


Создайте и разверните своё первое веб-приложение для машинного обучения

Создаём с помощью PyCaret приложение для прогнозирования затрат на госпитализацию пациентов на основе разных показателей.
22К открытий22К показов

Анна Ларионова
Маркетолог в ОТР
В этом руководстве мы будем использовать PyCaret для разработки конвейера машинного обучения, который будет включать предварительную обработку данных и регрессионную модель для прогнозирования затрат на госпитализацию пациентов на основе демографических и базовых показателей риска для здоровья пациента, таких как возраст, ИМТ, статус курения и т.д.
Что вы узнаете в этом уроке
- Что такое развертывание и почему мы используем модели машинного обучения.
- Как разработать конвейер машинного обучения и модель обучения с использованием PyCaret.
- Как создать простое веб-приложение с использованием Python-фреймворка Flask.
- Как запустить веб-приложение на Heroku и посмотреть модель в действии.
Какие инструменты мы будем использовать в этом уроке?
PyCaret
PyCaret – библиотека машинного обучения на Python с открытым исходным кодом, предназначенная для обучения и развертывания конвейеров и моделей машинного обучения в производстве. PyCaret может быть легко установлен с помощью менеджера пакетов pip.
Flask
Flask – фреймворк, позволяющий создавать веб-приложения. Веб-приложение может быть коммерческим веб-сайтом, блогом, системой электронной коммерции или приложением, которое генерирует прогнозы на основе данных, предоставленных в режиме реального времени с использованием обученных моделей. Если у вас не установлен Flask, вы можете использовать pip для его установки.
GitHub
GitHub – это облачная служба, которая используется для размещения, управления и контроля кода. Представьте, что вы работаете в большой команде, в которую вносят изменения несколько человек (иногда сотни). PyCaret сам по себе является примером проекта с открытым исходным кодом, в котором сотни разработчиков сообщества постоянно вносят свой вклад в исходный код. Если вы ранее не пользовались GitHub, вы можете зарегистрировать бесплатный аккаунт.
Heroku
Heroku – это платформа как услуга (PaaS), которая позволяет развертывать веб-приложения на основе управляемой контейнерной системы, с интегрированными службами данных и мощной экосистемой. Проще говоря, это позволит вам перенести приложение с локального компьютера в облако, чтобы любой мог получить к нему доступ через веб-URL. В этом руководстве мы выбрали Heroku для развертывания, поскольку оно предоставляет бесплатные часы ресурсов при регистрации новой учетной записи.

Зачем внедрять модели машинного обучения?
Развертывание моделей машинного обучения – процесс обеспечения доступности моделей на производстве, где веб-приложения, корпоративное программное обеспечение и API-интерфейсы могут использовать обученную модель, предоставляя новые данные и генерируя прогнозы.
Обычно модели машинного обучения строятся таким образом, чтобы их можно было использовать для прогнозирования результата (двоичное значение (1 или 0) для классификации, непрерывные значения для регрессии, метки для кластеризации и т.д.).
В общем, существует два способа генерирования прогнозов
- прогнозирование по набору;
- прогнозирование в режиме реального времени.
В этом руководстве мы увидим, как развернуть модель машинного обучения для прогнозирования в режиме реального времени.
Бизнес-проблема
Страховая компания хочет улучшить прогнозирование денежных потоков путем более точного прогнозирования сборов с пациентов, используя демографические и базовые показатели риска для здоровья пациентов во время госпитализации.

Цель
Создать веб-приложение, в котором демографическая информация и информация о состоянии здоровья пациента вводятся в веб-форму для прогнозирования расходов.
Задачи
- Обучить и протестировать модели и разработать конвейер машинного обучения для развертывания;
- Создать базовый HTML-интерфейс с формой ввода для независимых переменных (возраст, пол, индекс массы тела, наличие детей, наличие вредных привычек (курение), регион);
- Создать серверную часть веб-приложения с помощью Flask;
- Развернуть веб-приложение на Heroku. После развертывания оно станет общедоступным через веб-URL.
Задача 1 – Обучение модели и её валидация
Обучение и проверка модели выполняются в интегрированной среде разработки (IDE) или в Notebook на локальном компьютере или в облаке. В этом уроке мы будем использовать PyCaret в Jupyter Notebook для разработки конвейера машинного обучения и обучающих регрессионных моделей. Если вы ранее не использовали PyCaret, нажмите здесь, чтобы узнать больше о PyCaret, или посмотрите учебные пособия по началу работы на нашем сайте.
В этом уроке мы провели два эксперимента.
Первый эксперимент выполняется с настройками предварительной обработки по умолчанию в PyCaret (условный расчет отсутствующих значений, категориальное кодирование переменных и т. д.).
Во втором эксперименте есть некоторые дополнительные задачи предварительной обработки: масштабирование и нормализация, автоматическая разработка функций и объединение непрерывных данных в интервалы.
Пример установок для второго эксперимента:

Волшебство происходит только с несколькими строками кода. Обратите внимание, что во втором эксперименте преобразованный набор данных имеет 62 признака для обучения, полученные из 7 признаков исходного набора данных. Все новые признаки являются результатом преобразований и автоматической разработки признаков в PyCaret.

Пример кода для обучения и тестирования модели в PyCaret:
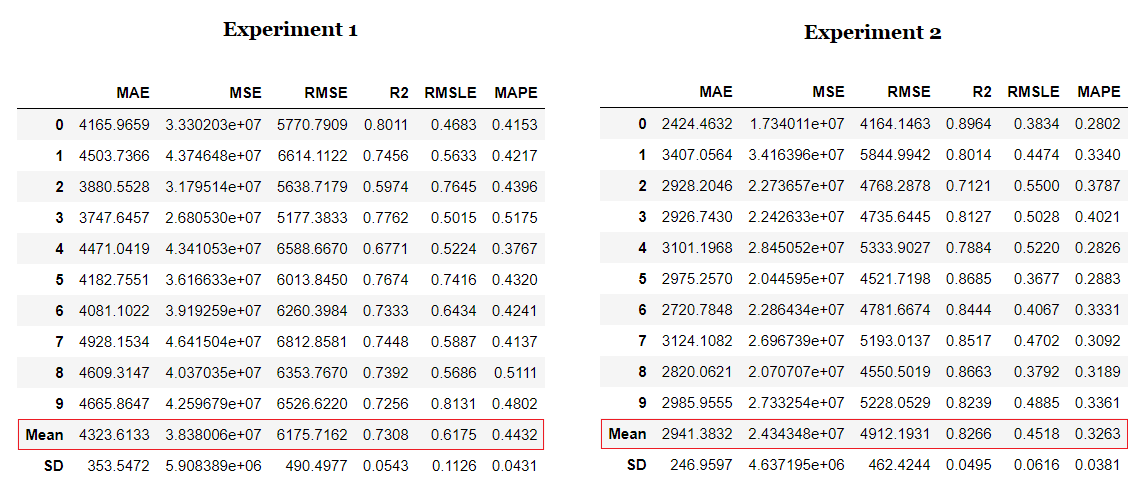
Обратите внимание на влияние преобразований и автоматического проектирования признаков. R2 (квадрат значения коэффициента корреляции) увеличился на 10% с очень небольшим усилием. Мы можем сравнить остаточный график линейной регрессионной модели для обоих экспериментов и наблюдать влияние преобразований и конструирования признаков на гетероскедастичность модели.
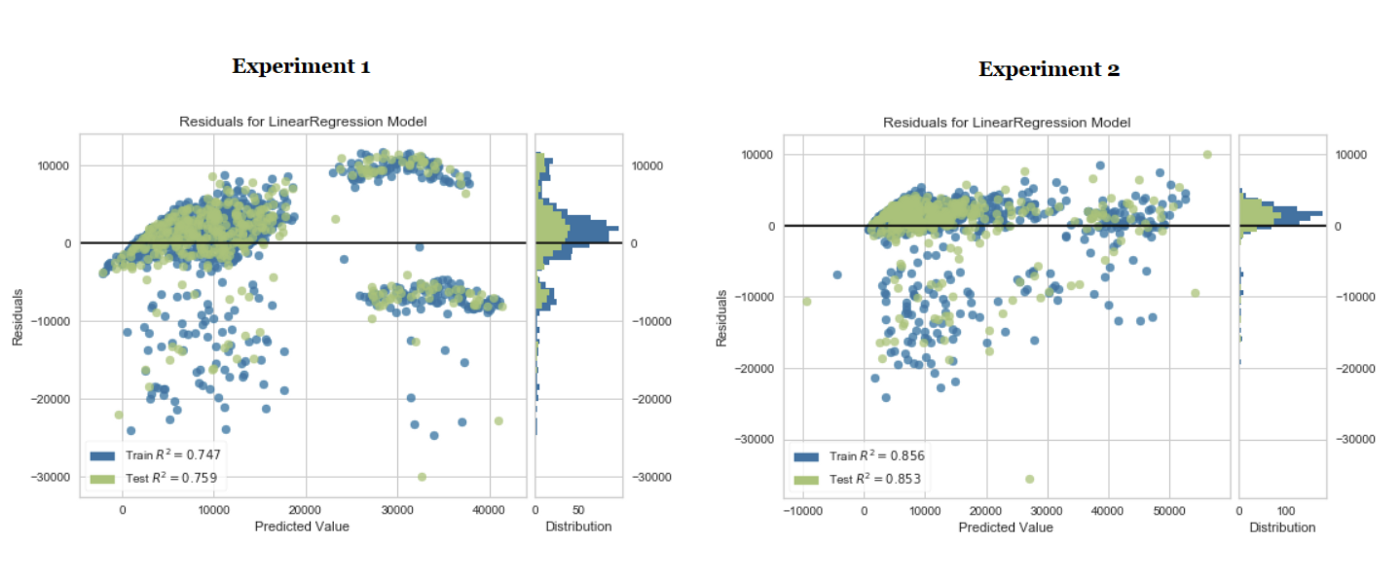
Машинное обучение – многократный процесс. Количество итераций и используемых методов зависит от того, насколько критична задача и каковы будут последствия, если прогнозы окажутся неверными. Серьезность и влияние модели машинного обучения для прогнозирования исхода пациента в режиме реального времени в отделении интенсивной терапии больницы – это гораздо больше, чем модель, построенная для прогнозирования оттока клиентов.
В этом уроке мы выполнили только две итерации, и для развертывания будет использована модель линейной регрессии из второго эксперимента. Однако на данном этапе модель по-прежнему является лишь объектом внутри ноутбука. Чтобы сохранить его в виде файла, который может быть передан и использован другими приложениями, выполните следующий код:
При сохранении модели в PyCaret создается весь конвейер преобразования, основанный на конфигурации, определенной в функции setup(). Все взаимозависимости организуются автоматически. См. конвейер и модель, хранящиеся в переменной deployment_28042020.

Мы завершили нашу первую задачу по обучению и выбору модели для развертывания. Конечный конвейер машинного обучения и модель линейной регрессии теперь сохраняются в виде файла на локальном диске в расположении, определенном в функции save_model(). (В этом примере: c:/username/ins/deployment_28042020.pkl).
Задача 2 – создание веб-приложения
Теперь, когда наш конвейер машинного обучения и модель готовы, мы начнем создавать веб-приложение, которое может подключаться к ним и генерировать прогнозы по новым данным в режиме реального времени. Есть две части этого приложения:
- front-end (разработанный с использованием HTML);
- back-end (разработан с использованием Flask в Python).
Интерфейс веб-приложения
Как правило, интерфейсные веб-приложения строятся с использованием HTML, который не является предметом данной статьи. Мы использовали простой HTML-шаблон и таблицу стилей CSS для разработки формы ввода. Вот HTML-фрагмент начальной страницы нашего веб-приложения.
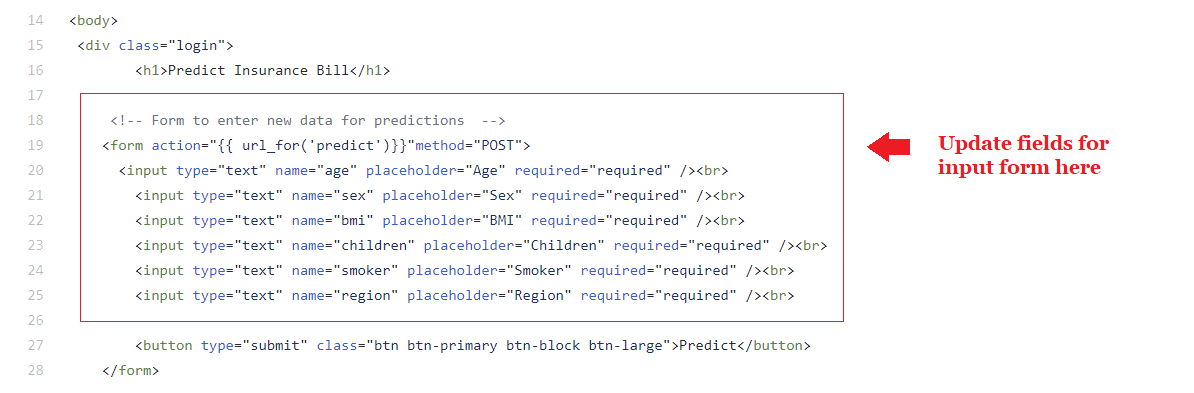
Вам не нужно быть экспертом в HTML, чтобы создавать простые приложения. Существует множество бесплатных платформ, которые предоставляют шаблоны HTML и CSS, а также позволяют быстро создавать красивые HTML-страницы с помощью drag-and-drop интерфейса [интерфейса перетаскивания элементов интерфейса].
Таблица веб-стилей CSS
CSS (Cascading Style Sheets, каскадные таблицы стилей) – язык описания внешнего вида HTML-документов. Это эффективный способ управления макетом вашего приложения. Таблицы стилей содержат такую информацию, как цвет фона, размер и цвет шрифта, поля и т.д. Они сохраняются внешне как .css-файл и связаны с HTML, но включают в себя 1 строку кода.

Бэк-энд веб-приложения
Бэк-энд веб-приложения разрабатывается с использованием фреймворка Flask. Для начинающих интуитивно понятно рассматривать Flask как библиотеку, которую вы можете импортировать так же, как и любую другую библиотеку в Python. Смотрите пример фрагмента кода нашего бэк-энда, написанного с использованием фреймворка Flask на Python.

Как вы помните из первой задачи, мы создали линейную регрессионную модель, обученную на 62 признаках, которые были автоматически спроектированы PyCaret. Однако на передней панели нашего веб-приложения есть форма ввода, которая собирает только шесть признаков: возраст, пол, индекс массы тела, дети, наличие вредных привычек (курение), регион.
Как мы преобразуем 6 признаков нового элемента данных в реальном времени в 62 признака, по которым была обучена модель? С последовательностью преобразований, применяемых во время обучения модели, кодирование становится все более сложной и трудоемкой задачей.
В PyCaret все преобразования – категориальное кодирование, масштабирование, условный расчет отсутствующих значений, проектирование признаков и даже выбор признаков – автоматически выполняются в режиме реального времени перед созданием прогнозов.
Представьте себе объем кода, который вам пришлось бы написать, чтобы применить все преобразования в строгой последовательности, прежде чем вы смогли бы использовать модель для прогнозов. На практике, когда речь идёт о машинном обучении, необходимо думать обо всем конвейере машинного обучения, а не только о модели.
Тестирование приложения
Один из последних шагов, предваряющий публикацию приложение на Heroku, — локальное тестирование веб-приложения. Откройте приглашение Anaconda и перейдите в папку, где app.py сохраняется на вашем компьютере. Запустите файл Python с приведенным ниже кодом:
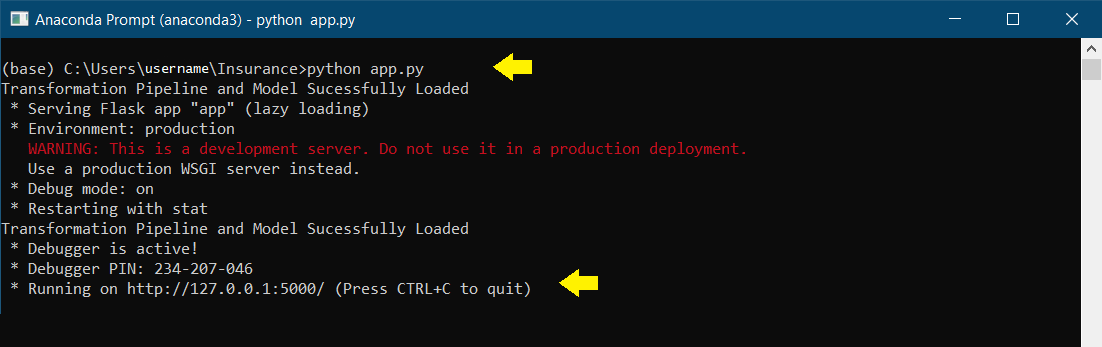
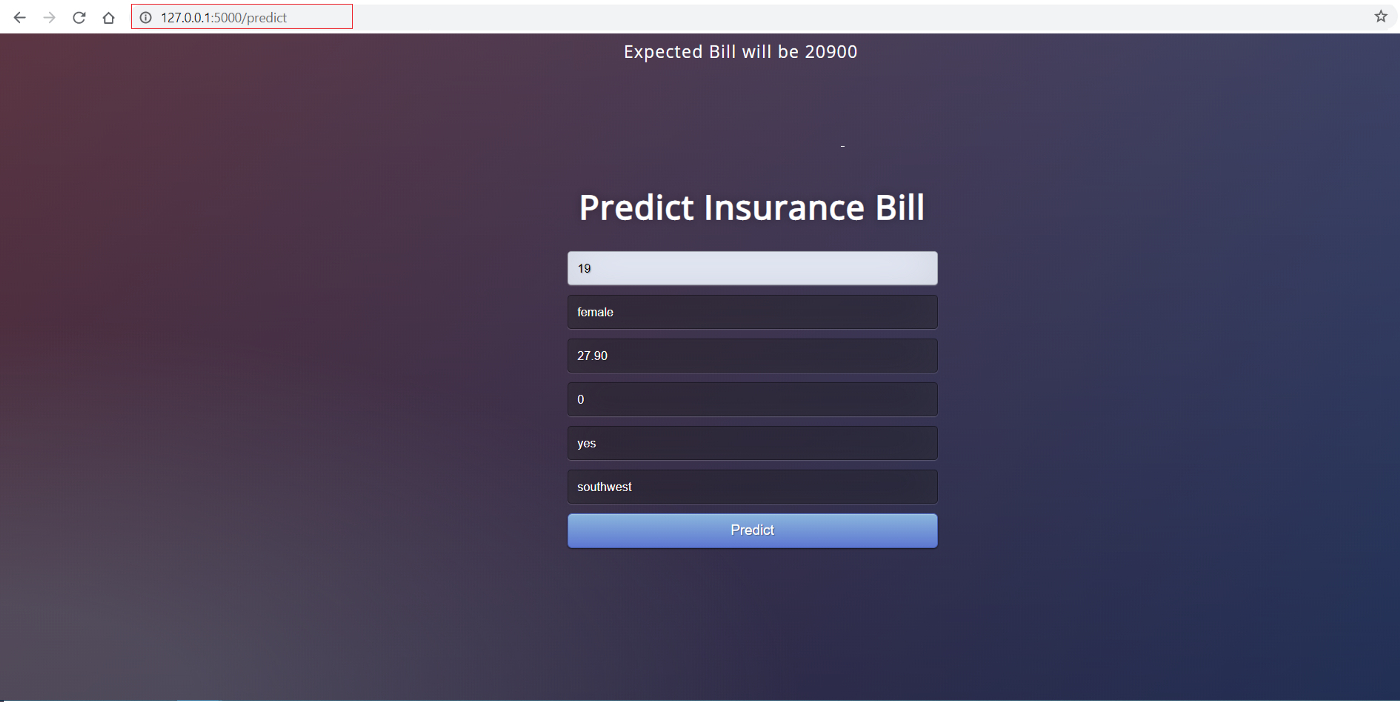
После выполнения скопируйте URL-адрес в браузер: он должен открыть веб-приложение, размещенное на вашем локальном компьютере (127.0.0.1). Попробуйте ввести тестовые значения, чтобы проверить, работает ли функция прогнозирования. В приведенном ниже примере ожидаемый счет для 19-летней курильщицы без детей на юго-западе составляет 20 900 долларов.
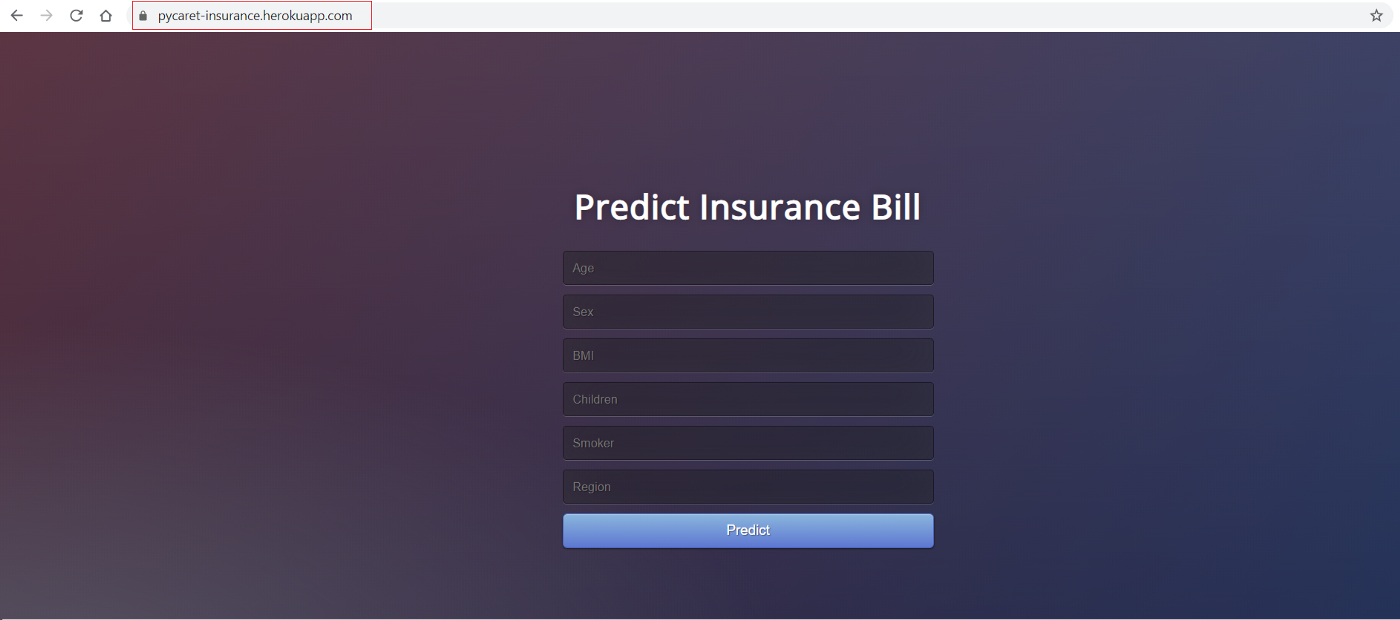
Поздравляю! Вы только что создали свое первое приложение для машинного обучения. Теперь пришло время перенести это приложение с вашего локального компьютера в облако, чтобы другие люди могли использовать его с веб-URL.
Задача 3 – развертывание веб-приложения на Heroku
Теперь, когда модель обучена, конвейер машинного обучения готов, а приложение протестировано на локальном компьютере, мы готовы начать развертывание приложения на Heroku. Существует несколько способов загрузить исходный код вашего приложения на Heroku. Самый простой способ – связать репозиторий GitHub с вашей учетной записью Heroku.
Если вы хотите следовать дальше, вы можете скопировать (fork) этот репозиторий из GitHub. Если вы не знаете, как полностью скопировать оригинальный репозиторий с помощью функции «fork», пожалуйста, ознакомьтесь с этим материалом из официального учебника по GitHub.
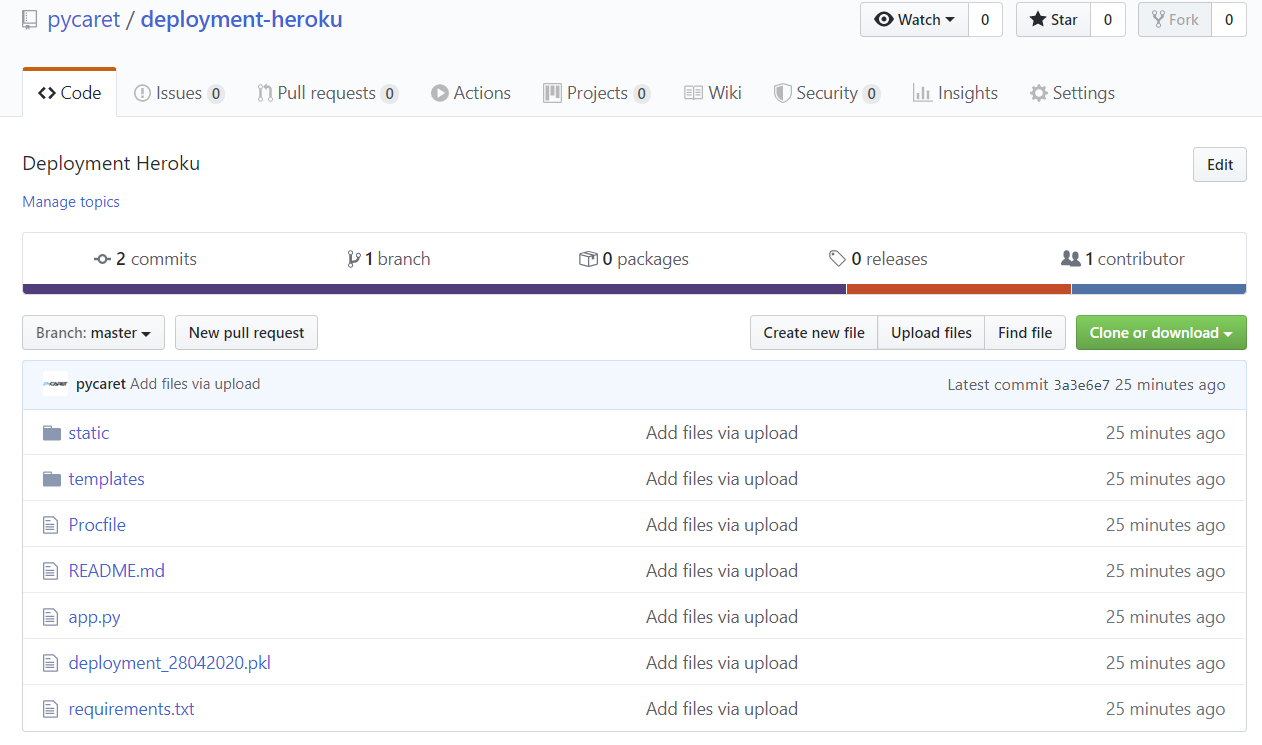
К настоящему моменту вы знакомы со всеми файлами в репозитории, показанными выше, за исключением двух файлов: requirements.txt и Procfile.

Файл requirements.txt — текстовый файл, содержащий имена пакетов Python, необходимых для выполнения приложения. Если эти пакеты не установлены в среде, в которой работает приложение, оно завершится ошибкой.

Procfile – одна строка кода, которая предоставляет инструкции по запуску веб-сервера, указывающие, какой файл должен быть выполнен первым, когда кто-то входит в приложение. В этом примере имя нашего файла приложения – «app.py», а само приложение также называется «app». Следовательно, мы получаем логическую цепочку «app:app».
Как только все файлы будут загружены в репозиторий GitHub, мы будем готовы начать развертывание на Heroku. Выполните следующие действия:
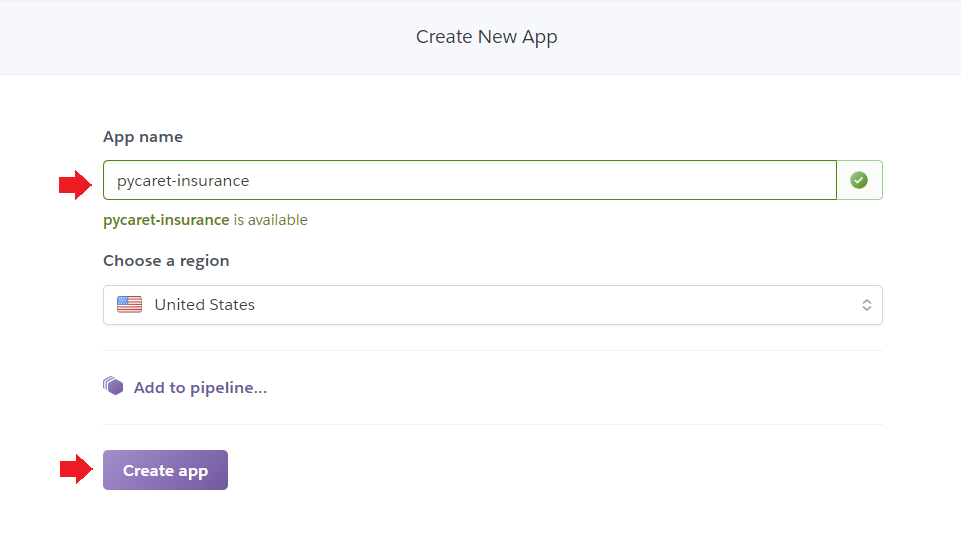
Шаг 1 – Зарегистрируйтесь на сайте heroku.com и нажмите на кнопку «Создать новое приложение» («Create new app»)

Шаг 2 – Введите название приложения и страну происхождения
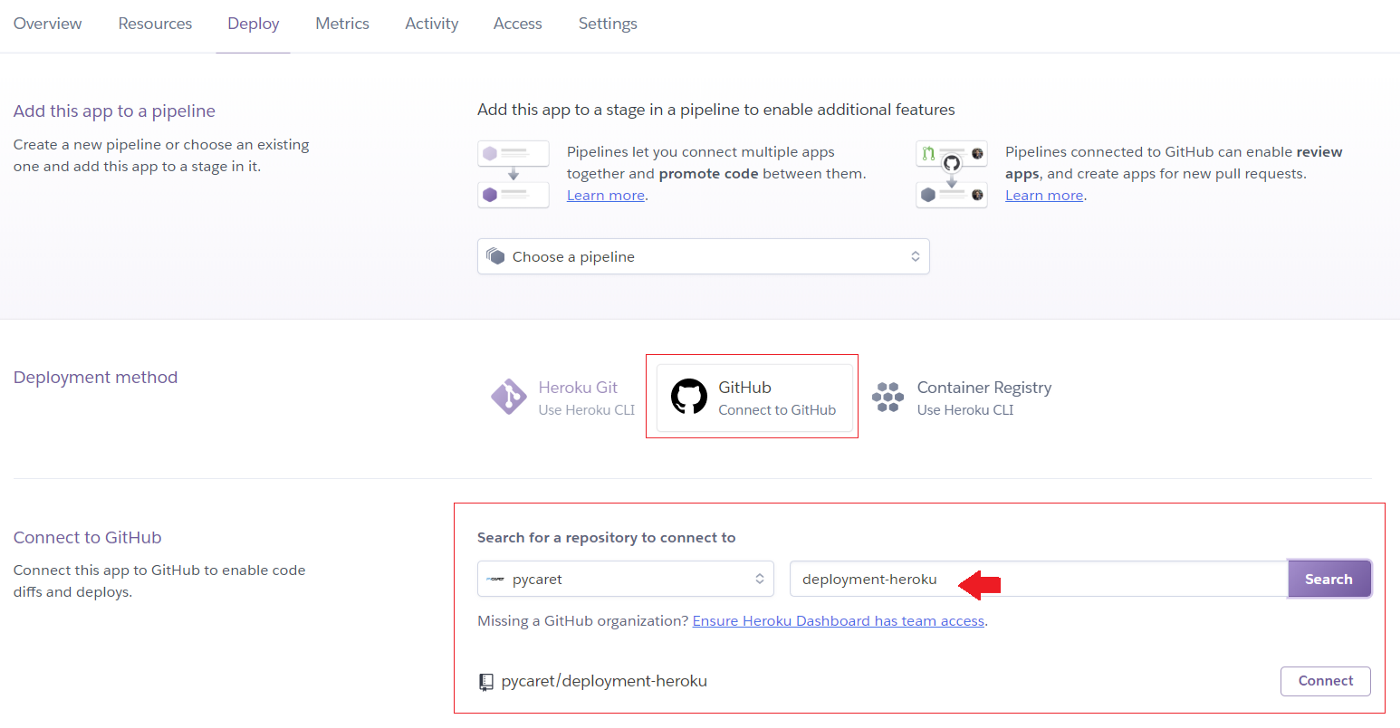
Шаг 3 – Подключитесь к вашему репозиторию GitHub, где размещен код
Шаг 4 — Создать ветвь

Шаг 5 — Подождите 5-10 минут и вуаля!

Приложение опубликовано по URL-адресу: https://pycaret-insurance.herokuapp.com/.
И последний момент, прежде чем мы завершим этот урок.
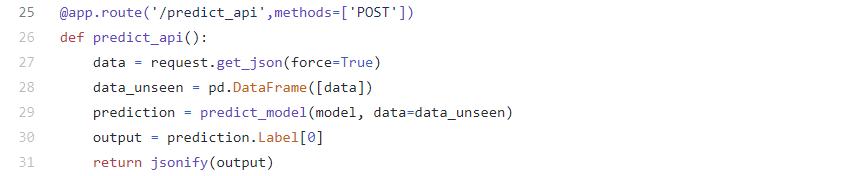
Итак, мы создали и развернули веб-приложение, которое работает с нашим конвейером машинного обучения. Теперь представьте, что у вас уже есть корпоративное приложение, в которое вы хотите интегрировать прогнозы из своей модели. Всё, что вам необходимо, это веб-сервис, где вы можете объединить API с новыми точками входных данных и получить прогнозы. Для достижения этой цели мы создали функцию predict_api() в файле app.py. Смотрите фрагмент кода:
Вот как вы можете использовать эту веб-службу в Python с помощью библиотеки запросов:

Важные ссылки

22К открытий22К показов

22 апреля пройдет конференция Газпромбанк.Тех для разработчиков и инженеров.

Максим Коновалов расскажет, как стал Data Scientist в МТС, пройдя школу аналитиков данных МТС и стажировку.

urllib3 показал, что DeprecationWarning не работает: Python игнорирует устаревшие API, из-за чего ломаются даже крупные проекты

Разбираем, какие скилы и знания станут обязательными в 2026 году, что будут ценить работодатели и как новичку не потеряться на входе в ИТ-индустрию