


Специалисты по data science тратят большую часть рабочего времени не на разработку продуктов

Дата-сайентисты часто сталкиваются с некачественными данными. В статье рассмотрены причины этого, а также возможные способы решения.
6К открытий6К показов

Антон Балтачев
младший инженер машинного обучения в Embedika
Дата-сайентисты часто сталкиваются с одной и той же проблемой — низким качеством исходных данных. Согласно отчету компании Anaconda, инженеры тратят на их очистку и подготовку половину своего рабочего времени — то есть столько же, сколько на разработку решений. В этой статье мы объясним, почему так происходит.
Работа с данными — первый и самый важный этап разработки data science-решений. Чем лучше подготовлены данные, тем быстрее и качественнее можно реализовать продукт.
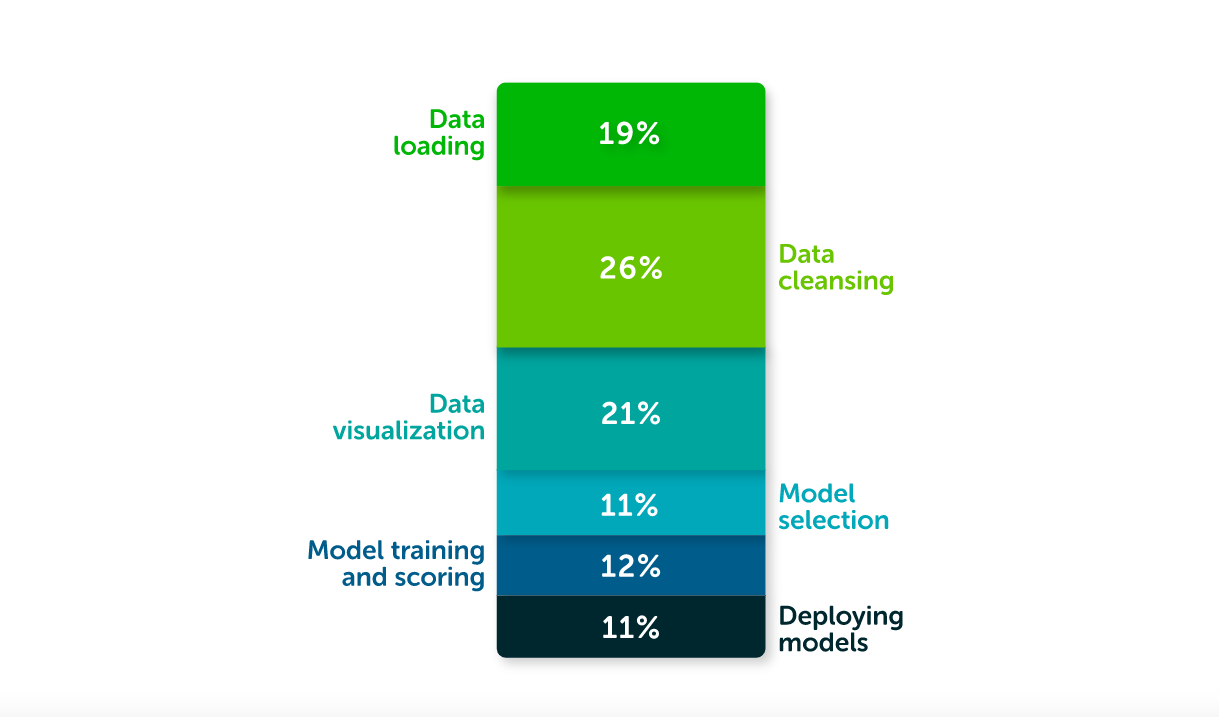
При подготовке отчета «Состояние data science в 2020» аналитики компании Anaconda опросили 2360 специалистов по data science и машинному обучению из более чем 100 стран. Исследование показало, что дата-сайентисты тратят 45% всего времени, необходимого для работы над проектом, на подготовку данных.
Большинство участников опроса сходятся во мнении, что сложность обработки исходных данных существенно сокращает время на остальные стадии разработки решения: выбор моделей (11%), обучение и оценку качества (12%) и деплой модели в продакшн (11%). Оставшийся 21% времени приходится на визуализацию данных.
Питер Ванг, генеральный директор и соучредитель Anaconda, считает, что у data science есть «безграничные возможности для преобразования бизнеса». Однако отрасль еще находится на этапе становления, а инженерам предстоит проделать большую работу, прежде чем удастся извлечь максимальную пользу из data science.
Что не так с данными?
Большинство данных в компаниях хранятся в разнообразных форматах: видео, аудиофайлы, текстовые документы, изображения. Чтобы сделать данные пригодными для использования, их необходимо сначала собрать в одном месте и привести к единому виду.
Согласно исследованию IBM, 80% всех данных в мире не структурированы. Если бизнес оперирует не всеми доступными данными, он получает лишь малую часть возможной пользы.
Сейчас необходимость заниматься рутинной работой вместо разработки сложных решений становится главной причиной потери мотивации среди дата-сайентистов, говорится в отчете.
«Получение данных является ключевой задачей в data science. Мы тратим 98% времени на сбор, поиск и очистку данных. Я не понимаю, почему при обучении профессии аналитика данных / дата-сайентиста нет специального курса, который фокусировался бы на этом процессе», — рассказал изданию Analytics India Magazine автор концепции хранилищ данных Билл Инмон.
Инженер машинного обучения в Embedika Антон Ложков считает, что решить проблему с качеством данных на практике можно с помощью развития унифицированных инструментов для обработки данных малыми усилиями — аналогичные решения уже существуют в других областях.
«В условиях разрозненности баз данных, многообразия способов их преобразования и форматов хранения, легко выбрать неоптимальное решение и потратить либо машинное время на обработку, либо человеческое — на поддержку запутанного пайплайна.
В мире серверной инфраструктуры есть проект Kubernetes, который позволил «подружить» сотни стандартов, интерфейсов и даже методологий распределенных сервисов. Этого удалось достичь с помощью титанических усилий со стороны сообщества: инженерам просто предоставили повод и инструменты для объединения их проектов в один конструктор. Нечто подобное для обработки и хранения данных позволяет делать стэк Apache Hadoop, который до сих пор ассоциируется у большинства специалистов с big data. Однако инертность больших корпораций не позволила ему развиваться так же динамично, как Kubernetes. Из-за этого молодые компании фокусируются на менее громоздких, но узкоспециализированных решениях. Остается надеяться, что новые поколения инженеров смогут объединить усилия для создания «Кubernetes для данных» и открыть новые возможности для индустрии».
Другие проблемы data science
Авторы исследования добавляют, что зависимость от менеджеров проектов снижает эффективность работы дата-сайентистов. Другая проблема — недостаток необходимых навыков: то, чему учат в университетах и на курсах, часто оказывается неэффективным в реальной работе, поэтому дата-сайентистам приходится многому учиться самостоятельно. Почти 50% опрошенных признались, что описанные проблемы мешают им продемонстрировать весь потенциал data science.
Компании испытывают недостаток в квалифицированных специалистах по data science. В отчете говорится, что отсутствие опыта (40%), технических (26%) и гибких (18%) навыков являются основными препятствиями для дата-сайентистов, которые мешают им получить работу мечты.
В качестве решения кадровой проблемы авторы отчета предлагают образовательным учреждениям расширить сотрудничество с IT-корпорациями по созданию курсов, которые позволят решать реальные проблемы бизнеса. Это позволит начинающим специалистам приобрести практический опыт и улучшить свои технические навыки.
Каков итог?
Авторы отчета заключают, что data science предстоит пройти долгий путь для полного раскрытия своего потенциала. Аналитики считают, что наука о данных постепенно доказывает свою важность для внедрения в бизнес-процессы компаний, однако для достижения максимального результата владельцы предприятий должны сосредоточиться на сборе данных. Одно из решений — найм дата-инженеров (data engineer), — специалистов, которые отвечают за очистку и подготовку данных со стороны заказчика.

6К открытий6К показов

Собрали топ-10 каналов для опытных разработчиков, с которыми у вас точно будет что обсудить на дейлике.

Выбираете первый язык программирования? Узнайте о низкоуровневых (C, C++), среднеуровневых (Java, C#) и высокоуровневых (Python, JavaScript) языках: плюсы, минусы и примеры применения. Чек-лист от экспертов поможет новичкам выбрать язык для веб, мобильной разработки или игр.

В статье разбираемся, почему Django — далеко не финиш в карьере, и в каких направлениях можно двигаться Python-разработчику.

Специализации в Data Science — дата-сайентист, аналитик, дата-инженер, ML-инженер. Кем стать.