


Знакомство с Kaggle: изучаем науку о данных на практике

Теорию лучше совмещать с практикой. Если вы изучаете Data Science, то вам стоит попробовать себя в соревнованиях Kaggle.
43К открытий45К показов

Рассказывает Уильям Коерсен, эксперт по аналитическим данным
Можно найти множество обучающих ресурсов по анализу данных — от Datacamp до Udacity, все они позволяют изучить науку о данных. Но если вы из тех, кто любит учиться через практику, то Kaggle, возможно, окажется лучшей платформой, чтобы улучшить ваши навыки с помощью практических проектов в области научных исследований.
Смотрите также: Как команда студентов победила в хакатоне и выиграла 500 000 руб. — интервью с участником
Сначала Kaggle, который позиционирует себя как «ваш дом для науки о данных», был местом для соревнований по машинному обучению, но сейчас там можно найти и ресурсы по науке о данных. Стоит упомянуть несколько главных особенностей Kaggle:
- Datasets (наборы данных): множество наборов данных различных типов и размеров, которые можно бесплатно загрузить. Здесь можно найти интересные данные для изучения или тестирования своих навыков моделирования.
- Machine Learning Competitions (соревнования по машинному обучению): когда-то были сердцем Kaggle, такие тесты на моделирование — лучший способ изучить новые виды машинного обучения и отточить ваши способности с помощью интересных проблем, основанных на реальных данных.
- Learn (изучение): серия обучающих материалов по изучению данных, охватывающих SQL и глубокое обучение (Deep Learning), которые подаются в Jupyter Notebooks.
- Discussion (обсуждения): место, где можно задать свои вопросы и получить советы от тысяч экспертов по аналитическим данным (data scientist) в сообществе Kaggle.
- Kernels (ядра): онлайн-среда для программирования, которая работает на серверах Kaggle. В ней можно писать Python/R-скрипты и работать в Jupyter Notebooks. Такие ядра абсолютно бесплатны (можно даже добавить GPU) и идеальны для тестирования: не нужно настраивать среду у себя на компьютере. Их можно использовать для анализа любого набора данных, соревнований по машинному обучению или выполнения заданий из раздела «Обучение». Можно скопировать или изменить уже существующее ядро другого пользователя, а также поделиться своим, чтобы его смогли оценить остальные.

Главные аспекты Kaggle
В целом Kaggle — отличное место для обучения: либо через более традиционные учебные задания, либо через соревнования со страницы Competitions. Чтобы узнать о новейшем методе машинного обучения, можно прочитать книгу или посмотреть на Kaggle, как люди используют этот метод на практике. Второе мне кажется гораздо более приятным и эффективным. Более того, сообщество чрезвычайно общительное и всегда готово ответить на вопросы или дать обратную связь по проекту.
В этой статье мы разберёмся, как начать работу с конкурсом машинного обучения в Kaggle: Home Credit Default Risk problem. Это довольно простое соревнование с набором данных разумного размера (а так бывает не всегда), что означает, что мы сможем полностью выполнить задание на ядре от Kaggle. Это значительно снижает барьер для входа, потому что вам не нужно беспокоиться о каком-либо программном обеспечении на вашем компьютере и загружать данные. Если у вас есть учётная запись Kaggle и доступ к интернету, вы сможете подключиться к ядру и запустить код.
Я планирую провести весь конкурс на Kaggle, и ядро (Python Jupyter Notebook) для этой статьи можно посмотреть здесь. Чтобы получить от этой статьи максимум, скопируйте ядро, создав учётную запись Kaggle, а затем нажмите голубую кнопку с надписью «Fork Notebook». Это откроет место для редактирования и работы в среде ядра.
Описание соревнования
Home Credit Default Risk competition — это стандартная контролируемая задача машинного обучения, которая с помощью данных по кредитной истории прогнозирует, погасит ли заёмщик кредит. Во время обучения мы предоставляем нашу модель со свойствами — переменными, описывающими заявку на получение кредита, и ярлыком — 0, если кредит был погашен, и 1, если кредит не был погашен — и модель учится сопоставлять свойства и ярлыки. Затем во время тестирования мы подаём в модель свойства новой серии заявлений на кредит и просим её предсказать ярлык.
Home Credit, являющийся организатором соревнования, — это финансовый провайдер, который специализируется на финансовых услугах. Для финансового бизнеса предсказать, погасит ли заёмщик кредит, жизненно важно. Home Credit запустил этот конкурс в надежде, что сообщество Kaggle разработает эффективный алгоритм для решения этой задачи. Этот конкурс следует общей идее большинства соревнований в Kaggle: у компании есть данные и проблема, которую необходимо решить, и вместо того, чтобы нанять в штат экспертов по аналитическим данным для создания модели, они предлагают относительно скромный приз, чтобы подвигнуть на решение проблемы весь мир. Сообщество, состоящее из тысяч квалифицированных экспертов по аналитическим данным (Kagglers), работает над проблемой практически бесплатно, чтобы найти наилучшее решение.
Среда Kaggle для соревнований
На картинке ниже можно увидеть, что находится на домашней странице соревнований.

Краткое описание вкладок:
- Overview: краткое описание проблемы, метрики, оценки, призы и временная шкала.
- Data: все данные, необходимые для участия в конкурсе, другие данные не допускаются. Можно загрузить всю информацию к себе на компьютер, но мы этого делать не будем, так как будем использовать ядро Kaggle, к которому можно просто подключить данные.
- Kernels: предыдущие работы, сделанные вами или другими участниками. Для соревнования это наиболее важный ресурс. Вы можете изучить другие скрипты и notebooks, а потом скопировать (называется «Forking»), чтобы изменить их и запустить.
- Discussion: ещё одна полезная вкладка, где можно найти обсуждения, в которых участвуют как организаторы соревнования, так и участники. Здесь можно задать уточняющие вопросы или почерпнуть новую информацию из ответов другим участникам.
- Leaderboard: можно посмотреть, кто в топе, и ваш рейтинг.
- Rules: правила — не очень интересно, но их стоит знать.
- Team: здесь можно управлять членами команды, если вы решите создать свою.
- My Submissions: можно посмотреть ваши предыдущие материалы и выбрать финальный вариант, который будет участвовать в соревновании.
Почему важно учиться у других?
Соревнования Kaggle по машинному обучению, хоть они и называются так, стоит называть скорее «совместными проектами», потому что главной целью является не столько выиграть, сколько попрактиковаться и поучиться у друга-эксперта. Как только вы осознаете, что здесь главное — не превзойти других, а улучшить свои навыки, вы получите от соревнований максимальную пользу. Когда вы регистрируетесь на Kaggle, вы получаете не только доступ ко всем ресурсам, но и возможность стать частью сообщества экспертов по аналитическим данным.
Воспользуйтесь преимуществом их опыта и постарайтесь быть активным участником сообщества! Можно как поделиться своими наработками ядра, так и задать вопрос в ветке обсуждений. Конечно, перспектива выложить свою работу в общий доступ пугает, но это позволит получить отзыв на свою работу и исправить существующие ошибки, а также не совершать их в будущем. Все начинают, как новички, а сообщество экспертов по аналитическим данным очень поддерживает своих на всех уровнях подготовки.
Создание новых обсуждений и использование чужого ядра не только не возбраняется, но и поощряется! В школе это посчитали бы жульничеством, а в реальном мире это чрезвычайно важный навык командной работы.
Лучший способ участия в соревновании — найти чужое ядро с хорошим результатом в таблице лидеров, скопировать его и попытаться улучшить результат. Потом поделиться своим ядром с сообществом, чтобы другие могли использовать его. Экспертное сообщество по аналитическим данным стоит не на плечах атлантов, а на спинах тысяч людей, которые поделились своей работой с другими (извините за философствование, но именно по этим причинам я так люблю науку о данных!).
Работа в первом Notebook
Теперь, когда вы получили базовое представление о том, как работает Kaggle, и вдохновились тем, сколько преимуществ можно получить от соревнований, настало время начать. Здесь я кратко рассказываю о Python Jupyter Notebook, который я собрал для Home Credit Default Risk problem. Но чтобы получить представление, лучше всего будет скопировать его и запустить самостоятельно (вам не придётся что-то скачивать или настраивать, так что очень рекомендую это сделать).
Когда вы откроете notebook в ядре, вы увидите следующее:

Окружения ядра для Notebook
Перед вами стандартный Jupyter Notebook с немного отличающимся внешним видом. Вы можете писать код на Python или обычный текст (используя синтаксис Markdown) точно так же, как и в Jupyter, а потом запускать код на облачном сервере Kaggle. Однако ядра Kaggle имеют некоторые отличительные особенности, недоступные в Jupyter Notebook. Нажмите стрелку влево в правом верхнем углу, которая откроет три вкладки (если вы в режиме полноэкранного просмотра, эти вкладки уже могут быть открыты).

Во вкладке Data отображаются наборы данных, к которым наше ядро подключено. В этом случае у нас все данные с соревнования, но мы также можем подключить другие данные с Kaggle или загрузить свои. Файлы с данными лежат в директории ../input/.
Код для доступа к ним:

Вкладка Settings позволяет нам контролировать различные технические аспекты ядра. Мы можем добавить GPU, изменить видимость или установить пакет Python, которого ещё нет в окружении.
Последняя вкладка Versions позволяет посмотреть предыдущие коммиты. Мы можем смотреть изменения в коде, просматривать лог-файлы запуска, видеть notebook, сгенерированный при запуске, и загружать выходные данные прогона.

Чтобы запустить весь notebook и записать новую версию, нужно нажать голубую кнопку Commit & Run в правом верхнем углу ядра. Это действие выполнит весь код и сохранит любые файлы, которые будут созданы во время запуска. Закоммитив notebook, мы сможем получить доступ к любым прогнозам, сделанным нашей моделью, и подать их на оценивание.
Вводный Notebook Outline
Первый notebook предназначен для ознакомления с проблемой. Нужно начинать с основ: убедиться, что понятны используемые данные и задание. Для этой проблемы есть один главный тренировочный набор данных с уже расставленными метками и 6 дополнительных файлов. В первом notebook мы используем только главный файл, который принесёт достойный результат, но дальнейшая работа подразумевает, что мы будем использовать все файлы с данными, чтобы быть конкурентоспособными.
Чтобы понять данные, стоит оторваться от клавиатуры и почитать документацию, например описание колонок каждого файла. Так как используется несколько файлов, нужно понять, как они связаны между собой, хотя для первого notebook мы будем использовать один файл, чтобы упростить работу. Чтение других ядер также поможет нам ознакомиться с данными и понять, какие переменные важны.
Как только мы разобрались с данными и проблемой, мы можем начать структурировать задачи машинного обучения. Это подразумевает работу с категориальными переменными (через one-hot encoding), заполнение пропущенных значений (imputation) и масштабирование переменных в диапазоне. Мы можем проводить анализ исследовательских данных, например поиск закономерности с ярлыком, и отрисовывать такие закономерности.

Позже мы сможем использовать эти закономерности для моделирования решений, например, какие переменные использовать (смотрите notebook для реализации).
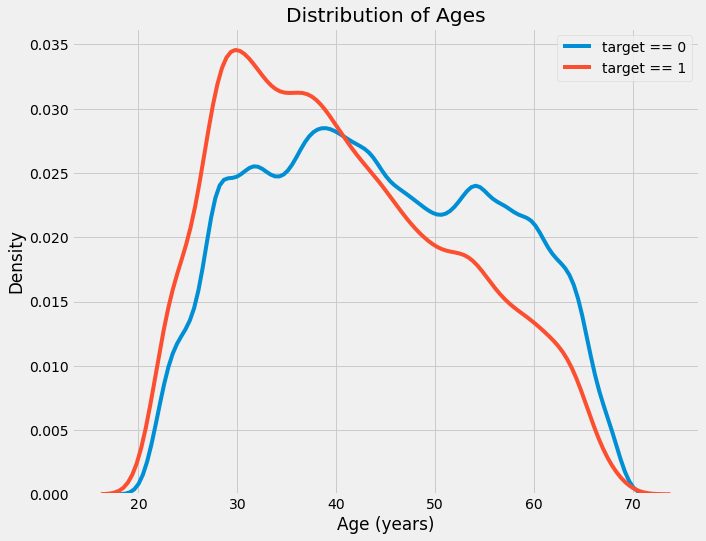

Разумеется никакой анализ исследовательских данных не будет полным без моего любимого Pairs Plot.
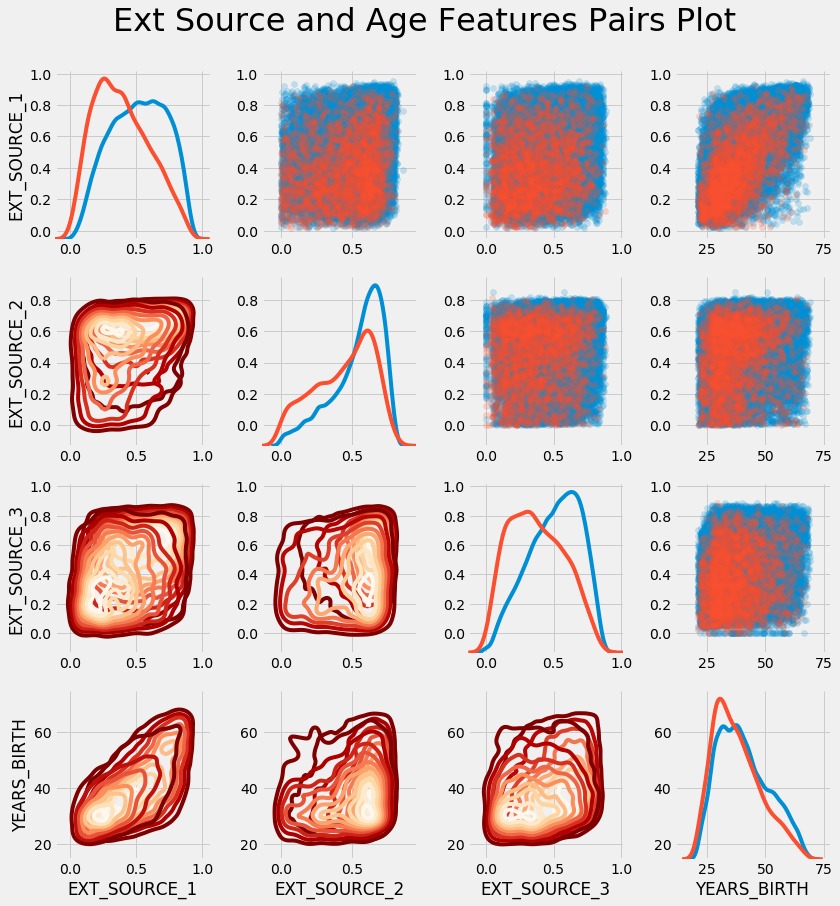
После тщательного изучения данных и обеспечения приемлемости для машинного обучения, мы переходим к созданию базовых моделей. Однако, прежде чем мы полностью перейдём к этапу моделирования, важно понять показатель производительности для соревнований. В соревновании Kaggle всё сводится к одному числу — метрике по тестовым данным.
Хотя интуитивно кажется, что нужно использовать точность для задачи бинарной классификации, это будет плохим решением, потому что мы имеем дело с проблемой несбалансированного класса. Вместо точности, решения оцениваются с помощью ROC AUC (Receiver Operating Characteristic curve Area Under the Curve). Я позволю вам самостоятельно разобраться в этом или почитать объяснение в notebook. Просто знайте, что чем выше результат, тем лучше. Чтобы вести подсчёты с помощью ROC AUC, нам нужно делать прогнозы в терминах вероятностей, а не бинарные — 0 или 1. ROC показывает истинную положительную оценку по сравнению с ложно положительной оценкой, как функцию порога, согласно которому мы классифицируем экземпляр как положительный.
Обычно нам нравится делать наивное базовое предсказание, но в этом случае мы уже знаем, что случайные догадки по задаче будут равны 0,5 по ROC AUC. Поэтому для нашей модели мы будем использовать несколько более сложный метод — логистическую регрессию. Это популярный простой алгоритм для задач бинарной классификации, который поможет установить низкий порог для прохождения будущими моделями.
После применения логистической регрессии, мы можем сохранить результат в csv-файл для отправки. Когда notebook закоммичен, любые выходные файлы появятся на вкладке Output в Versions.
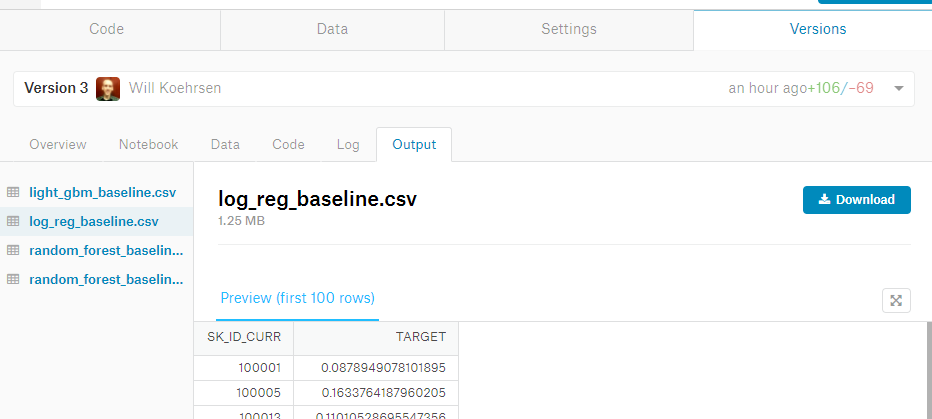
С этой вкладки мы можем загрузить получившиеся файлы на компьютер, а потом выгрузить их для участия в соревновании. В этом notebook мы сделали четыре разные модели. Их оценки не приближают нас к вершине таблицы лидеров, но оставляют место для множества улучшений в будущем! Также мы получили представление о производительности, которую мы можем ожидать, используя всего лишь один источник с данными.
Неудивительно, что экстраординарный Gradient Boosting Machine (использовалась библиотека LightGBM) отработал лучше всего. Эта модель побеждает практически в каждом структурированном Kaggle соревновании (где данные представлены в табличном формате) и нам, вероятно, придётся использовать какую-то форму этой модели, если мы хотим достойно конкурировать с другими участниками.
Вывод
В этой статье я хотел рассказать, как начать участвовать в соревнованиях Kaggle. Цели победить я не ставил, скорее хотелось показать вам, как подойти к соревнованию по машинному обучению, и продемонстрировать несколько решений.
Более того, я показал свой взгляд на соревнования по машинному обучению, который заключается в том, что нужно участвовать в обсуждении, работать с чужим кодом и делиться своей работой. Это увлекательно — улучшать свои предыдущие результаты, но я считаю более важным изучение новых способов машинного обучения. И хоть соревнования Kaggle и называются так, это больше похоже на совместные проекты, в которых может участвовать и оттачивать свои навыки каждый участник.
Остаётся много работы, но, к счастью, нам больше не нужно делать её в одиночку. Я надеюсь, эта статья и notebook kernel придали вам уверенности, чтобы начать участвовать в соревнованиях Kaggle или заняться любым научным проектом.

43К открытий45К показов

Cобрали опыт зарплат айтишников из пяти стран и узнали, как вписаться в местную культуру и где комфортнее жить.

Big Data в 2025. Показываем основные технологии работы с большими данными. Рассматриваем пошаговую инструкцию ✔ Tproger

Что такое генеративные модели. Показываем, как нейросети создают изображения, музыку и код. Рассматриваем основные нюансы ✔ Tproger

Лучшие курсы для аналитика данных: рейтинг актуальных обучающих программ. Подборка онлайн-обучения профессии Data Analyst с нуля и для специалистов с опытом