


Пишем веб-приложение для распознавания лиц за час

Не столь давно Amazon выпустила сервис для распознавания изображений «Rekognition». Эта статья поможет вам познакомиться с этой удобной технологией.
27К открытий27К показов

Рассказывает Деван Сабаратнам, разработчик с 30-летним стажем
В минувшие выходные, пролистывая Amazon Web Services, я заметил новый сервис под названием «Rekognition». Я предположил, что это опечатка (recognition — англ. распознавание), но она привлекла мое внимание. Я заинтересовался: что это за сервис? Amazon привык добавлять новые сервисы в свою платформу с пугающей регулярностью, и этот я пропустил.
Я узнал, что в конце 2016 года Amazon выпустила свой собственный сервис для распознавания изображений на базе глубокого обучения на их платформе. Он может распознавать не только лица, но и объекты на фото. Так как сервис довольно новый, подробностей о нём было немного, но мне захотелось немедленно попробовать его. В общем, в течение часа я написал пример веб-страницы, которая может получать фотографии с моей веб-камеры и выполнять элементарное распознавания лица на нем.
Прим. перев. Чтобы не теряться в многочисленных сервисах Amazon, советуем вам прочитать нашу шпаргалку по AWS.
Раньше я занимался технологией распознавания лиц, используя сторонние библиотеки, а также Microsoft Face API, но все попытки создания подобного приложения не увенчались успехом. Но, просматривая документацию «Rekognition», я понял, что AWS API на самом деле очень прост в использовании. Я немедленно принялся за работу.
Цель
Мне была нужна простая веб-страница, которая позволила бы делать фотографию с помощью камеры моего iMac и выполнять распознавание на фотографии. В частности, я хотел бы определять пользователя, сидящего перед компьютером.
Сервис Amazon Rekognition позволяет создавать одну или несколько коллекций. Коллекция — это набор лицевых векторов для фотографий, которые вы хотите сохранить.
Примечание: Сервис сохраняет не фотографии, а их JSON-представление.
После создания коллекции вы можете сфотографировать предмет, сравнить его свойства c сохранёнными и вернуть ближайшее соответствие. Звучит просто, не так ли? По правде говоря, разработка фронтенда веб-страницы для получения данных с камеры заняла больше времени, чем написание бэкенда для распознавания.
В общем, веб-страница позволяет создавать или удалять коллекцию лицевых данных на Amazon, загружать новые данные, полученные из фотографии, в свою коллекцию и сравнивать новые фотографии с существующей коллекцией, чтобы найти совпадение. А в качестве дополнительной фичи я также добавил в эту демку службу Amazon Polly, чтобы после распознавания фотографии страница приветствовала пользователя.

Фронтенд
Я не знал, какую библиотеку использовать для захвата изображения с помощью камеры iMac. В итоге я нашел на GitHub библиотеку JPEG Camera, которая позволяет использовать HTML5 Canvas или Flash для съёмки фото. Я решил использовать её и настроил под себя написанный на JavaScript образец.
Бэкенд
Для бэкенда я использовал Ruby-библиотеку Sinatra, которая может выполнять всю тяжёлую работу с помощью AWS. Я часто использовал Sinatra (на самом деле Padrino) в своих проектах и настоятельно рекомендую эту платформу.
Примечание: Amazon Rekognition предлагает сначала загружать исходные фотографии, которые использует его API, в Amazon S3, а затем обрабатывать их. Я хотел избежать этого ненужного шага и вместо этого отправлять изображения непосредственно в API, что мне в итоге удалось сделать.
Я сумел сделать то же самое с их приветствием Polly . Вместо того, чтобы сохранять аудио в MP3-файл и проигрывать его, у меня получилось закодировать данные MP3 непосредственно в тег <audio> на странице и воспроизвести их оттуда.
Код
Я разместил весь код этого проекта на моей странице на GitHub. Не стесняйтесь использовать и изменять его. Ниже я постараюсь объяснить код более подробно.
Пишем приложение
Прежде всего, вам понадобится учетная запись Amazon AWS. Я не буду вдаваться в подробности, поскольку это несложно, а в случае затруднений можно легко найти информацию в Интернете.
Создание пользователя AWS IAM
Как только вы создали учетную запись AWS, первое, что нам нужно сделать, — создать пользователя Amazon IAM (Identity & Access Management), который имеет права на использование службы Rekognition. Мы также зададим права для Amazon Polly.
В консоли Amazon нажмите на кнопку «Сервисы» в верхнем левом углу, затем выберите «IAM». В меню слева выберите «Пользователи». Вы должны увидеть список существующих пользователей IAM, которых вы создали в консоли, если вы делали это в прошлом.

Нажмите кнопку «Добавить пользователя», расположенную в верхней части списка, чтобы добавить нового пользователя IAM.
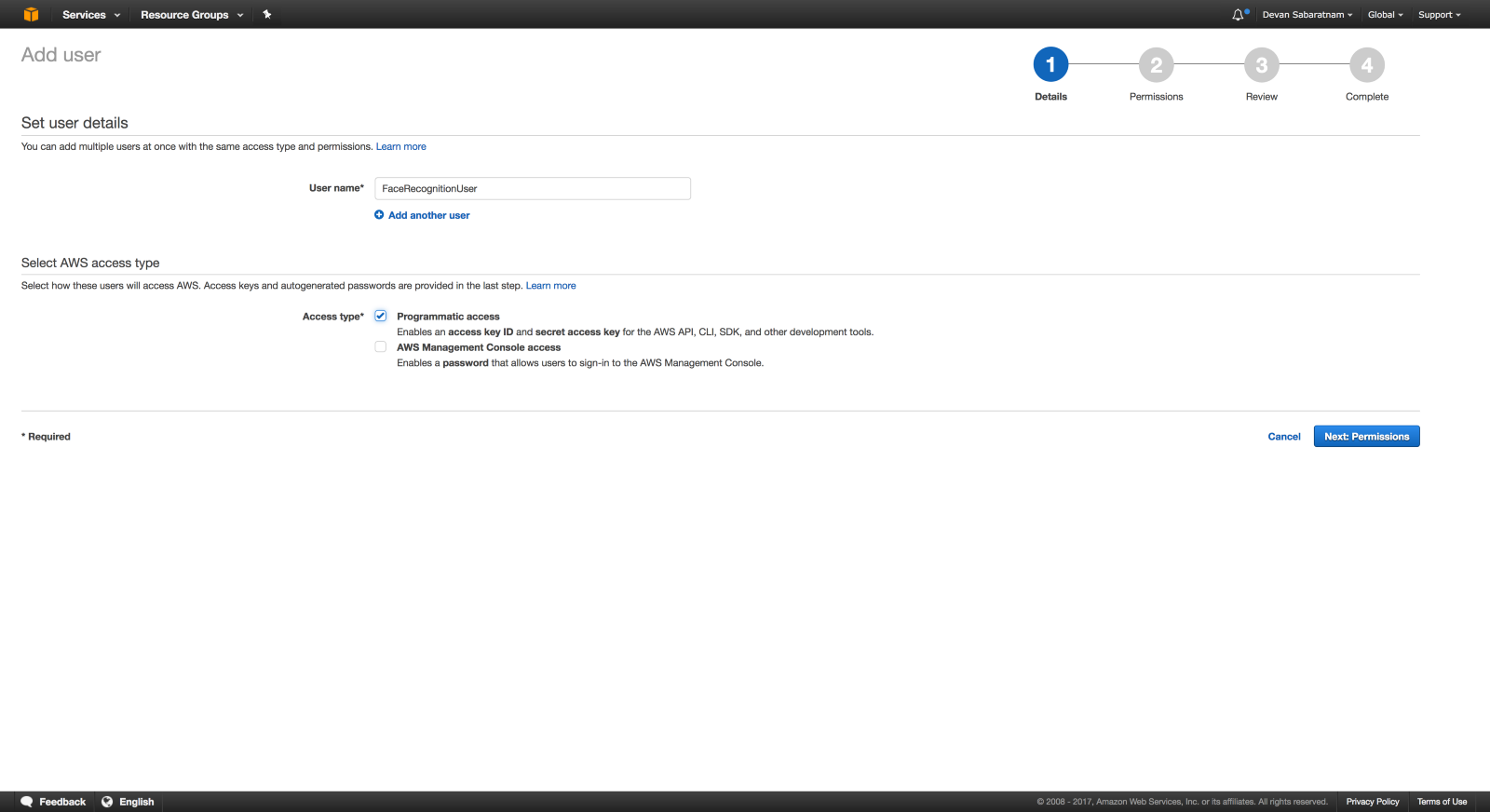
Дайте пользователю имя и убедитесь, что вы отметили пункт «Programmatic Access», так как вы будете использовать этот IAM в вызове API.
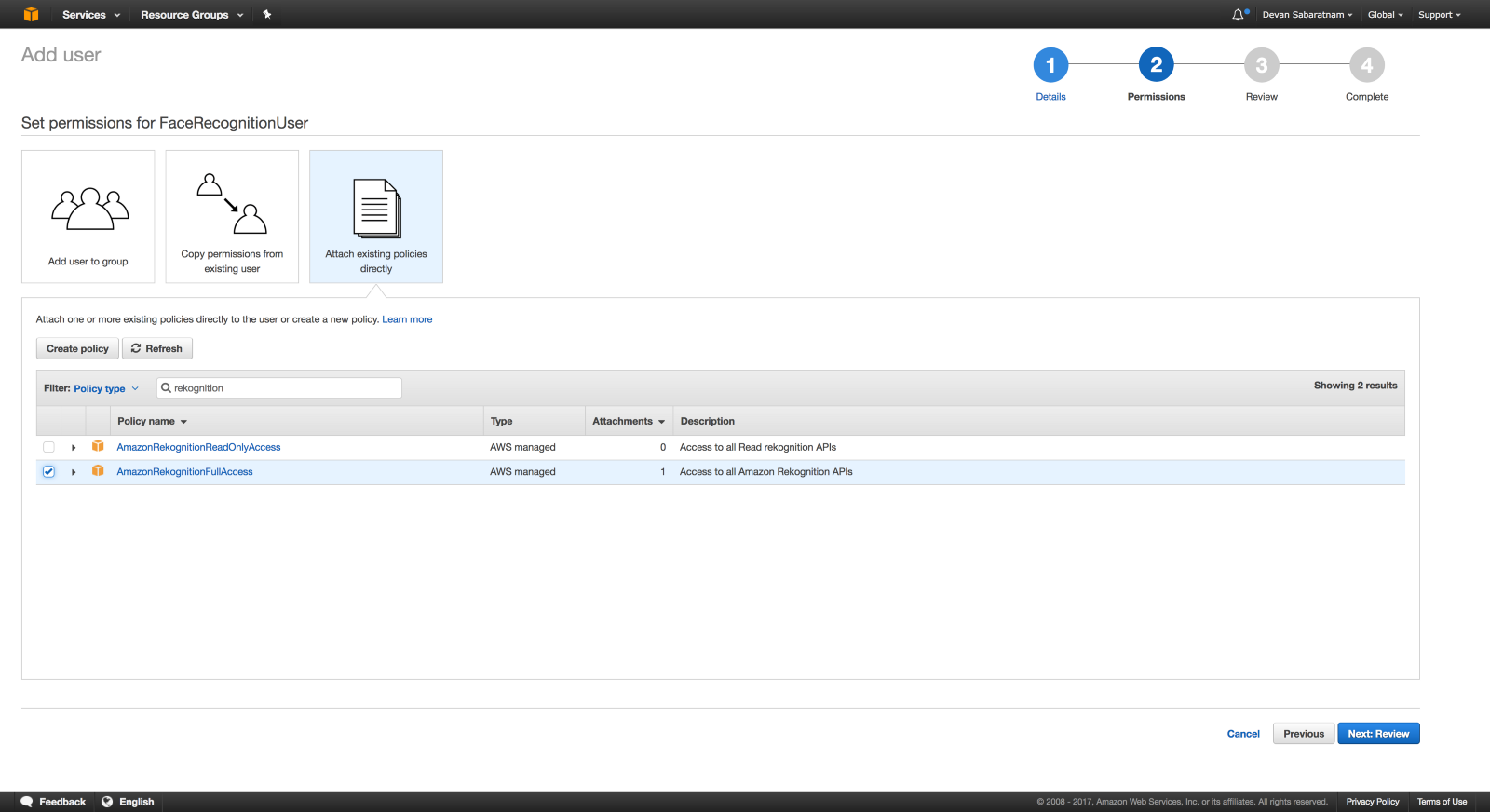
Далее приведены настройки разрешений. Убедитесь, что вы щелкаете по третьему квадратику на экране с надписью «Attach existing policies directly». Затем в поле поиска «Filter: Policy Type» введите «rekognition». Выберите «AmazonRekognitionFullAccess» из списка, поставив рядом с ним галочку.
Затем измените фильтр поиска на «polly» и поместите галочку рядом с «AmazonPollyFullAccess».
Теперь у этого IAM есть права, достаточные для Amazon Rekognition и Amazon Polly. Нажмите «Next: Review» в правом нижнем углу.
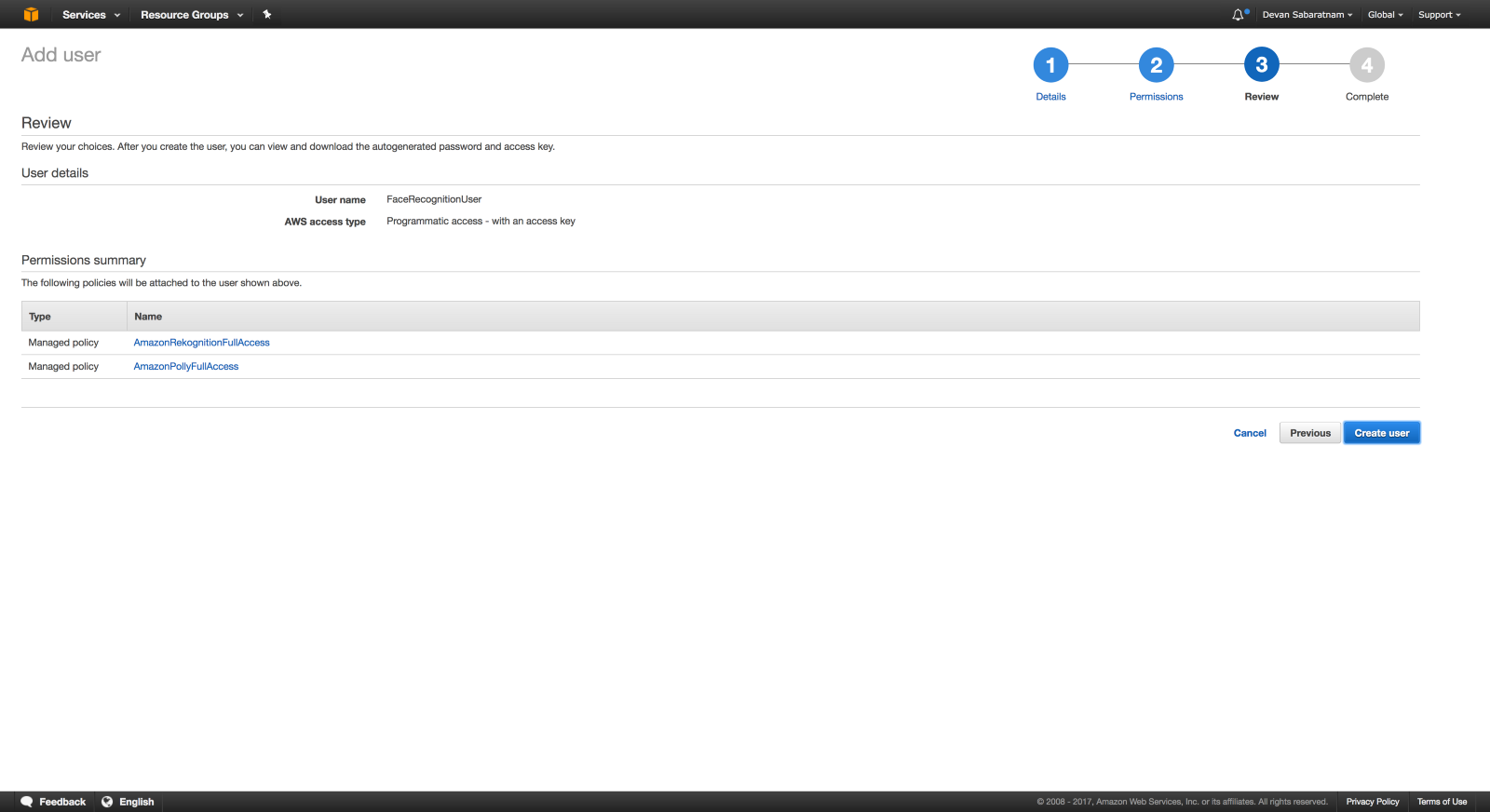
На странице просмотра вы должны увидеть 2 политики использования, дающие вам полный доступ к Rekognition и Polly. Если вы их не видите, вернитесь и повторите предыдущий шаг. Затем нажмите кнопку «Создать пользователя» в правом нижнем углу.

Эта страница важна. Запишите ключи AWS Key и AWS Secret, которые вы указали на этой странице, поскольку нам необходимо включить их в наше приложение ниже.
Это единственный раз, когда вам будут показаны эти ключи, поэтому сохраните их и файл CSV с этой страницы в надёжном месте.
Загрузка кода
Теперь загрузите пример кода с моей страницы GitHub, чтобы вы могли изменить его по мере необходимости. Загрузите код в виде ZIP-файла, либо склонируйте его в вашу рабочую папку.
Первое, что вам нужно сделать, — это создать файл с именем .env в рабочей папке и ввести эти две строки, заменив в них ключи Amazon IAM на свои:
Теперь, если у вас установлен Ruby (не Ruby on Rails), то для установки зависимостей запустите команду:
Для запуска приложения введите эту команду:
Она должна запустить веб-браузер на порте 4567, чтобы вы могли увидеть веб-страницу и начать тестирование:
Использование приложения
Сама веб-страница довольно проста. Вы должны увидеть потоковое изображение в верхней части экрана, которое представляет собой канал с вашей веб-камеры.
Сперва создайте коллекцию, щелкнув по ссылке в самом нижнем левом углу страницы. Это создаст пустую коллекцию на серверах Amazon для хранения ваших изображений. Обратите внимание: имя по умолчанию для этой коллекции — faceapp_test, но вы можете изменить его в коде faceapp.rb (строка 17).
Затем, чтобы начать добавление лиц в свою коллекцию, попросите нескольких людей сесть перед вашим компьютером или телефоном и убедиться, что их лицо находится только в рамке для фотографий (несколько лиц сделают сканирование неудачным). Когда всё будет готово, введите их имя в текстовое поле и нажмите кнопку «Добавить в коллекцию». Должно появиться сообщение о том, что данные о лице были добавлены в базу данных.
После того, как вы создали несколько лиц в своей базе данных, вы можете попросить случайного человека сесть перед камерой и нажать «Сравнить изображение». Если этот человек уже добавлен в коллекцию, на экране должно появиться его имя.
Обратите внимание, что обычный способ работы Amazon Rekognition заключается в том, чтобы загружать фотографию в Amazon S3 Bucket, а затем обрабатывать его оттуда, но я хотел обойти этот шаг и фактически отправить данные фотографии непосредственно в Rekognition как поток байтов, закодированный в Base64. К счастью, aws-sdk для Ruby позволяет использовать оба метода.
Разбор кода
Прежде всего, давайте взглянем на HTML-страницу:
Структура страницы проста: всего несколько блоков, кнопок и ссылок. Обратите внимание, что мы используем jQuery, а также Moment.js для настраиваемого приветствия. Следует обратить внимание на код faceapp.js, который выполняет все сложные задачи и ссылки на библиотеку камер JPEG.
Вы также можете заметить теги <audio> в нижней части файла — это аудио-приветствие, которое мы отправляем пользователю.
Теперь разберем JS-файл приложения:
Это настраивает библиотеку JPEG Camera, чтобы отображать канал на экране и обрабатывать загрузку изображений.
Функция add_to_collection() захватывает изображение с камеры, а затем выполняет запись в конечную точку /upload вместе с именем пользователя в качестве параметра. Функция проверяет, действительно ли вы ввели имя, которое нужно в качестве уникального идентификатора этих данных.
Функция загрузки проверяет вызов и выводит сообщение об успешном завершении или ошибке.
Функция compare_image() вызывается, когда вы нажимаете кнопку «Сравнить изображение». Она захватывает кадр из камеры и передает POST-данные в /compare. Эта конечная точка вернет либо ошибку, либо структуру JSON, содержащую id (имя) найденного лица, а также процент схожести.
Если лицо совпадёт с данными из коллекции, функция отправит имя найденного лица в /speech. Эта конечная точка вызывает службу Amazon Polly, чтобы преобразовать приветствие в файл MP3, который можно воспроизвести пользователю.
Служба Amazon Polly возвращает приветствие в виде бинарного потока MP3, поэтому мы берем этот поток ввода-вывода, шифруем его в формате Base64 и помещаем в качестве закодированной исходной ссылки в теги <audio> на нашей веб-странице. Затем мы можем вызвать .play() для воспроизведения MP3 через динамики пользователя с помощью HTML5 Web Audio API.
Прим. перев. Вы можете узнать о Web Audio побольше, прочитав нашу серию статей по этой теме.
Наконец, в JS-файле приложения есть функция greetingTime(). Она решает, стоит ли говорить «доброе утро / день / вечер» в зависимости от времени суток пользователя.
Теперь взглянем на код Ruby:
Здесь задан блок настройки конфигурации аутентификации AWS и имени коллекции по умолчанию, которое мы будем использовать (вы можете его свободно менять).
Остальная часть кода — это конечные точки, которые Sinatra будет слушать. Он прослушивает GET в /, чтобы отобразить фактическую веб-страницу конечному пользователю, а также слушает вызовы POST к /upload, /compare и /speech, которым JS-файл отправляет данные. Только 3–4 строки кода для каждой из этих конечных точек фактически выполняют задачи распознавания лиц и речи. Подробнее о них можно узнать из документации AWS SDK.

27К открытий27К показов

Лучшие курсы по фреймворку Vue.js. Рейтинг вариантов онлайн-обучения бесплатно и платно, обзор обучающей программы и стоимости курсов.

До лета 2023 года перед разработчиками Точка Нетворк стояла проблема: CJM становился сложным, и это затрудняло работу над продуктом. В итоге мы придумали решение — полностью отказались от веба и сосредоточили развитие платформы только в Mini Apps от Телеграма. Без этого было бы невозможно развивать продукт дальше.
В статье расскажу, как и почему мы отказались от веб-версии Точка Нетворк — локального сообщества предпринимателей — и переместились в Телеграм.

Чек-лист для Node.js новичков. Показываем основные подходы к обработке ошибок. Рассматриваем пошаговую инструкцию и практические примеры ✔ Tproger

Разберитесь с асинхронным программированием в Django 5.1: работа с async-вьюхами, ORM-запросами и системой миграций. Готовые примеры кода, решение типичных ошибок и лучшие практики для веб-разработчиков.