


Учимся правильно оформлять код на C на примере open source проектов

28К открытий29К показов
В каждом проекте есть свои соглашения по написанию и оформлению кода. Некоторые менеджеры ограничиваются только базовыми правилами, некоторые составляют подробные списки рекомендаций. В некоторых проектах правил оформления кода нет совсем, и каждый разработчик следует своему стилю.
Если исходники большого проекта написаны в одном стиле, их гораздо легче понимать.
Научиться правильному оформлению кода можно, например:
- из книг и журналов;
- из руководств в сети;
- из общения с коллегами;
- на собственном опыте.
Другой, не менее интересный, подход — взять проверенный временем открытый проект и разобраться в том, какие решения принимали его разработчики. Хорошим примером в этом случае будет ядро Linux.
Для новичка или даже для опытного разработчика, разбор кода ядра Linux может оказаться непростой задачей. Однако наша цель не присоединиться к ним, а просто рассмотреть детали реализации.
Давайте посмотрим на пример реализации функции из исходного кода Linux:
Код выглядит чистым и понятным:
- Он короткий, всего несколько строк.
- Подробная сигнатура функции.
- Код хорошо документирован.
- Код правильно и последовательно структурирован.
- Понятные имена переменных.
Тот же код, написанный другим разработчиком, может выглядеть так:
Стиль написания кода очень сильно влияет на его читаемость. Поэтому время, потраченное на тренировку и периодические код-ревью, всегда окупится.
Давайте теперь посмотрим на код ядра Linux с помощью CppDepend и попробуем разобраться, какими правилами руководствовались разработчики.
Модульность
Модульность — это техника дизайна приложений, которая обеспечивает повторное использование кода и облегчает его поддержку.
Для процедурного языка, такого, как C, в котором нет пространств имен, классов или компонентов, мы можем разделять модули, помещая код в отдельные файлы и директории.
Мы можем использовать два подхода:
- Положить все исходники в одну директорию
- Объединить файлы, относящиеся к одному модулю в одну директорию.
В случае с ядром Linux директории и поддиректории используются для обеспечения модульности кода ядра.
Инкапсуляция
Инкапсуляция — это скрытие внутренних деталей реализации. В C инкапсуляция обеспечивается за счет ключевого слова static. Функции и переменные, помеченные как статические, позволяют обращаться к ним только из того же файла.
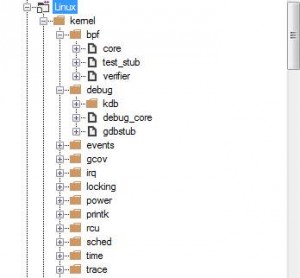
Давайте посмотрим на статические функции с помощью следующего запроса в CQLinq:
Мы можем использовать панель Метрик (Metric view) чтобы оценить код в целом. На этой панели код представлен в виде дерева (Treemap). Древовидная структура, используемая в CppDepend показывает иерархию кода:
- Директории в проекте.
- Файлы в директориях.
- Структуры, функции и переменные в файлах.
Дерево проекта позволяет наглядно представить результаты запроса CQLinq.

Видно, что множество функций — статические.
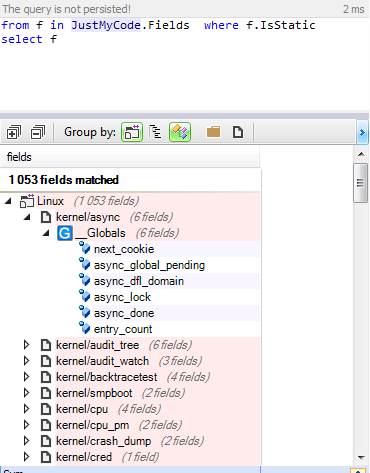
Теперь давайте найдем статические поля:
Используйте структуры для своих данных
В C функции используют переменные для работы. Переменные могут быть:
- статическими;
- глобальными;
- локальными;
- полями структур.
В каждом проекте есть модель данных, которая используется в различных модулях. Использование глобальных переменных для представления этой модели — это возможное решение, но плохое. Используйте структуры для группировки данных.
Давайте найдем все глобальные переменные с примитивным типом:

Функции должны быть краткими и понятными
Вот совет из linux coding style по поводу длины функции:
Функции должны быть короткими и понятными, делать только одну вещь. Они должны занимать один или, максимум, два экрана текста (экран по ISO/ANSI имеет размер 80×24). Функция должна делать одну вещь, и делать ее хорошо.Максимальная длина функции обратно пропорциональна ее сложности и количеству уровней вложенности. Так, если у вас, например, простая функция с одним, но большим case-выражением, она может быть длинной.
Давайте найдем все функции, длина которых больше 30 строк:
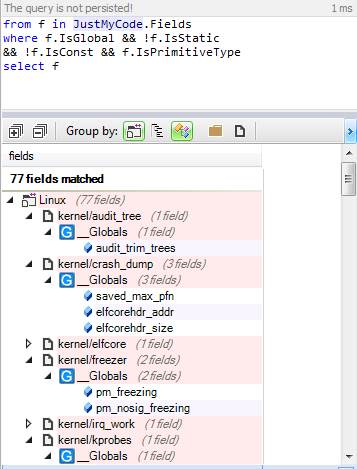
Всего немного методов занимает больше 30 строк.
Количество параметров функции
Функции с количеством параметров большим, чем 8 (NbParameters > 8), трудно вызывать. Также, их вызов плохо сказывается на производительности. Вместо этого мы можем передавать в них структуру с необходимыми значениями.
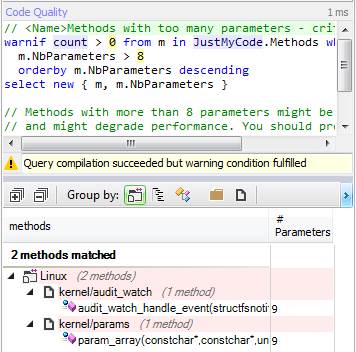
Только два метода принимают больше, чем 8 параметров.
Количество локальных переменных
Методы, в которых используются более 8 локальных переменных (значение NbVariables) тяжело понимать и поддерживать. Методы, в которых 15 и более локальных переменных очень сложны и их следует разбивать на более мелкие (кроме тех случаев, когда код сгенерирован сторонним инструментом).

Только в пяти функциях используется более 15 локальных переменных.
Избегайте сложных функций
Существует много метрик для определения сложности функции. Количество строк кода, локальных переменных и параметров — только некоторые из них.
Есть несколько более комплексных метрик:
- Cyclomatic complexity — популярная метрика, показывающая количество ветвлений в коде.
- Nesting Depth — is a metric defined on methods that is relative to the maximum depth of the more nested scope in a method body.
- Max Nested loop — максимальный уровень вложенности в методе.
Максимально допустимые значения этих метрик устанавливаются руководителем, здесь нет стандартных значений.
Давайте посмотрим на функции, которые можно упростить:
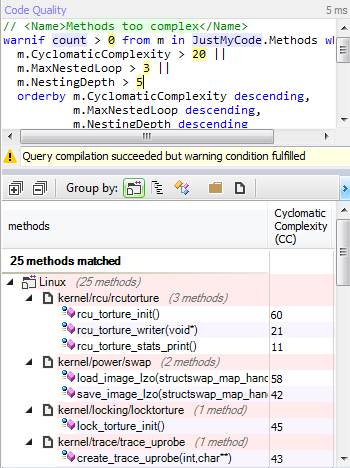
Только небольшое количество функций можно признать сложными.
Соглашения об именовании
Не существует единого стандарта именования элементов программы, поэтому каждый менеджер проекта может устанавливать свои правила, однако важно, чтобы эти правила были последовательны.
К примеру, в коде ядра Linux имена структур должны начинаться со строчной буквы. Мы можем проверить соответствие кода соглашению с помощью такого запроса:
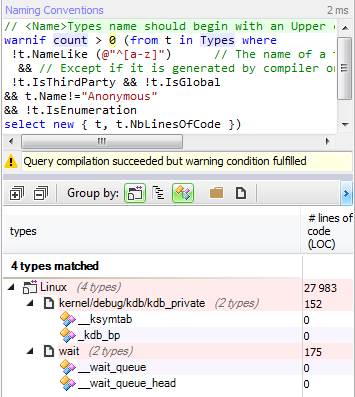
Имена только 4 структур начинаются с «_» вместо строчной буквы.
Отступы и выравнивание
Отступы очень важны для того, чтобы код был читаем. Вот что пишут об этом на странице linux coding style:
Обоснование: Основная идея отступов состоит в том, чтобы показать где начинается и заканчивается логический блок кода. Когда вы смотрите на один и тот же код в течение 20 часов, трудно не заметить пользу отступов.Некоторые могут возразить, что отступ в 8 пробелов делает код слишком широким, особенно на 80-знаковой строке терминала. Ответ: Если вам понадобилось более трех уровней отступа, вы что-то делаете неправильно и вам следует переписать этот участок.
Заключение
Чтение кода open-source проектов всегда идет на пользу вашему опыту. При этом нет необходимости скачивать и собирать проект, достаточно просто просматривать код, например, на GitHub.
Перевод статьи “Learn basic “C” coding rules from open source projects”

28К открытий29К показов

Сооснователь OpenAI Андрей Карпати выложил NanoChat — open-source клон ChatGPT, который можно обучить и запустить всего за $100

Доступ к open source моделям с лёгким развёртыванием без лишнего кода. Приятные тарифы, SLA, круглосуточная поддержка и возможность масштабировать нагрузку.

История перехода из медтеха в Python-разработку: как менторство помогло преодолеть сотни отказов и найти первую работу в IT. Советы по резюме, собеседованиям и выбору оффера от опытного наставника.

Сборник самых раздражающих ошибок в работе с базами данных — с примерами и советами, как делать правильно. По выпуску подкаста «Техно.Логично».