


Команды терминала Linux для начинающих. Часть первая

В этой статье рассказываем про работу с процессами и файлами, про навигацию, каналы, xargs, awk и grep. Тут вы узнаете про многие полезные инструменты и трюки. Советуем к прочтению не только начинающим, но и профи.
37К открытий39К показов
Возможно, вы уже знаете некоторые команды терминала Linux, умеете работать с файлами, каталогами и осуществлять редактирование, например: cd, ls, pwd, cat. Но в данном обзоре всё изложено как можно конкретнее, чтобы предусмотреть распространённые вопросы.
Основы в терминале Linux
Ниже представлена схема типичной команды в терминале ОС Linux:
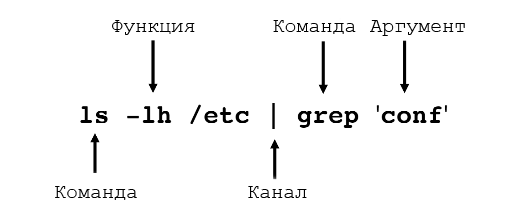
Следующие команды позволят вам лучше узнать систему:
id— если вы хотите получить информацию касательно вашей учётной записи;w— чтобы понимать, кто на данный момент находится в системе (-f— для того, чтобы узнать, откуда был совершен вход);lsblk— если вы хотите открыть список блочных устройств хранения данных;lscpu— отображает информацию о процессорах;lstopo— предоставляет доступ к топологии аппаратного ПО отображения информации (требуются пакетыhwloc,hwloc-gui);free— показывает объём свободной и уже используемой памяти (используйте такжеfree -g);lsb_release -a— если вы хотите получить информацию о распределении данных;
Примечание Для PS0: используйте Ctrl+C, чтобы деактивировать неактуальные команды. Что касается PS1: некоторые команды могут быть недоступны. Чтобы проверить, какие именно, введите which <cmdname>.
Работа с процессами
Для начала создайте список процессов по имени, идентификационного номеру процесса и т. д. (обычно используемый признак состояния aux).
Учитывайте особенности реализации программных потоков: POSIX, GNU и BSD, а также то, что они отличаются в работе и применении. Вышеуказанные реализации отличаются различными опциями: POSIX (-), GNU (–), BSD (без тире).
Индикаторы процесса в данной системе: top, htop, atop.
Понижайте приоритет процесса, используя nice. Например, следующим образом:
nice -n 19 tar cvzf archive.tgz large_dir
Чтобы аннулировать процесс, введите kill <pid>. Данная команда используется для завершения процессов-зомби или прекращения зависших сеансов.
Далее идут команды терминала Linux, которые спасут положение в затруднительных ситуациях:
man nano— данная команда обеспечивает доступ к организованным по разделам справочным страницам. Итого на каждый раздел — одна страница. Например:5 passwd #5й раздел;wget --help— весьма удобная команда, которая позволит быстро получить справку по синтаксису;info curl— позволяет получить информацию о команде (в данном случае оcurl);/usr/share/doc— используйте в браузере. В случае проблемы, не забывайте, что обычно файлы README содержат информацию и примеры команд. Просмотр осуществляется с помощью браузера.
Работа с файлами
Следующие команды потребуются вам при работе с файлами разного типа и объёма:
cat— для относительно коротких файлов:cat states.txt;less— считывает текст не полностью, а небольшими фрагментами:less /etc/ntp.conf;more— для длинных файлов;tail -f— используется для просмотра растущего файла в окне интерактивного запуска кода.
Что вы можете сделать с двоичными файлами? На самом деле, вариантов не очень много:
strings— команда выведет готовые к печати строки файла;od— позволит вам напечатать файл в восьмеричном формате;cmp— даёт возможность побайтно сравнивать файлы.
Если вам требуется сравнить текстовые файлы друг с другом, введите следующие команды:
comm— отсортированные файлы будут строка за строкой;diff— позволяет построчно выявить различия. Эта команда используется наиболее часто в силу богатого набора опций.
Интернет в командной строке
При работе в терминале Linux с интернет-ресурсами применяйте следующие команды:
curl— обычно используется для загрузок из интернета:curl -O http://www.gutenberg.org/files/4300/4300-0.txtcurl ifconfig.me #быстро определяет ваш IDwget— аналогичная команда:wget http://www.gutenberg.org/files/4300/4300-0.txtwget https://kubernetespodcast.com/episodes/KPfGep{001..062}.mp3lynx— позволяет использовать достаточно удобный текстовый браузер. Под удобным в данном случае подразумевается, что вы:сможете наконец-то избавиться от постоянно всплывающих рекламных окон;решите проблему с медленным/зависающим интернетом, например: lynx text.npr.org;сможете иметь доступ к локальным html-страницам, например, к тем, что можно найти с помощью /usr/share/doc;w3mиlinks— дополнительные текстовые браузеры:w3m lite.cnn.com.
Горячие клавиши
Навигация

Ctrl+] <char> перемещает курсор на первое вхождение <char> вправо.
Ctrl+alt+] <char> перемещает курсор на первое вхождение <char> влево.
Удаление

Используйте Ctrl+Y, чтобы вставить обратно удалённые файлы.
Дополнительно
- Alt+. — если требуется вставить последний аргумент предыдущей команды;
- Alt-
<N>-Alt-. — если требуется использовать N-й аргумент предыдущей команды; - Ctrl+L — используется для очистки терминала;
- cd – — требуется для внесения изменений в предыдущий каталог;
- cd — перейти в домашний каталог;
- Ctrl+R — обзор истории;
- Ctrl+D — выход из терминала.
Подстановочные символы
Далее приведены подстановочные символы, которые расширяют объём команды терминала Linux во время её выполнения:
*позволяет расширить команду до любого количества символов:ls -lh /etc/*.conf— все элементы с расширением .conf;?позволяет расширить команду до одного символа:ls -ld ? ?? ???— сюда относятся элементы, длина которых составляет 1, 2 или 3 символа;!— отрицание:ls -ld [!0-9]*— элементы, которые не начинаются с числовых значений;- Экранирование и цитирование с целью предотвращения расширения:\ для экранирования подстановочного знака;' для цитирования подстановочного знака.
Хитрости, которые сэкономят время
Этот список полезных знаков позволит вам в разы ускорить работу с командами:
!!— повторяет последнюю команду;!$— позволяет изменить команду, сохраняя последний аргумент:cat states.txt — используется, если файл слишком длинный, чтобы поместиться на экране;less !$ — используется для повторного открытия в меньшем объёме;!*—позволяет изменить команду, сохраняя при этом все аргументы:head states.txt | grep '^Al' — при использовании должен быть хвост;tail !* — нет необходимости вводить остальную часть команды;>x.txt— используется для создания пустого файла или очистки существующего.lsof -P -i -n— позволит определить, к каким скриптам идёт обращение со стороны веб-сервера.
Потоки ввода-вывода терминала и переадресация
В терминале Linux работа осуществляется через три потока ввода-вывода: вход (stdin), выход (stdout) и ошибка (stderr).
Данные потоки представлены файловыми дескрипторами. Их также принято считать идентификаторами: 0 для stdin, 1 для stdout, 2 для stderr.
Использование угловых скобок применяется для перенаправления (переадресации) команд и файлов в них и из них:
>для отправления в поток;<для получения из потока;>>для добавления в поток;<<для непосредственного присоединения потока (используется в «heredoc»);<<<используется в «herestring» (на сегодняшний день не особо распространенная команда);&используется для записи в поток, например&1для записи вstdout.
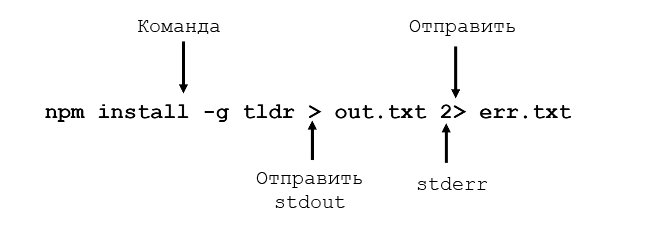
Дополнительные примеры переадресации приведены ниже:
- чтобы отправить
stdoutиstderrв один и тот же файл (короткий вариант bash v4+)pip install rtv > stdouterr.txt 2>&1 ac -pd &> stdouterr.txt; - чтобы пропустить и
stdout, иstderr:wget imgs.xkcd.com/comics/command_line_fu.png &> /dev/null/dev/null— это «нулевой» файл для удаления потоков. А ещё это паблик со смешными мемами для ITшников (ВК и Телеграм); - чтение из
stdinв качестве вывода команды:diff <(ls dirA) <(ls dirB); - добавить
stdoutв файл журналаsudo yum -y update >> yum_update.log.
Каналы
Канал — это особая концепция системы Linux, которая автоматизирует перенаправление вывода одной команды посредством использования входных данных на следующую команду. Такое использование каналов приводит к эффективным комбинациям независимых команд. Ниже приведены некоторые из них:
find .| less— позволяет прокручивать длинный список файлов постранично;head prose.txt | grep -i 'little' echo $PATH | tr ':' '\n'— переводит на новую строку;history | tail— отображает последние 10 команд;free -m|grep Mem:|awk '{print $4}'— отображает доступную память;du -s *|sort -n|tail— отображает 10 наиболее больших файлов/каталогов в pwd.
Расшифровка и отладка команд каналов
free -m|grep Mem:|awk '{print $4}'
Приведённая выше команда эквивалентна выполнению следующих 4 команд:
free -m > tmp1.txtgrep Mem: tmp1.txt > tmp2.txtawk '{print $4}' tmp2.txtrm tmp1.txt tmp2.txt
Сокращение этапов работы с командами зачастую является эффективным и более простым способом, который позволяет сэкономить время и упростить процесс. Например, вышеупомянутый конвейер можно уменьшить следующим образом:
free -m|awk '/Mem:/{print $4}'
Ниже приведено ещё несколько примеров каналов:
Чтобы получить доступ к pdf-файлам страниц справочника man:
man -t diff | ps2pdf - diffhelp.pdf
Чтобы получить актуальные на сегодняшний день файлы:
ls -al --time-style=+%D | grep `date +%D`
Топ-10 самых часто используемых команд:
history | awk '{a[$2]++}END{for(i in a){print a[i] " " i}}' | sort -rn | head
Далее будут команды терминала Linux, которые принимают только литеральные аргументы.
Большинство команд получают входные данные, например, из stdin (канала) и файла:
wc < states.txt #ок
wc states.txt #ок
Однако, существуют определённые исключения. Например, некоторые команды получают входные данные только из stdin, а не из файла:
tr 'N' 'n’ states.txt #работать не будет
tr 'N' 'n’ < states.txt #работать будет
Некоторые команды не получают входные данные ни из stdin, ни из файла. Например, следующие:
echo < states.txt— не подходит. Предполагается, что вы собираетесь распечатать содержимое файла;echo states.txt— не подходит. Предполагается, что вы собираетесь распечатать содержимое файла;echo «Привет, как дела?»— принимает литеральные аргументы.
cp, touch, rm, chmod относятся к другим примерам.
Xargs: когда канала недостаточно
Некоторые команды не считываются из стандартного входа, канала или файла. Им, как правило, требуются аргументы. Кроме того, некоторые системы ограничивают количество аргументов в командной строке.
Например команда rm tmpdir/*.log завершится ошибкой, если файлов .log будет слишком много.
Итак, команда xargs решает сразу обе проблемы: преобразует стандартный поток ввода команды в литеральные аргументы и разбивает args на допустимое число, многократно запуская команду.
Например, можно попробовать создать файлы с именами в somelist.txt:
xargs touch < somelist.txt
Параллельность в GNU
В данном случае речь идёт о параллельном выполнении задач из командной строки. В некотором смысле похожее на xargs. Что по итогу это даёт?
- Позволяет обрабатывать параметры как независимые аргументы команды и выполнять параллельно команду.
- Осуществляет синхронизированный вывод — как если бы команды в Linux-терминале выполнялись последовательно.
- Обеспечивает настраиваемое количество параллельных заданий.
- Хорошо подходит для выполнения простых команд или скриптов на вычислительных узлах для использования многоядерной архитектуры.
Необходимо учитывать, что, возможно, потребуется специальная установка, так как по умолчанию это недоступно.
Примеры параллельного выполнения в GNU:
Для того, чтобы найти все html-файлы и переместить их в каталог:
find . -имя '*.html' | parallel mv {} web/
Для того, чтобы удалить файл pict0000.jpg и заменить его на pict9999.jpg (здесь подразумевается одновременное выполнение 16 параллельных заданий):
seq -w 0 9999 | parallel -j 16 rm pict{}.jpg
Создание миниатюр для всех файлов изображений (требуется программное обеспечение imagemagick):
ls *.jpg | parallel convert -geometry 120 {} thumb_{}
Загрузка из списка URL-адресов и отчёт о неудачных загрузках:
cat urlfile | parallel "wget {} 2>errors.txt"
Для дополнительной информации можно ознакомиться с книгой GNU parallel 2018.
Классические инструменты для программирования: find, grep, awk, sed
Особенности find
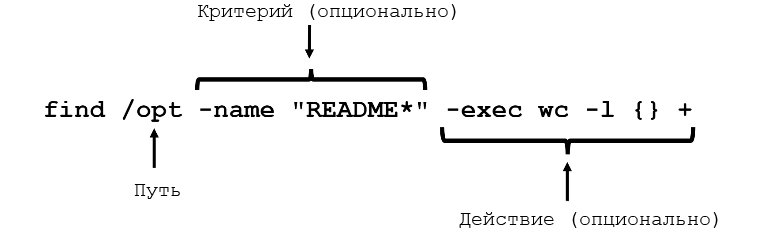
Путь: может иметь несколько вариантов, например .find /usr /opt -iname "*.so".
Критерии:
-name, -iname, -type (f, d, l), -inum <Н>;-user<uname>, -group<gname>, -perm (ugo+/-rwx);-size +x[c], -empty, -newer <fname>;-atime +x, -amin +x, -mmin -x, -mtime -x;- критерии могут быть объединены с логическими
и (- а)иили (-о).
Действие:
-print— действие по умолчанию — отображать;-ls— выполните командуls -lidsдля каждого результирующего файла;-exec cmd— выполнить команду;-ok cmd— используется какexec, за исключением того, что команда выполняется после подтверждения пользователем.
Примеры команд для поиска:
find . -type f -iname "*.txt"— xt-файлы вcurdir;find . -maxdepth 1— эквивалентls;find ./somedir -type f -size +512M -print— все файлы размером более 512M в./somedir;find /usr/bin ! -type l— не символьная ссылка в/usr/bin;find $HOME -type f -atime +365 -exec rm {} +— позволяет удалить все файлы, которые не были доступны в течение года;find . \( -name "*.c" -o -name "*.h" \)— все файлы, имеющие расширение .c или .h.
Grep: поиск шаблонов в тексте
Grep изначально представлял собой команду global regular expression print или «g/re/p» в текстовом редакторе ed. Данная функция оказалась настолько полезной, что была разработана отдельная утилита под названием grep.
Grep позволяет извлекать строки из текста, который соответствует определённому шаблону. Также можно находить строки с определённым рисунком в большом объёме текста. Сюда относится:
- поиск в списке процессов;
- выборочная проверка большого количества файлов на наличие паттерна;
- исключение некоторого фрагмента текста из большого текстового объёма.
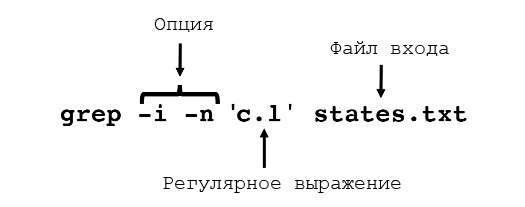
Полезные опции grep:
-i: игнорировать случай;-n: отображение номеров строк вместе со строками;-v: инвертированный вывод. Отберутся те строки, которые не совпадают с регулярным выражением;-c: печать конкретного количества совпадающих строк;-A<n>: включение n-строк после совпадения;-B<n>: включение n-строк перед совпадением;-o: печать только совпадающего выражения (а не всей строки);-E: позволяет использовать «расширенные» регулярные выражения.
Регулярные выражения в терминале Linux
Регулярные выражения (regex) — это язык описания шаблона строк.
Точка «.» является специальным символом, который будет соответствовать любому символу (кроме новой строки). Например, b.t будет соответствовать bat, bbt, b%t и так далее, но при этом сюда не подойдут bt, xbt.
Класс символов: один из элементов в квадратных скобках [ ] будет совпадать, при этом допускаются последовательности:
[Cc]at — соотносится с Cat и cat.[f-h]ate — соотносится с fate, gate, hate.
Символ «^» внутри класса символов означает отрицание, например:
b[^eo]at будет соответствовать brat, но не boat или beat.
Расширенные выражения запускаются с помощью egrep или grep -E, при этом:
«*» соответствует нулю или более, «+» соответствует одному или более, «?» соответствует нулю или разовому появлению предыдущего символа, например:
[hc]+at будет соответствовать hat, cat, hhat, chat, cchhat и т. д.
«|» является разделителем для нескольких шаблонов, а «(» и «)» позволяют группировать шаблоны, например:
([cC]at)|([dD]og) будет соответствовать cat, Cat, dog и Dog.
«{}» может использоваться для указания диапазона повторения, например:
ba{2,4}t будет соответствовать baat, baaat и baaaat, но не bat.
Примеры grep
Строки, которые заканчиваются двумя гласными:
grep '[aeiou][aeiou]$' prose.txt
Проверка 5 строк до и после строки, где встречается «little»:
grep -A5 -B5 'little' prose.txt
Комментируйте команды и выполняйте поиск последних использованных в истории:
some -hard 'to' \remember --complex=command #success
history | grep '#success'
Удостоверьтесь, что вы правильно написали все команды в терминале Linux и избежали возможных двусмысленностей:
grep -E '^ambig(uou|ou|ouo)s$' /usr/share/dict/linux.words
find + grep — ещё одна очень полезная комбинация вам на заметку.
find . -iname "*.py" -exec grep 'add[_-]item' {} +
awk: извлечение и использование данных
awk — это специальный программируемый фильтр, который считывает и обрабатывает входные данные строку за строкой. Он располагает широким спектром встроенных функций:
- явные поля (
$1 ... $NF) и управление записями; - функции (математические, построчная обработка и т. д.);
- синтаксический анализ и фильтрация регулярных выражений.
Этот фильтр также позволяет работать с переменными, циклы, условными обозначениями, массивами ассоциативных элементов, пользовательскими функциями.
Анатомия awk
В большинстве случае используется в качестве однострочной идиомы следующего вида:
awk ‘awk_prog’ file.txt
или:
command | awk ‘awk_prog’
Где awk_prog это:
BEGIN {действие}— выполнить определённое действие один раз перед чтением и обработкой входных данных;шаблон или условие {действие}— выполнить действие для каждой строки входных файлов и/илиstdin, которые удовлетворяют шаблону или условию;END {действие}— выполнить определённое действие один раз после прочтения и обработки входных данных.
В команде нужно указывать хотя бы один из вышеперечисленных разделов.
Шаблоны, условия и действия
Шаблон — это регулярное выражение, которое соответствует (или не соответствует) входной строке, например:
/New/— любая строка, содержащая New;/^[0-9]+ /— строка, начинающаяся с цифр;/(POST|PUT|DELETE)/— строка, которая содержит определённые слова;
Условие — это булевое выражение, которое выбирает входные строки, например:
$3>1 — строки, для которых третье поле больше, чем 1
Действие — это последовательность операций, например:
{print $1, $NF}— печать первого и последнего поля/столбца;{print log($2)}— получить журнал второго поля/столбца;{for (i=1;i<x;i++){sum += $3}}— получить суммарное значение.
При этом пользовательские функции могут быть определены и указаны в любом блоке действий.
Полезные однострочные awk-команды терминала Linux
awk '{print $1}' states.txt;awk '/New/{print $1}' states.txt;awk NF > 0 prose.txt— печать строк, содержащих хотя бы одно поле (пропустить пустые строки);awk '{print NF, $0}' states.txt— поля в каждой строке и в самой строке;awk '{длина печати($0)}' states.txt— символы в каждой строке;awk 'BEGIN{print substr("New York",5)}' #York;
sed: синтаксический анализ и преобразование текста
sed — это специальный потоковый редактор, который ищет шаблон в тексте и применяет к нему необходимые изменения.
Данный редактор может быть в том числе пакетным или неинтерактивным редактором. Его функции заключаются в том, что он считывает из файла или из stdin (при наличии каналов) по одной строке за раз. При этом исходный входной файл остается неизменным (так как sed также является фильтром), после чего результаты преобразуются в стандартные выходные данные.

Опции sed:
- адрес — может быть номером строки, диапазоном или совпадением. Может быть оставлен по умолчанию, либо являться файлом целиком;
- команда —
s:substitute (замена),p:print (печать),d:delete (удалить),a:append (добавить),i:insert (вставить),q:quit (завершить); - regex — регулярные выражения;
- знак-разграничитель — в данном случае необязательно использовать «
/», можно также применять «|» или «:» или любой другой символ; - модификатор — его роль может выполнять число
n, которое применяет команду к N-му вхождению,gприменяет ко всей строке в целом; - общие признаки состояния sed —
-n(без печати),-e(несколько операций),-f(чтение sed из файла),-i(на месте редактирования).
Полезные примеры sed:
sed -n '5,9 p' states.txt— печать строк с 5 по 9;sed '20,30 s|New|Old|1' states.txt— влияет на 1-е вхождение в стр. 20–30;sed -n '$p' states.txt— печать последней строки;sed '1,3 d' states.txt— удалить первые 3 строки;sed '/^$/d' states.txt— удалить все пустые строки;sed '/York/!s/New/Old/' states.txt— заменить всё, кроме York;kubectl -n kube-system get configmap/kube-dns -o yaml | sed 's/8.8.8.8/1.1.1.1/' | kubectl replace -f -.
В следующей части разберём основные инструменты терминала Linux.

37К открытий39К показов

Авито проводит стажировку для аналитиков: присоединиться к ней могут студенты старших курсов и выпускники. Это возможность сделать первые шаги в карьере, получить опыт работы в крупной IT-компании и поработать с лучшими профессионалами на рынке. Рассказываем, какие этапы отбора надо пройти, чтобы попасть на программу, — а бонусом делимся советами от бывших стажёров и экспертов, которые общаются с потенциальными кандидатами.

Какой российский Linux выбрать. Показываем сравнение Astra, Alt, Aurora. Рассматриваем преимущества и основные нюансы ✔ Tproger

Гайд по C++ для новичков и продвинутых программистов. Рассказываем о теории и делимся практическими советами. Tproger

Линус Торвальдс назвал нечувствительность к регистру худшим решением для файловых систем и раскритиковал попытки поддерживать case folding