


Что делать, если в датасете пропущены данные? — 6 способов импутации данных с примерами

Если в датасете пропущены данные, результаты работы с ним могут быть непредсказуемы. Разбираем способы импутации данных, их плюсы и минусы.
13К открытий15К показов
Автор перевода Алексей Морозов
Реальные наборы данных могут быть неполными. Не в том смысле, что в анализ не вошли какие-то важные точки или неудачно были выбраны параметры, а просто отсутствуют некоторые данные, которые в принципе должны были там быть.
Это может случиться из-за технических проблем, или если датасет собран из нескольких источников с разными наборами параметров; важно то, что в таблице присутствуют пустые ячейки. Вместо значений в них ставится какая-нибудь заглушка — NaN, просто пустая ячейка или ещё что-нибудь в этом роде. Если их много — тренировка на таких данных сильно ухудшит качество модели, а то и окажется вовсе невозможной. Многие алгоритмы того же scikit-learn не только требуют массив чисел (а не NaN или «missing»), но и ожидают, что этот массив будет состоять из валидных данных.
Что делать? Можно, конечно, просто выкинуть все неполные наблюдения, но так можно потерять ценную информацию. Лучше попытаться восстановить недостающие значения на основании остальных данных в наборе, или хотя бы вставить в пустые ячейки что-нибудь более-менее осмысленное. Этот процесс называется импутацией данных.
В этой статье будет описано 6 популярных способов импутации для наборов однородных точек. Для временных серий они непригодны, там всё делается совсем иначе.
Способ первый: не делать ничего
Тут всё просто: отдаём алгоритму датасет в исходном виде и надеемся, что он с ним как-нибудь разберётся. Некоторые алгоритмы умеют принимать во внимание и даже восстанавливать пропущенные значения в данных. Например, XGBoost делает это за счёт уменьшения функции потерь при обучении. У алгоритма может быть параметр, позволяющий их проигнорировать (пример — LightGBM с параметром use_missing=False). Но таких опций может и не быть: линейная регрессия в scikit-learn просто объявит массив некорректным и выбросит исключение. Так что в её случае (как и в случае многих других алгоритмов) готовить данные к анализу всё-таки придётся пользователю.
Плюсы:
- Не надо думать об алгоритмах импутации — выставил соответствующие параметры и всё работает.
Минусы
- Нужно понимать, как именно алгоритм обойдётся с недостающими данными. В противном случае есть риск получить какие-нибудь артефакты и даже не узнать, какие именно.
Способ второй: импутация данных средним/медианой
Тоже не особенно сложно: считаем среднее или медиану имеющихся значений для каждого столбца в таблице и вставляем то, что получилось, в пустые ячейки. Естественно, этот метод работает только с численными данными.
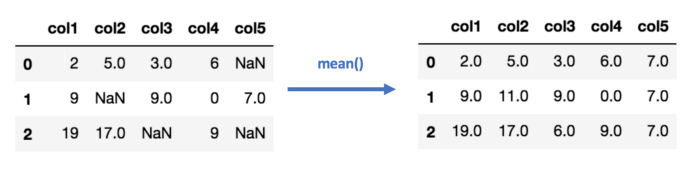
В коде это выглядит примерно так:
Плюсы:
- Просто и быстро.
- Хорошо работает на небольших наборах численных данных.
Минусы:
- Значения вычисляются независимо для каждого столбца, так что корреляции между параметрами не учитываются.
- Не работает с качественными переменными.
- Метод не особенно точный.
- Никак не оценивается погрешность импутации.
Способ третий: импутация данных самым частым значением или константой
Импутация самым часто встречающимся значением — ещё одна простая стратегия для компенсации пропущенных значений, не учитывающая корреляций между параметрами. Плюсы и минусы те же, что и в предыдущем пункте, но этот метод предназначен для качественных переменных.
В случае импутации нулём или константой (как можно догадаться из названия) все пропущенные значения в данных заменяются определённым значением.
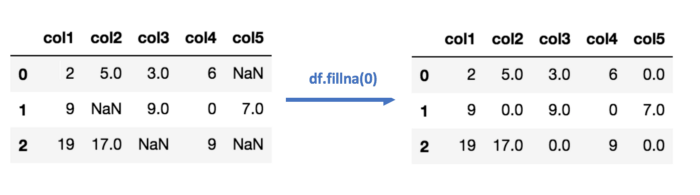
Способ четвёртый: импутация данных с помощью k-NN
k-Nearest Neighbour (k ближайших соседей) — простой алгоритм классификации, который можно модифицировать для импутации недостающих значений. Он использует сходство точек, чтобы предсказать недостающие значения на основании k ближайших точек, у которых это значение есть. Иными словами, выбирается k точек, которые больше всего похожи на рассматриваемую, и уже на их основании выбирается значение для пустой ячейки. Это можно сделать с помощью библиотеки Impyute:
Алгоритм сперва проводит импутацию простым средним, потом на основании получившегося набора данных строит дерево и использует его для поиска ближайших соседей. Взвешенное среднее их значений и вставляется в исходный набор данных вместо недостающего.

Плюсы:
- На некоторых датасетах может быть точнее среднего/медианы или константы.
- Учитывает корреляцию между параметрами.
Минусы:
- Вычислительно дороже, так как требует держать весь набор данных в памяти.
- Важно понимать, какая метрика дистанции используется для поиска соседей. Имплементация в impyute поддерживает только манхэттенскую и евклидову дистанцию, так что анализ соотношений (скажем, количества входов на сайты людей разных возрастов) может потребовать предварительной нормализации.
- Чувствителен к выбросам в данных (в отличие от SVM).
Способ пятый: импутация данных с помощью MICE
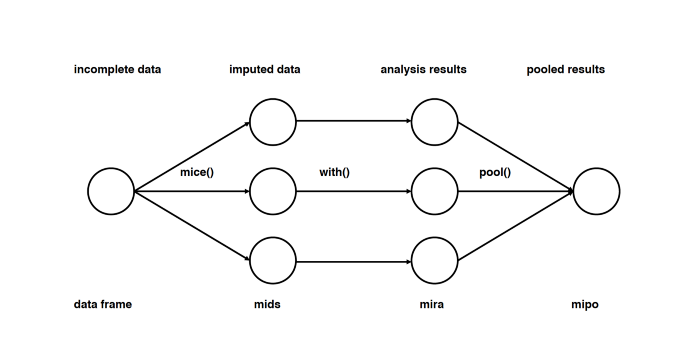
Этот подход основан на том, что импутация каждого значения проводится не один раз, а много. Множественные импутации, в отличие от однократных, позволяют понять, насколько надёжно или ненадёжно предложенное значение. Кроме того, MICE позволяет работать с переменными разных типов (например двоичными и количественными), а также со сложными штуками вроде предельных значений и паттернов артефактов в исходных данных. Подробный разбор математики есть в оригинальной статье.
Прим. пер. Судя по статье, метод MICE подразумевает не просто множественные импутации, а многократное повторение дальнейшего анализа на разных импутированных наборах данных и интеграцию получившихся результатов.
Способ шестой: импутация данных с помощью глубокого обучения
Показано, что глубокое обучение хорошо работает с дискретными и другими не-численными значениями. Библиотека datawig позволяет восстанавливать недостающие значения за счёт тренировки нейросети на тех точках, для которых есть все параметры. Поддерживается тренировка на CPU и GPU.
Плюсы:
- Точнее других методов.
- Может работать с качественными параметрами.
- Поддерживает CPU и GPU.
Минусы:
- Восстанавливает только один столбец.
- На больших наборах данных может быть вычислительно дорого.
- Нужно заранее решить, какие столбцы будут использоваться для предсказания недостающего значения.
Другие методы импутации данных
Стохастическая регрессия
Примерно похоже на регрессионную импутацию, в которой значения восстанавливаются регрессией от имеющихся значений для той же точки, но добавляет случайный шум.
Экстраполяция и интерполяция
Пытается восстановить значения на основании ограниченного набора известных точек.
Hot-deck
Значение берётся из другой точки, похожей по имеющимся параметрам на восстанавливаемую. Грубо говоря, это похоже на k-NN, но используется только один «сосед».
Как мы видим, универсального метода импутации не существует. Одни стратегии работают лучше на одних наборах данных или типах недостающих переменных, другие на других. Если не считать очевидных правил насчёт типов данных (например, у качественных переменных просто не может быть среднего), то можно только посоветовать экспериментировать и смотреть, какой метод сработает лучше на данном конкретном датасете.

13К открытий15К показов

Максим Коновалов расскажет, как стал Data Scientist в МТС, пройдя школу аналитиков данных МТС и стажировку.

Разберитесь с асинхронным программированием в Django 5.1: работа с async-вьюхами, ORM-запросами и системой миграций. Готовые примеры кода, решение типичных ошибок и лучшие практики для веб-разработчиков.

Что такое Edge AI. Показываем основные принципы и инструменты для работы с Edge AI. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger

Комплименты — боль многих айтишников. Но не переживайте, мы в редакции решили эту проблему: теперь у вас есть готовый бот, который будет отправлять красивые вашей второй половинке. Показываем, как он выглядит.