


Кризис машинного обучения в научных исследованиях: обладает ли научной ценностью эксперимент, результаты которого не удалось воспроизвести?

Может ли машинное обучение дать ответ на все вопросы исследователей? Может, но стоит ли доверять этим ответам? Разбираемся в статье.
7К открытий7К показов
Дисклеймер Статья выражает личное мнение автора, основанное на приведённых в ссылках материалах. Это спорная область и конструктивное обсуждение приветствуется.
В настоящее время в научных кругах назревает понимание кризиса воспроизводимости. Могу поспорить, что основным его источником является применение в научных целях техник машинного обучения.
Машинное обучение всё больше вытесняет традиционно применяемые в научных исследованиях методы статистического анализа. Каковы будут последствия такого замещения для научного сообщества и процесса познания? Некоторые считают, что присущий машинному обучению «подход чёрной коробки» привёл к кризису воспроизводимости научных исследований. В конце концов, может ли эксперимент быть признан научным, если другие исследователи не могут получить тот же результат?
Прим. перев. Автор статьи использует слово «подход», однако стоит отметить, что «чёрная коробка» — скорее побочный эффект. Никто не пытается намеренно скрыть алгоритмы машинного обучения, они прозрачны и поддаются анализу. Проблема состоит в том, что исследователи, применяющие МО в своих исследованиях, далеко не всегда хорошо знакомы с линейной алгеброй — основой алгоритмов. Вектор (для регрессии) или массив (для нейросетей) весов открыт для изучения, проблема состоит только в том, чтобы найти нужные данные среди множества других. Поэтому переводчик склонен был бы назвать подход «чёрной коробки» «эффектом Уолдо».
Машинное обучение (МО) нашло применение в исследованиях всех областей науки и во многом заменило традиционную статистику. И хотя для анализа данных зачастую проще использовать именно МО, присущий этой технологии «подход чёрной коробки» вызывает серьёзные проблемы при интерпретации результатов.
Термин «кризис воспроизводимости» означает, что тревожно большое количество результатов научных экспериментов не нашли своего подтверждения при проведении тех же манипуляций другими группами учёных. Это может означать, что результаты, полученные в ходе изначальных работ, ошибочны. Согласно данным одного анализа, до 85 % всех проведённых в мире исследовательских работ в области биомедицины не привели к значимым результатам.
Адепты статистики и машинного обучения в научных кругах ведут нескончаемый горячий спор относительно кризиса воспроизводимости.
Один из исследователей ИИ, Али Рахими, назвал технологии машинного обучения разновидностью алхимии. Полный текст заявления можно прочитать в соответствующей статье его блога.
Машинное обучение отлично вписывается в научный процесс, что делает практически неизбежным использование этой технологии в исследовательской работе. МО можно рассматривать в качестве инженерной задачи — как сборочный конвейер с моделированием, настройкой параметров, подготовкой данных и оптимизацией компонентов. Цель машинного обучения — поиск оптимальных ответов или прогнозов, что в свою очередь входит в одну из задач исследовательского процесса.
Типы и алгоритмы МО и сами могут стать предметом исследования. В научных источниках можно найти множество статей и материалов на тему методов машинного обучения, как раньше можно было найти работы по статистическим методам.
В феврале 2019 Дженевьера Аллен сделала тревожное заявление для Американской ассоциации содействия развитию науки: учёные, полагающиеся на машинное обучение, обнаруживают определённую систематику в данных, даже если алгоритм просто зацикливается на информационном шуме, который в ходе повторного эксперимента, как правило, не повторяется.
Указанная проблема характерна для множества научных дисциплин, поскольку машинное обучение применяется в различных областях исследования, таких как астрономия, геномика, энвайроментология, здравоохранение.
В качестве яркого примера она ссылается на исследования в области геномики, в которых обычно обрабатываются датасеты размером в сотни гигабайт и даже несколько терабайт. Аллен утверждает, что когда учёные используют плохо изученные алгоритмы машинного обучения для кластеризации профилей генома, это зачастую ведёт к получению правдоподобно выглядящих, но невоспроизводимых результатов.
При этом другая группа исследователей, используя те же методы анализа, может получить значительно отличающиеся результаты, таким образом оспаривая и дискредитируя первоначальный эксперимент. Это может происходить по нескольким причинам:
- недостаточное понимание алгоритма МО;
- недостаточное знакомство с исходными данными;
- неверная интерпретация результатов.
Недостаточное понимание алгоритма МО
Недостаточное понимание алгоритма — очень распространённая проблема в машинном обучении. Если вы не знаете, как алгоритм выводит результат, как вы можете быть уверены, что он не «жульничает», выводя несуществующие корреляции между переменными?
Это серьёзная проблема при работе с нейросетями ввиду множества параметров (зачастую для глубоких нейросетей количество параметров может составлять миллионы). Помимо этих параметров надо принимать в расчёт и гиперпараметры — такие как скорость обучения, метод инициализации, количество итераций, архитектура нейросети.
Для решения проблемы мало осознать, что исследователь недостаточно хорошо понимает работу алгоритма. Как можно сравнить результаты, если в разных работах применялись отличающиеся по структуре нейронные сети? Многослойная нейронная сеть имеет очень сложную динамическую структуру. Поэтому даже добавление единственной переменной или смена одного гиперпараметра может значительно повлиять на результаты.
Недостаточное знакомство с исходными данными
Плохое понимание исходных данных также является серьёзной проблемой, но эта проблема существовала и во время работы с традиционными статистическими методами. Ошибки в сборе данных — такие как ошибки квантования, неточности считывания и использование замещающих переменных — самые распространённые затруднения.
Субоптимальные данные всегда будут проблемой, но понимать, какой алгоритм применить к какому типу данных — невероятно важно, это значительно повлияет на результат. Это можно продемонстрировать на примере простой регрессии.
При использовании линейной регрессии с бОльшим количеством параметров, чем точек данных (очень частая ситуация в геномике, поскольку имеется очень большое количество генов и довольно мало точек данных), выбор оптимизации параметров серьёзно повлияет на то, какие параметры будут определены в качестве «важных».
При использовании регрессии LASSO это приведёт к приближению переменных, определённых в качестве незначительных, к нулю. Тем самым будет проведён отбор переменных с исключением избыточных.
Гребневая регрессия сжимает названные параметры до пренебрегаемо малых величин, но не исключает их из набора.
При использовании эластичной сети (комбинации LASSO и гребневой регрессии), мы снова получим совсем другие результаты.
Если мы не будем использовать регрессию, алгоритм очевидно будет страдать от переобучения, поскольку у нас будет больше переменных, чем точек данных, и алгоритм просто заполнит все точки данных.
Конечно, для линейной регрессии можно выполнить статистические тесты, которые помогут установить точность в виде доверительных интервалов, p-тесты и тому подобное. Однако такая роскошь не доступна для нейронных сетей, поэтому можем ли мы быть уверены в выводах? Лучшее, что мы можем сделать — точно определить архитектуру и гиперпараметры модели и предоставить открытый исходный код, чтобы другие исследователи могли проанализировать модель и использовать её самостоятельно.
Неверная интерпретация результатов
Ошибочная оценка результатов может быть весьма распространена в научном мире. Одна из причин — видимая корреляция не всегда отражает реальную взаимосвязь. Есть несколько причин, почему переменные А и B могут коррелировать:
- A может изменяться при изменении B;
- B может изменяться при изменении A;
- A и B могут изменяться при изменении общей базовой переменной, C;
- корреляция A и B может быть ложной.
Продемонстрировать корреляцию двух значений легко, гораздо сложнее определить её причину. Погуглив «spurious correlations» (ложная корреляция), вы найдёте весьма интересные и забавные примеры, имеющие статистическое значение:
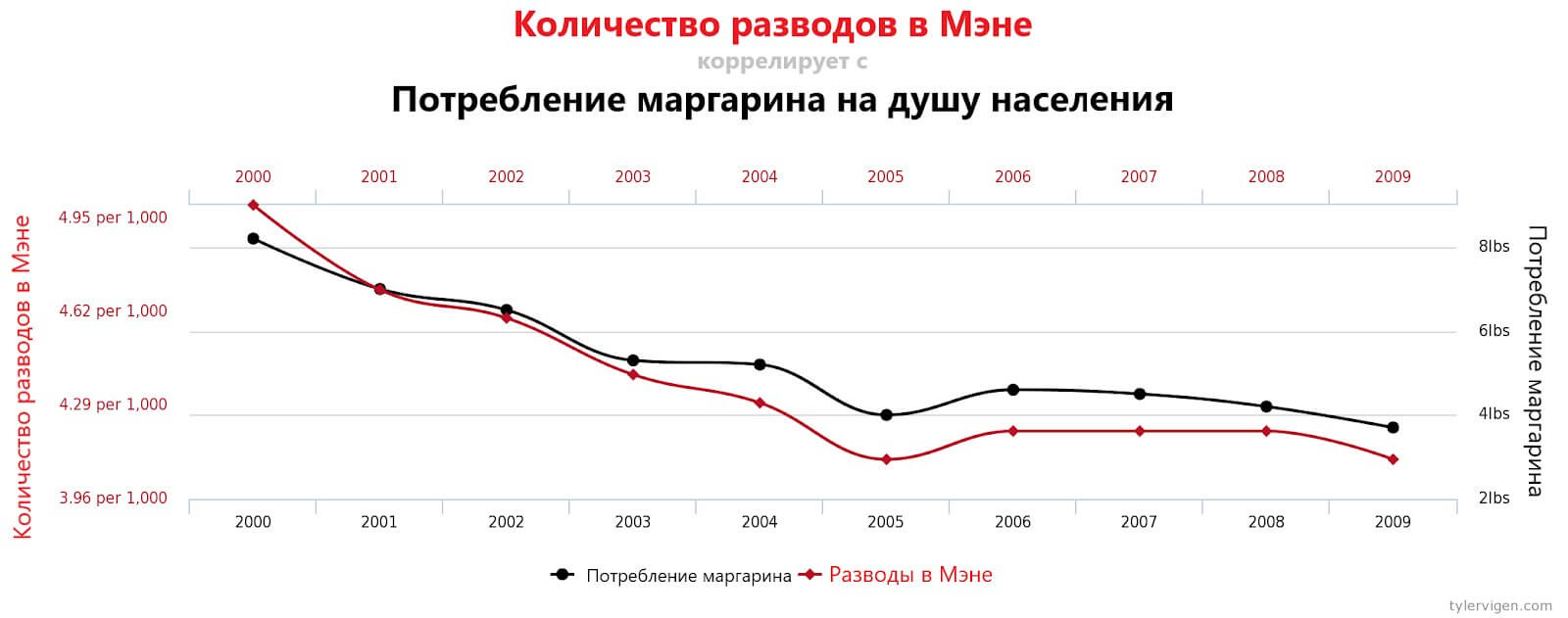
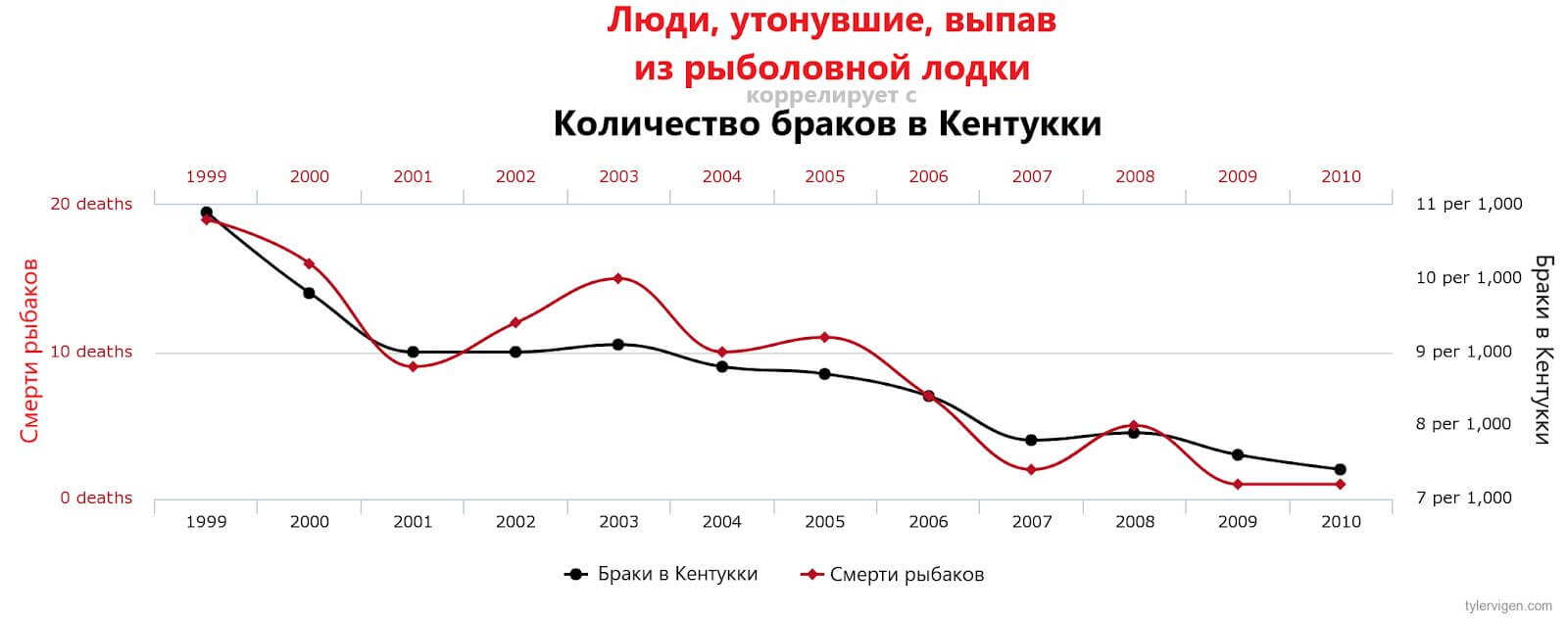
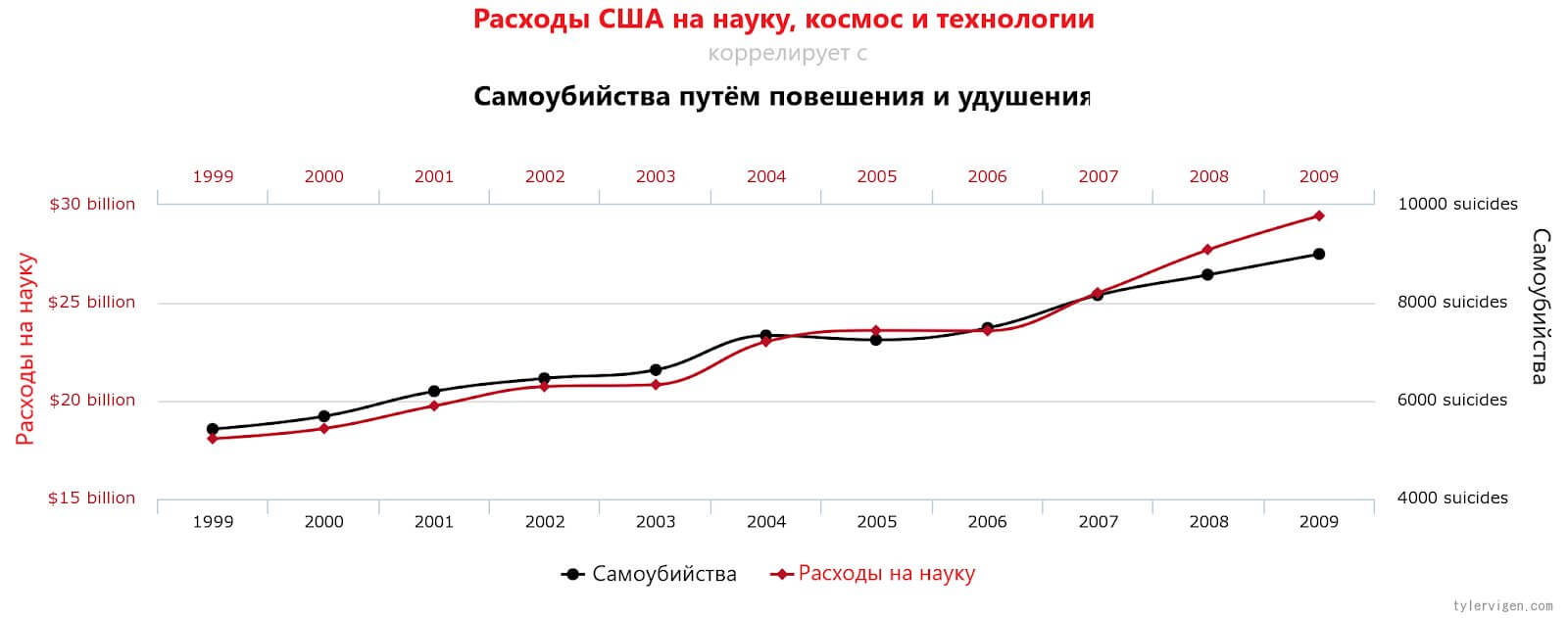
Всё это может выглядеть забавными совпадениями, но смысл в том, что алгоритм машинного обучения, обработав эти переменные единым набором, воспримет их как взаимозависимые, не подвергая эту зависимость сомнению. То есть алгоритм будет неточным или ошибочным, поскольку ПО выделит в датасете паттерны, которых не существует в реальном мире.
Это примеры ложных корреляций, которые в последние годы опасно распространились в связи с использованием наборов данных из тысяч переменных.
Если у нас есть тысяча переменных и миллионы точек данных, определённые корреляции неизбежны. Алгоритмы могут сконцентрироваться на этом и предположить причинно-следственную связь, невольно реализуя технику p-hacking, не слишком одобряемую в академических кругах.
Что такое p-hacking
Суть p-hacking’а состоит в дотошном поиске в наборе данных статистически значимых корреляций и принятии их за научно обоснованные.
Чем больше у вас данных, тем вероятнее найти ложные корреляции двух переменных.
Обычно научный подход последовательно включает формулирование гипотезы, сбор данных и анализ собранных данных для подтверждения обоснованности гипотезы. В процессе же p-hacking’а сначала проводится эксперимент, и по его результатам формируются гипотезы, объясняющие полученные данные. Иногда это делают без злого умысла, но временами учёные прибегают к такому методу только для того, чтобы получить возможность опубликовать больше материалов исследований.
Форсирование корреляций
Ещё одна проблема алгоритмов машинного обучения заключается в том, что алгоритм должен делать предположения. Алгоритм не может «ничего не найти». Это означает, что алгоритм либо найдёт способ интерпретировать данные независимо от того, насколько они соотносятся между собой, либо не придёт к какому-либо определённому заключению (обычно это означает, что алгоритм был неверно настроен или данные плохо подготовлены).
В настоящий момент автор не знает алгоритма машинного обучения, который мог бы прийти к заключению, что данные не подходят для того, чтобы делать обоснованные выводы. Предполагается, что это работа учёного.
Зачем использовать машинное обучение?
Хороший вопрос. Машинное обучение упрощают анализ данных и алгоритмы МО делают за пользователя громадную работу. В тех областях, где учёные имеют дело с действительно большими объёмами данных, традиционные методы статистического анализа оказываются неэффективными и применение МО — единственный разумный способ обработки информации. Однако следует учитывать, что увеличение продуктивности работы за счёт ускорения анализа данных может быть скомпрометировано недостаточным качеством полученных прогнозов.
Что можно сделать?
Конечно, не всё так трагично. Та же проблема всегда присутствовала при использовании традиционных статистических методов анализа. Она лишь усугубилась с появлением больших наборов данных и алгоритмов, которые находят корреляции автоматически и не настолько прозрачны, как стандартные методы. И это усиление выявило недостатки научного процесса, которые ещё предстоит преодолеть.
В то же время при разработке систем машинного обучения нового поколения предстоит проделать серьёзную работу, чтобы можно было точно определить достоверность и воспроизводимость результатов анализа.
Как говорится, плох тот рабочий, что винит в неудаче инструмент, и учёным следует уделять больше внимания применяемым алгоритмам МО, чтобы удостовериться в обоснованности выводов их исследований. Институт рецензирования предназначен для отсеивания необоснованных научных работ, но это также и задача каждого отдельно взятого исследователя. Учёные должны знать принципы работы применяемых ими методов, чтобы понимать ограничения этих инструментов. Если их познаний в этой области недостаточно — возможно, стоит заглянуть на кафедру статистики.
Рахими (тот учёный, что считает МО разновидностью алхимии) предлагает несколько подходов, которые позволят определить, как и когда лучше всего применять определённый алгоритм. Он утверждает, что при выборе алгоритма следует проводить исследования абляции — последовательно удаляя параметры, чтобы определить их влияние на выбранную модель МО. Он также предлагает делать анализ срезов — изучая производительность алгоритма, чтобы определить, как улучшения в определённых областях могут отразиться на чём-то ещё. Наконец, он предлагает прогонять алгоритм на разных наборах гиперпараметров, анализируя производительность системы для каждого из них. Таким образом можно повысить уверенность в результатах прогнозов, полученных с помощью МО.
Из-за природы научного процесса, если вышеописанные проблемы будут решены, ложные взаимоотношения, выведенные в результате исследований с применением машинного обучения будут выявлены и дискредитированы. Истинные же корреляции пройдут проверку временем.
Заключение
Машинное обучение в науке представляет проблему из-за того, что результаты недостаточно воспроизводимы. Однако учёные в курсе этой проблемы и работают над моделями МО, дающими более воспроизводимый и прозрачный результат. Настоящий прорыв произойдёт, когда эта задача будет решена для нейросети.
Дженевьера Аллен подчёркивает фундаментальную проблему искусственного интеллекта: учёные до сих пор не понимают механизма машинного обучения. Научное сообщество должно направить согласованные усилия на изучение принципов работы этих алгоритмов и на определение того, как лучше использовать основанные на обработке данных методы для получения надёжных, воспроизводимых и научно обоснованных выводов.
Даже Рахими, считающий МО алхимией, всё же признает его потенциал. Он отмечает, что алхимия породила металлургию, фармацевтику, технологии окраски тканей, современные процессы получения стекла. Но алхимики также верили в возможность трансмутации металлов в золото и в то, что пиявки — отличный способ для лечения заболеваний.
Как сказал физик Ричард Фейнман в своей речи перед выпускниками Калифорнийского технологического института в 1974 году:
Первый принцип [науки] заключается в том, чтобы не одурачить самого себя. И как раз себя-то одурачить проще всего.
Материалы по теме (на английском)
- The scientific method in the science of machine learning.
- Machine learning is disrupting science research: Here’s how.
- Improving machine learning reproducibility in genetic association studies with proportional instance cross validation (PICV).
- AI researchers allege that machine learning is alchemy.
- Can we trust scientific discoveries made using machine learning?
- Machine learning, and how it helps researchers make scientific discoveries much faster.
- People cause replication problems, not machine learning.
- Machine learning for science proving problematic.
- How artificial intelligence Is changing science.
- Machine learning for science.
- How AI, machine learning are advancing academic research.
- A quick response to Genevera Allen about Machine learning ‘causing science crisis’.
- Machine learning takes heat for science’s reproducibility crisis.

7К открытий7К показов

Смартфоны с ИИ. Показываем, как работает искусственный интеллект на смартфонах. Рассматриваем новые модели и будущее новых технологий ✔ Tproger

Хотите войти в ML в 2025 году? Рассказываем, как не утонуть: какие инструменты нужны, на чём писать, как учиться, что тренировать, куда выкладывать и где искать задачи.

Microsoft снова нанимает после массовых сокращений, но теперь ИИ решает, кого брать. Компания делает ставку на AI-first сотрудников

Сравниваем GPU-хостинги 2025 года по ценам, доступности и гарантиям SLA.