


Автостопом по машинному обучению на Python
В этой статье кратко описаны восемь главных алгоритмов машинного обучения и то, как использовать их на практике. Будет полезно для структурирования знаний.
61К открытий67К показов

Машинное обучение на подъеме, этот термин медленно забрался на территорию так называемых модных слов (buzzword). Это в значительной степени связано с тем, что многие до конца не осознают, что же на самом деле означает этот термин. Благодаря анализу Google Trends (статистике по поисковым запросам), мы можем изучить график и понять, как рос интерес к термину «машинное обучение» в течение последних 5 лет:

Цель
Но эта статья не о популярности машинного обучения. Здесь кратко описаны восемь главных алгоритмов машинного обучения и их использование на практике. Обратите внимание, что все модели реализованы на Python и у вас должно быть хотя бы минимальное знание этого языка программирования. Подробное объяснение каждого раздела содержится в прикрепленных англоязычных видео. Сразу оговоримся, что полным новичкам этот текст покажется сложным, он скорее подходит для продолжающих и продвинутых разработчиков, но главы материала можно использовать как план для построения обучения: что стоит знать, в чем стоит разобраться в первую очередь.
Классификация
Не стесняйтесь пропускать алгоритм, если чего-то не понимаете. Используйте это руководство так, как пожелаете. Вот список:
- Линейная регрессия.
- Логистическая регрессия.
- Деревья решений.
- Метод опорных векторов.
- Метод k-ближайших соседей.
- Алгоритм случайный лес.
- Метод k-средних.
- Метод главных компонент.
Наводим порядок
Вы явно расстроитесь, если при попытке запустить чужой код вдруг окажется, что для корректной работы у вас нет трех необходимых пакетов, да еще и код был запущен в старой версии языка. Поэтому, чтобы сохранить драгоценное время, сразу используйте Python 3.6.2 и импортируйте нужные библиотеки из вставки кода ниже. Данные брались из датасетов Diabetes и Iris из UCI Machine Learning Repository. В конце концов, если вы хотите все это пропустить и сразу посмотреть код, то вот вам ссылка на GitHub-репозиторий.
Линейная регрессия
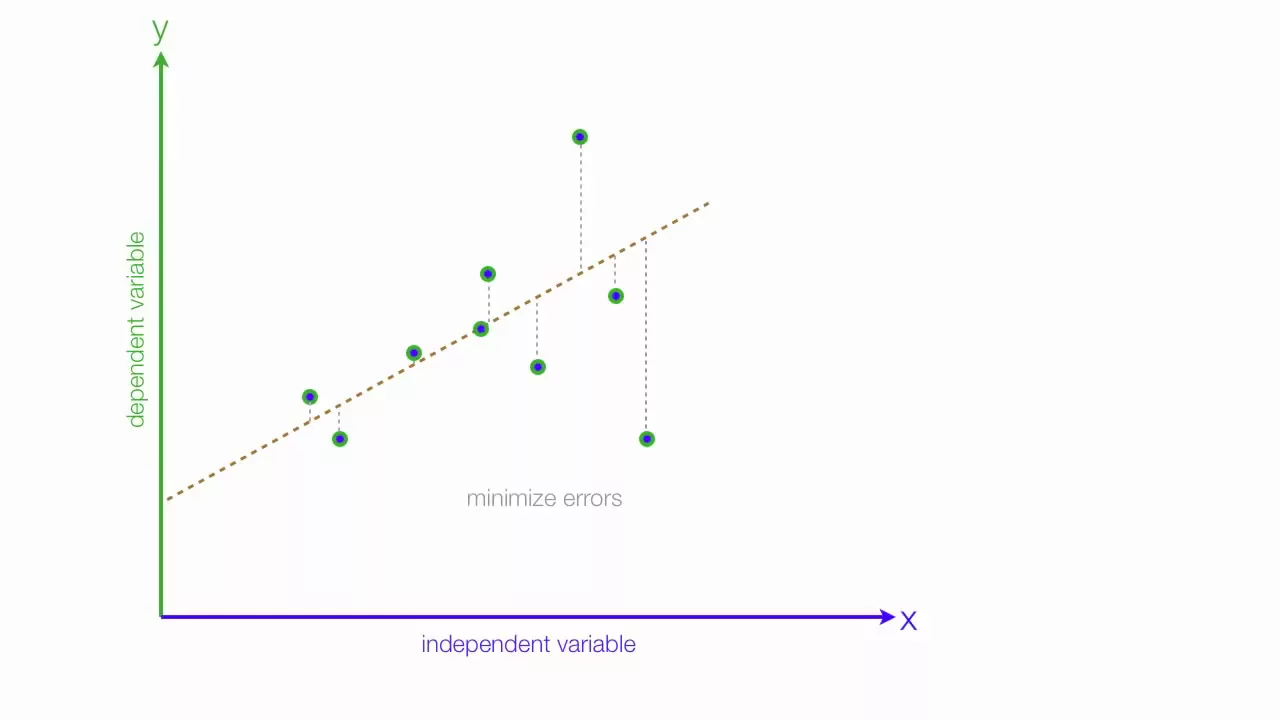
Возможно, это самый популярный алгоритм машинного обучения на данный момент и в то же время самый недооцененный. Многие специалисты по анализу данных забывают, что из двух алгоритмов с одинаковой производительностью лучше выбирать тот, что проще. Линейная регрессия — это алгоритм контролируемого машинного обучения, который прогнозирует результат, основанный на непрерывных функциях. Линейная регрессия универсальна в том смысле, что она имеет возможность запускаться с одной входной переменной (простая линейная регрессия) или с зависимостью от нескольких переменных (множественная регрессия). Суть этого алгоритма заключается в назначении оптимальных весов для переменных, чтобы создать линию (ax + b), которая будет использоваться для прогнозирования вывода. Посмотрите видео с более наглядным объяснением.
Теперь, когда вы поняли суть линейной регрессии, давайте пойдем дальше и реализуем ее на Python.
Начало работы
Визуализация
Реализация
Логистическая регрессия
Логистическая регрессия – алгоритм контролируемой классификации. Она позволяет предсказывать значения непрерывной зависимой переменной на интервале от 0 до 1. Когда начинаешь изучать логистическую регрессию, складывается впечатление, что это своего рода узкоспециализированная вещь, и поэтому не уделяешь ей должного внимания. И лишь позже понимаешь, что очень ошибался. Некоторые из основных аспектов логистической регрессии лежат в основе других важных алгоритмов машинного обучения, например, для повышения точности прогноза нейросетевой модели. Имейте это в виду и смотрите видео ниже.

Теперь попробуем реализовать этот алгоритм на Python.
Начало работы
Визуализация
Реализация
Деревья решений
Метод деревьев решений (decision trees) – это один из наиболее популярных методов решения задач классификации и прогнозирования. Опыт показывает, что чаще всего данный алгоритм используется именно для классификации. На входе модель принимает набор атрибутов, характеризующих некую сущность, а затем спускается по дереву, тестируя их в зависимости от того, какие значения может принимать целевая функция. Таким образом, классификация каждого нового случая происходит при движении вниз до листа, который и укажет нам значение целевой функции в каждом конкретном случае. Деревья принятия решений становятся все более популярными и могут служить очень сильным инструментом для аналитики данных, особенно в сочетании с простыми методами композиции, такими как случайный лес, бустинг и бэггинг. И снова просмотрите видео ниже, чтобы более подробно изучить базовую функциональность деревьев решений.

А теперь по традиции перейдем к практике и реализуем данный алгоритм на Python.
Начало работы
Реализация
Визуализация
Метод опорных векторов
Метод опорных векторов, также известный как SVM, является широко известным алгоритмом классификации, который создает разделительную линию между разными категориями данных. Как этот вектор вычисляется, можно объяснить простым языком — это всего лишь оптимизация линии таким образом, что ближайшие точки в каждой из групп будут наиболее удалены друг от друга.
Этот вектор установлен по умолчанию и часто визуализируется как линейный, однако это не всегда так. Вектор также может принимать нелинейный вид, если тип ядра изменен от типа (по умолчанию) «гауссовского» или линейного. Несколькими предложениями данный алгоритм не опишешь, поэтому просмотрите учебное видео ниже.

И по традиции реализация на Python.
Начало работы
Реализация
Визуализация
Метод k-ближайших соседей
K-Nearest Neighbors, или KNN, представляет собой контролируемый алгоритм обучения, который используется преимущественно для решения задач классификации. Данный алгоритм наблюдает за разными центрами (центроидами) и сравнивает расстояние между ними, используя для этого различные функции (обычно евклидово расстояние). Затем определяется, к какому классу принадлежит большинство ближайших объектов обучающей выборки – к этому классу относится и неизвестный объект. Посмотрите видео для того, чтобы увидеть что происходит за кулисами данного алгоритма.

Теперь, когда вы поняли общую концепцию метода k-ближайших соседей, давайте напишем реализацию на Python.
Начало работы
Визуализация
Реализация
Случайный лес
Случайный лес — популярный алгоритм контролируемого обучения, заключающийся в использовании комитета (ансамбля) решающих деревьев. «Ансамбль» означает, что он берет кучу «слабых учеников» и объединяет их, чтобы сформировать один сильный предиктор. «Слабые ученики» — это все случайные реализации деревьев решений, которые объединяются для формирования сильного предсказателя — случайного леса. Все не объяснить. Смотрите видео ниже.
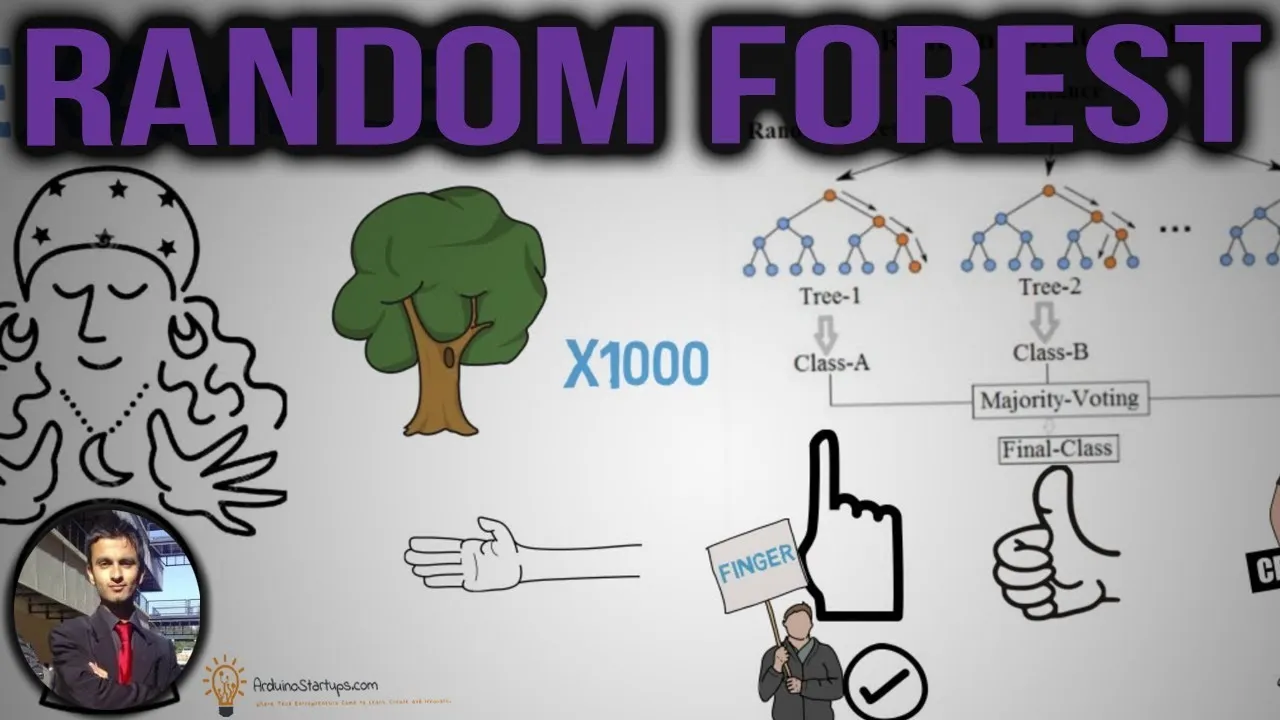
Теперь мы знаем, что такое случайный лес, пришло время реализации кода на Python.
Начало работы
Реализация
Метод k-средних
Метод k-средних — это популярный алгоритм неконтролируемой классификации обучения, обычно используемый для решения проблемы кластеризации. K обозначает количество введенных пользователем кластеров. Алгоритм начинается со случайно выбранных точек, а затем оптимизирует кластеры при помощи функций (евклидово расстояние и т. д), чтобы найти наилучшую группировку точек данных. В итоге специалистам по большим данным необходимо выбрать правильное значение K. Вы уже знаете, что для полноты картины нужно посмотреть видео.

Теперь, когда вы знаете чуть больше о кластеризации k-средних, давайте реализуем алгоритм на Python.
Начало работы
Реализация
Визуализация
Метод главных компонент
PCA (Principal Component Analysis) — алгоритм сокращения размерности, который может быть очень полезен для аналитиков. Главное — это то, что данный алгоритм может значительно уменьшить размерность данных при работе с сотнями или даже тысячами различных функций. Данный алгоритм не контролируется, но пользователь должен анализировать результаты и следить за тем, чтобы сохранялось 95% или около этой цифры первоначального набора данных. Не забудьте про видео, ведь оно расскажет намного больше об этом интересном алгоритме.

Реализация на Python.
Начало работы
Реализация
Подводим итоги
В данном учебном пособии, мы, не углубляясь, прошлись по всем важным на сегодняшний день алгоритмам машинного обучения. Во время вашего путешествия к мастерству в машинном обучении эта статья поможет вам систематизировать знания в голове.

61К открытий67К показов

Лучшие курсы по автотестированию. Рейтинг вариантов онлайн-обучения для тестировщиков, обзор обучающей программы и стоимости курсов.

Сравниваем GPU-хостинги 2025 года по ценам, доступности и гарантиям SLA.

Вышел Python 3.14 RC1 с JIT-компилятором и free-threaded режимом — релиз уже доступен, финальная версия выйдет в октябре

OpenAI ChatGPT o1 иногда «думает» на китайском из-за особенностей обучения и оптимизации модели, вызвав вопросы у пользователей