


Применение структур данных и алгоритмов на практике на примере Skype, Uber и Skyscanner

Разработчик с опытом работы в Skyscanner, Uber и Skype рассказывает, где он нашёл практическое применение структурам данных и алгоритмам.
17К открытий18К показов
Рассказывает Гергели Орош
Деревья и поиск по дереву — Skype, Uber и UI фреймворки
Когда мы делали Skype под Xbox One, мы работали на голой Xbox OS, в которой недоставало ключевых библиотек. Это было одно из первых полномасштабных приложений на платформе. Нам нужно было сделать навигацию для тачпада и голосовых команд.
Мы слепили обычный навигационный фреймворк поверх WinJS. Для этого нужен был DOM-подобный граф (Document Object Model), чтобы отслеживать активные элементы. Для их поиска мы применяли алгоритмы поиска по дереву. Это классический случай BFS или DFS (breadth-first search или depth-first search).
Если вы занимаетесь веб-разработкой, то уже работаете с древовидной структурой — объектной моделью документа. Все его узлы могут иметь дочерние элементы, и браузер рендерит их после обхода дерева. Для поиска конкретного элемента можно использовать встроенные DOM-методы, такие как getElementById, или реализовать BFS/DFS поиск для обхода узлов.
Во многих фреймворках, которые рендерят UI элементы, применяются древовидные структуры данных. В React поддерживается виртуальный DOM и используется согласование — алгоритм сравнения — для увеличения производительности путём повторного рендера только тех элементов, которые были изменены. Райан Бас визуализирует этот процесс в своей статье о согласовании в React.
Мобильная архитектура Uber — RIBs (Router, Interactor, Builder) — также использует деревья, как и большинство UI фреймворков, где элементы рендерятся по иерархии. В RIBs дерево нужно для управления состояниями, присоединяя и отсоединяя ветви в зависимости от того, нужны они сейчас или нет.

Взвешенные графы и кратчайший путь — Skyscanner
Skyscanner находит авиабилеты по наиболее выгодным ценам. Для этого он сканирует рейсы по всему миру и сводит их вместе. Хоть задача и состоит больше в краулинге, чем в кэшировании — поскольку авиалинии сами просчитывают варианты пересадок, — составление сложного маршрута из нескольких городов становится задачей нахождения кратчайшего пути.
Реализация такой функциональности потребовала достаточно много времени. Самые дешёвые варианты путешествия вычисляются с применением алгоритмов типа Dijkstra или A*. Путь перелёта здесь представлен ориентированным графом, где вес каждого ребра — это стоимость билета. Для решения такой задачи мы доработали поисковый алгоритм A* (читается «А-стар»). Если вам интересна тема полётов и кратчайших путей — советую статью от Сашина Мальхотры.
Сортировка — Skype
Сортировка — семейство алгоритмов, которое основательно использовать или реализовывать мне приходилось довольно редко. В 2013 году, однако, мне пришлось немного поупражняться в этом.
В то время при входе в аккаунт Skype контакты подгружались частями, и полная загрузка требовала времени. Один из инженеров подумал, что более производительным решением будет выстроить список контактов, использовав алгоритм сортировки вставкой. Мы постоянно спорили по поводу вида алгоритма. В итоге качественные тесты и бенчмарки занимали бóльшую часть работы. Лично я не видел в этом смысла, но проект уже был в той стадии разработки, когда время на подобные заморочки имелось.
Определённо существуют прикладные ситуации, где правильно подобранный алгоритм может сыграть роль. Сортировка вставками может быть полезна, когда в потоке — огромные куски данных и нужно их визуализировать в реальном времени. Сортировка слиянием подходит для случая «разделяй и властвуй», если большие куски данных хранятся на разных узлах. Я сам до сих пор не работал с такими, поэтому считаю, что в ежедневном использовании сортировочные алгоритмы — нечастый гость.
А вы используете алгоритмы и структуры данных в работе?
Нет, только теория
Иногда применяю на практике
Использую постоянно
Хеш-таблицы и хеширование — кругом
Наиболее часто применяемая мной структура данных после массивов. Это очень полезный инструмент: от выявления дубликатов и кэширования до использования в распределённых системах при шардинге. Почти во всех языках есть эта структура, и её легко реализовать при необходимости.
Стеки и очереди — иногда
Структура данных стек будет хорошо знакома тем, кто занимался дебагом языка со стактрейсом. Именно это сблизило нас больше всего. Также это распространенный выбор при обходе дерева в глубину.
Очередь в моём коде — редкий гость. Такую структуру применяют для поиска в ширину, где она складывается сама собой. Как-то видел планировщик задач для кода, который хорошо использовал очереди с приоритетом. В первую очередь он выполнял самые короткие задачи с помощью алгоритм Python для очередей с кучами.
Криптография — Uber
Чувствительная информация, вводимая пользователем с мобильного устройства или веб-клиента, должна быть зашифрована перед отправлением в сеть и расшифрована только на определённом сервисе. Для этого нужен крипто-подход как на стороне клиента, так и в бэкенде.
Криптография — интересная штука. Тебе не нужно выдумывать новый алгоритм шифрования — это может стать большой ошибкой. Наоборот, стоит брать существующий, хорошо задокументированный стандарт и использовать встроенные во фреймворк примитивы. Обычно прибегают к AES. Он считается безопасным для шифрования чувствительной информации, и рабочих атак на момент выпуска статьи нет. Поэтому AES192 или AES256 — хорошие варианты в большинстве случаев.
Когда я присоединился к Uber, мобильная и веб-криптография уже были реализованы. И чтобы разобраться в них, мне пришлось подтянуть знания по AES, HMAC, RSA и другим вещам.
Вы редко будете заниматься реализацией крипто-примитивов — если только не создаёте с нуля core фреймворк. Но вы можете столкнуться с ситуацией, где придётся как минимум понимать, почему был выбран тот или иной подход.
Деревья решений — Uber
В одном из проектов нам пришлось реализовать непростую бизнес-логику в мобильном приложении. Основываясь на почти десятке достаточно сложных правил, нужно было отображать одно из нескольких представлений.
Инженер, работающий над этим, сначала попробовал закидать проблему if-else выражениями. В результате всё стало еще запутаннее. Тогда мы перешли на дерево решений, поскольку оно было простым в реализации и легко изменяемым при необходимости. Нам оставалось просто реализовать рёбра так, чтобы они следовали правилам.
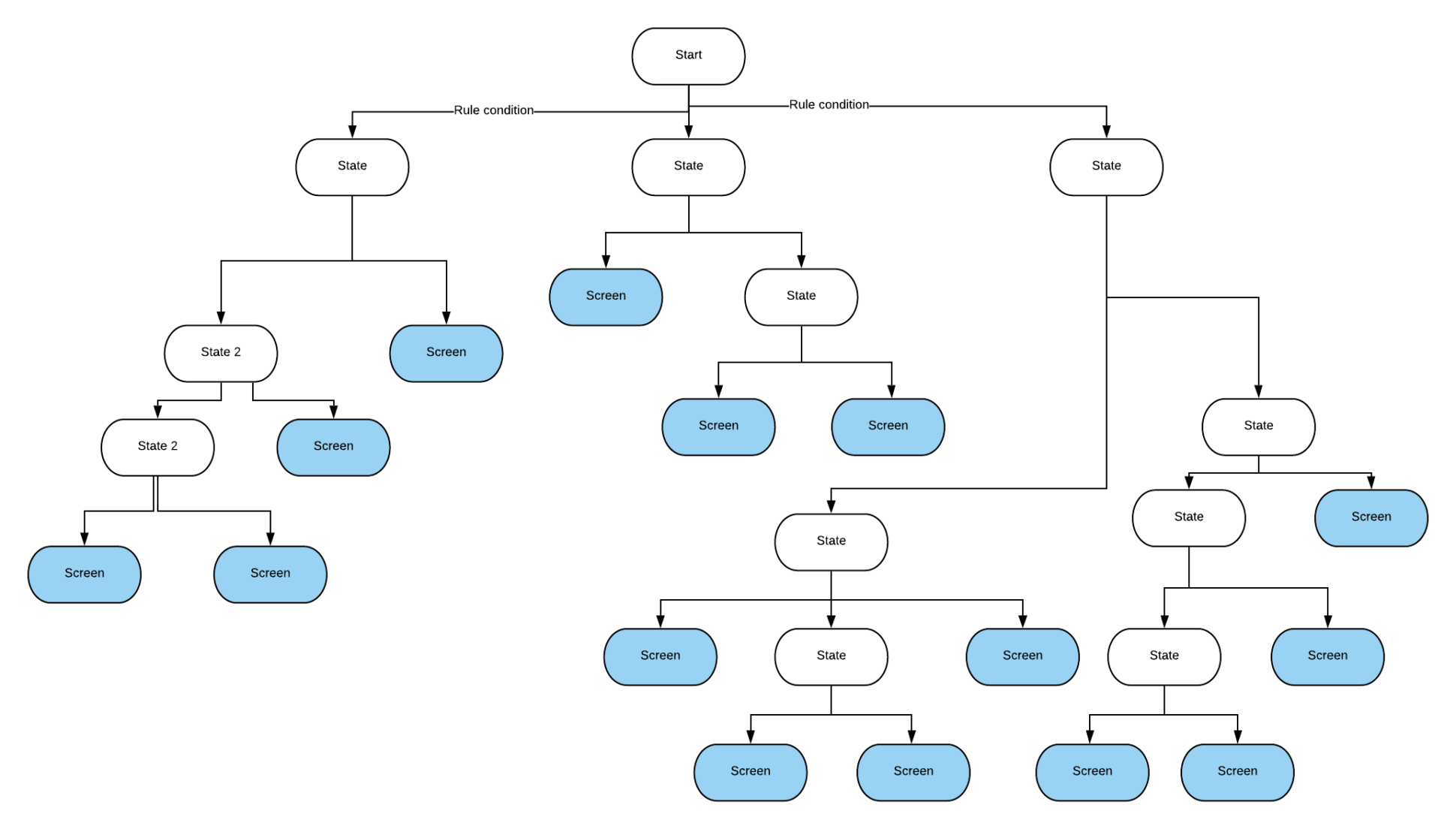
Система для разработки мобильных билдов Uber — SubmitQueue — также применяет деревья решений, формируемые в реальном времени. Отделу Developer Experience пришлось решать сложную проблему: ежедневно происходят сотни слияний мобильных билдов. Каждому необходимо было как минимум 30 минут на компиляцию, UI-тесты, юнит-тесты и интеграцию. Параллелизация — такое себе решение, так как два билда могли иметь пересекающиеся изменения, из-за чего происходил конфликт в слиянии. На практике это означало, что инженеры тратили лишние 2-3 часа, переделывая и начиная слияние заново в надежде, что на этот раз получится.
В Developer Experience нашли креативный подход: они стали предсказывать конфликты слияния и помещали в очередь билды, используя спекулятивные графы. Они очень похожи на бинарное дерево решений.
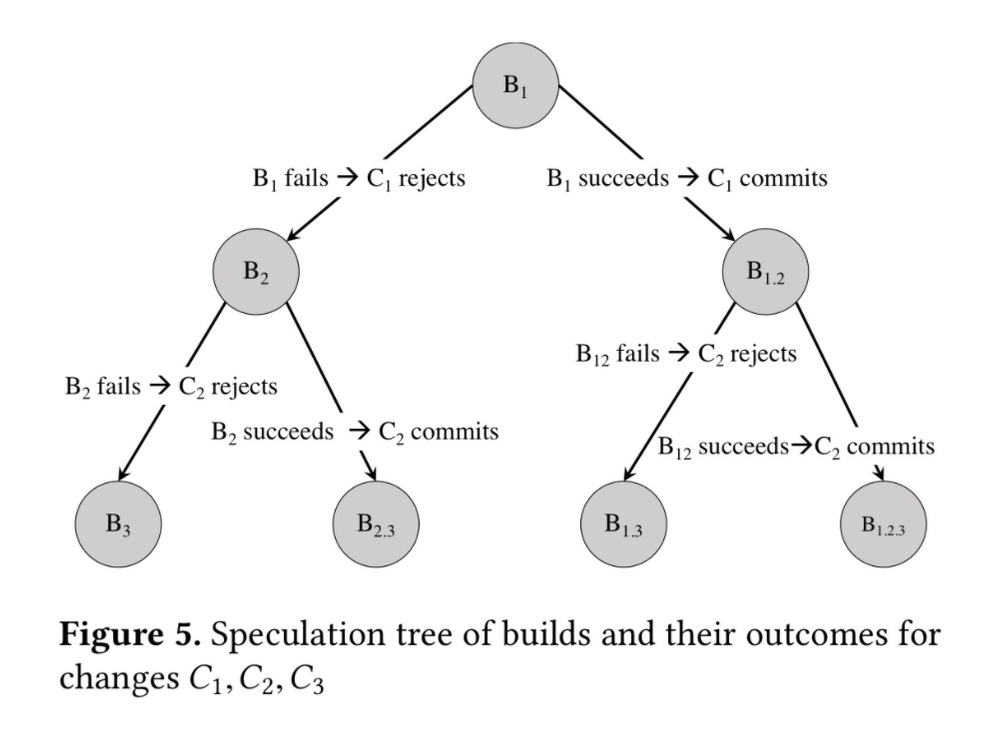
У Адриана Кольера также есть хороший визуальный анализ подхода. Результатом стало ускорение работы над билдами и улучшение жизни сотен мобильных разработчиков.
Применение структур данных со звёздочкой: шестиугольные сетки — Uber
Одна из самых сложных и интересных проблем в Uber — оптимизация стоимости поездки и распределение водителей (партнёров). Цены могут варьироваться, а водители всё время перемещаются. H3 — сеточная система, которую построили разработчики для одновременного анализа данных и визуализации в городах на крошечном масштабе. Её структура — шестиугольная сетка с иерархическими индексами.
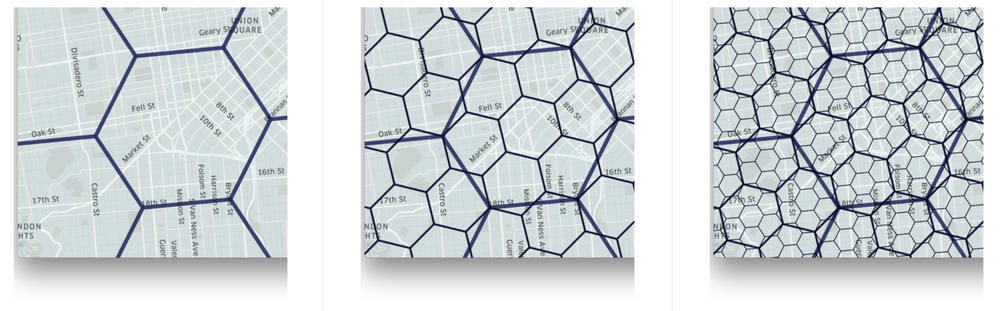
Она имеет специфические функции для индексирования, обхода, иерархической сетки, регионов и ненаправленных рёбер, о которых рассказывается в API-референсе. Детально окунуться в тему можно, просмотрев статью об H3 библиотеке, исходники или презентацию, рассказывающую, как и зачем этот инструмент был создан.
Что мне понравилось из опыта создания и применения собственных структур данных — они могут помочь в определённых нишах. Ведь не так часто попадаются ситуации, где гексагональные сетки с иерархической индексацией имели бы смысл за пределами картографии с различными уровнями данных внутри каждой клетки.
Если вы уже знакомы с другими структурами, понять эту будет намного проще.
Что же по собеседованиям?
Вам нужно знать, что такое алгоритм, уметь придумывать и применять самые простые из них. Также стоит знать о применении базовых структур данных. Но продвинутые алгоритмы типа Dijkstra и A* не должны забивать вам голову. Всё, что за пределами сортировки, я сам изучал на ходу. Тоже самое с экзотическими структурами, как Красно-Чёрное дерево или AVL-дерево.
Реальность такова, что компании перебарщивают с задачами по алгоритмам. Я понимаю почему: тебе дают 45 минут или меньше, а вопросы легко взаимозаменяемые. Поэтому, если анкеты и утекут в интернет, то ничего страшного не произойдёт. Также они легко масштабируемы при рекрутинге: можно иметь 100+ вопросов, и любой интервьюер сможет их оценить. Особенно в Кремниевой Долине всё чаще можно услышать вопросы, нацеленные на динамическое программирование или экзотические структуры данных. Это поможет нанять сильных инженеров, но при этом оттолкнёт множество людей, хорошо справляющихся с задачами, где продвинутые алгоритмы вообще не нужны.
Полезные ресурсы
- На GeeksforGeeks есть хороший обзор по затронутым в этой статье структурам. Поиграйтесь с ними на своем языке программирования. Также советую коллекцию структур данных от HackerRank для практики в кодинге.
- Grokking Algorithms, написанная Адитей Бхаргавой, — по-моему лучший гайд по алгоритмам как для новичков, так и для опытных инженеров. Очень доступный и визуальный путеводитель, затрагивающий всё, что нужно знать на эту тему. Я убежден, что вам не понадобится знать больше, чем написано в этой книге.
- The Algorithm Design Manual и Algorithms: Fourth Edition — обе эти книги мне помогли в свое время освежить знания, полученные на лекциях по алгоритмам в университете. Я бросил их на полпути, так как показались мне слишком сухими и не касались моей повседневной работы.

17К открытий18К показов

Рабочий подход к тестированию трансформации данных в ETL-процессах. На примере Python-проекта с pytest, allure и psycopg2 демонстрируется, как автоматизировать создание и наполнение таблиц, хранить схемы и данные, а затем сравнивать результат.

Алгоритмические задачи развивают логику, структурное мышление и помогают на собеседованиях и в работе. Узнайте, с чего начать, как избежать выгорания и сохранить мотивацию.

О катастрофическом забывании: почему модели теряют навыки и что делать разработчикам

Разработчик изучил рекомендательную систему Netflix: как алгоритмы и инфраструктура персонализируют контент и удерживают зрителей