автономном режиме не всегда означает хорошую модель онлайн. После развёртывания модели появляется управление инфраструктурой, проверка данных, переподготовка моделей, анализ и многое другое. У любого облачного провайдера есть услуги для этого, но объединить их — всё ещё тёмное искусство. Хорошо платите своим инженерам. Если вы инженер данных, поделитесь тем, что вы знаете.
Сбор данных и развёртывание модели — самые длинные этапы конвейера машинного обучения. В этой статье мы сосредоточились только на моделировании, но упустили информацию о том, как подготовить данные к моделированию.
Инструменты меняются. Машинное обучение — это большой инструмент, состоящий из множества других инструментов. От библиотек кода и фреймворков до различных архитектур развёртывания. Обычно есть несколько разных способов сделать одну и ту же работу. Лучшее решение — постоянно меняться.

30К открытий33К показов

Самые лучшие курсы по Big Data. В предложенной подборке актуальные варианты обучения от проверенных школ, а так же рейтинги и цены на курсы для аналитиков Big Data

Собрали топ-10 каналов для опытных разработчиков, с которыми у вас точно будет что обсудить на дейлике.
В этой статье вы узнаете кто такой ML-инженер, чем он занимается, какие направления есть в этой профессии, а также узнаете список технологий, который нужно знать для работы в профессии.

Разберемся, как дефицит кремния породил золотую лихорадку среди разработчиков и почему программисты стали дороже железа.