


Как с помощью нейросети стилизовать изображение под работу известного художника: разбираемся с нейронным переносом стиля

Как стилизовать свои изображения под картины известных художников с помощью концепции глубокого обучения? Разбираемся в статье.
23К открытий25К показов
В этой статье рассказывается о том, как использовать deep learning для стилизации изображения по заданному образцу. Это возможно благодаря нейронному переносу стиля (англ. neural style transfer). Эта техника описана в статье Leon A. Gatys, A Neural Algorithm of Artistic Style.
Нейронная передача стиля — это процесс оптимизации, который работает с 3 изображениями: картинкой содержания, картинкой стиля (например произведением художника) и входной картинкой. Если «смешать» их, то получится входная картинка, подогнанная по композиции под картинку содержания в образе копируемого стиля.
Для примера возьмём фотографию черепахи и гравюру Кацусики Хокусая «Большая волна в Канагаве»:
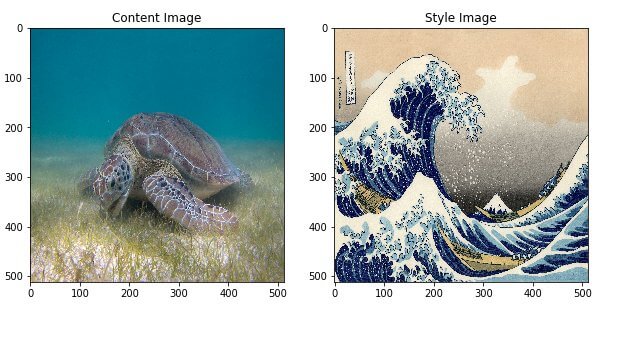
И что бы вышло, если бы художник решил стилизовать фотографию черепахи под свою гравюру? У него получилось бы что-то подобное:

Принцип передачи стиля заключается в определении двух функций расстояния. Одна из них описывает, насколько друг от друга отличаются содержания двух изображений (Lcontent). Вторая функция описывает разницу между двумя стилями изображений (Lstyle). Получив три изображения (желаемый стиль, желаемый контент и входное изображение), сеть пытается преобразовать входное изображение так, чтобы минимизировать его расстояние Lcontent с изображением контента и расстояние Lstyle с изображением стиля.
О чём статья
Статья освещает следующие аспекты:
- моментальное исполнение (англ. Eager Execution) — использование библиотеки TensorFlow, которая позволяет выполнять операции незамедлительно, без построения графов. Тут можно узнать больше о моментальном исполнении, а увидеть в действии можно тут;
- работа с functional API для определения модели — вы будете использовать подмножество моделей, чтобы получить доступ к важным промежуточным функциям активации с помощью functional API;
- использование карт признаков подготовленной модели;
- создание собственных циклов обучения — вы научитесь минимизировать заданные потери входных параметров.
Выполняя перенос стиля, вы проделаете следующие шаги:
- Визуализация данных.
- Базовая предварительная обработка/подготовка данных.
- Настройка функций потери.
- Создание модели.
- Оптимизация функции потери.
Примечание Этот пост рассчитан на тех, кто уже знаком с базовыми концепциями машинного обучения. Чтобы извлечь максимум из этой статьи, рекомендуется сначала ознакомиться со следующими материалами:
- https://tproger.ru/translations/6-step-for-building-machine-learning-projects/
- https://tproger.ru/translations/math-for-ai-linear-algebra/
- https://tproger.ru/video/machine-learning-2014/?autoplay=1
- https://tproger.ru/digest/learning-neuroweb-all-for-begin/
- https://tproger.ru/experts/required-ml-skills/
Код
Вы сможете найти полные исходники здесь. Если вы хотите детально разобрать примеры из этой статьи, то можно перейти на Colab.
Реализация
Начать стоит с включения моментального исполнения. Это позволит вам работать с техникой переноса стиля наиболее эффективным и понятным образом.
Определите представления содержания и стиля
Чтобы получить представление контента и стиля картинки, в первую очередь нужно посмотреть на промежуточные слои модели. Промежуточные слои представляют собой карты признаков, которые по мере углубления становятся более упорядоченными. В этом случае стоит использовать сетевую архитектуру VGG19 — предварительно подготовленную сеть классификации изображений. Промежуточные слои играют важную роль в определении представлений. Для входного изображения нужно сопоставить соответствующие представления на этих промежуточных слоях.
Почему именно промежуточные слои?
Вы можете задаться вопросом: почему эти промежуточные выводы дают возможность определить стиль и контент изображения? Чтобы сеть могла классифицировать изображение (чему она уже была обучена), она должна понимать это изображение. Это включает в себя построение из группы пикселей сложных представлений объектов на изображении. Отчасти это объясняет, почему свёрточные нейронные сети могут хорошо обобщать: они способны заметить постоянство и определить особенности, характерные для какого-либо класса (чтобы отличить, например, кота от собаки), не обращая внимания на фоновый шум. Таким образом, где-то между подачей изображения на вход и выводом результата классификации этого изображения, стоит модель, которая находит признаки во входных данных. Соответственно, обращаясь к этой самой промежуточной точке (т. е. слоям), можно без труда получить представление стиля и содержания изображения.
Вот как выглядит работа с промежуточными слоями сети:
Модель
Сначала нужно загрузить VGG19 и подать тензор на вход модели. Это даст возможность получать карты признаков, а впоследствии — представления стиля и контента.
Плюсом VGG19 является её относительная простота (по сравнению с ResNet, Inception и им подобным). Поэтому карты признаков будут лучше подходить для переноса стиля.
Чтобы получить доступ к промежуточным слоям, соответствующим картам признаков стиля и контента, нужно получить характерные выходные данные, используя Keras functional API для определения модели с требуемыми выходными функциями активации.
Благодаря functional API определение модели сводится к банальному определению входных и выходных данных:
В приведённом выше коде подгружается подготовленная сеть классификации изображений. После этого нужно взять необходимые слои, про которые говорилось ранее. Затем нужно определить модель. Это можно сделать, настроив входы для изображения и выходы для слоёв стиля и контента. Таким образом вы сможете создать модель, которая на входе принимает изображение, а на выходе выдаёт промежуточные слои для стиля и контента.
Определение и создание функций потерь (расстояний Lcontent и Lstyle)
Функция потерь для контента
Определить функцию потерь для содержимого на самом деле довольно просто. Нужно передать сети два изображения: изображение желаемого стиля и базовое. После этого вы получите промежуточные слои вашей модели. И единственное, что остаётся, это рассчитать Евклидово расстояние между двумя промежуточными представлениями этих изображений.
Если быть точным, то функция потерь описывает расстояние содержимого (Lcontent) между входным изображением x и изображением контентаp.Пусть тогда Cₙₙ будет предварительно обученной глубокой свёртываемой нейронной сетью. Опять же в этом случае будет использоваться VGG19.
Допустим, X— это любое изображение, тогда Cₙₙ(x) — это сеть, на вход которой подаётся X. Пусть тогда Fˡᵢⱼ(x) ∈ Cₙₙ(x)иPˡᵢⱼ(x) ∈ Cₙₙ(x) описывает соответствующие промежуточные представления объектов сети, принимающей X и P. Тогда Lcontent можно будет рассчитать по следующей формуле:
Таким образом обратное распространение обеспечивается так, чтобы минимизировать потерю контента. Нужно менять первоначальное изображение до тех пор, пока оно не сгенерирует аналогичный выход.
Реализовать это довольно просто. Как и в прошлом случае, на вход нужно подать карту признаков со слоя L сети со входом X, входное изображение и P — изображение контента. На выходе получится расстояние Lcontent.
Функция потерь для стиля
Расчёт функции потерь для стиля немного сложнее, но базируется на том же принципе. В этот раз на вход сети нужно подавать входное изображение и картинку стиля. Но теперь, вместо того чтобы сравнивать «сырые» данные с выходов базового и стиля изображения, нужно сравнить матрицы Грама этих двух выходов.
С математической точки зрения этот процесс заключается в описании функции потерь для стиля главного изображения (X) и изображения стиля (A) и расстояния между представлениями (матрица Грама) стиля этих двух картинок.
Представление стиля картинки можно описать как корреляцию между различными ответами фильтра матрицы Gˡ, где Gˡᵢⱼ — это внутреннее произведение между векторизированной картой признаков i и j в слое L.
Чтобы создать стиль для входного изображения, нужно выполнить градиентный спуск от изображения содержимого. Это нужно для того, чтобы трансформировать входное изображение в нечто похожее на изображение стиля. Это можно сделать, минимизировав среднее квадратичное расстояние между объектом корреляции карты стиля и входным изображением. Суммарное влияние каждого слоя на функцию потерь можно описать следующей формулой:
где Gˡᵢⱼ и Aˡᵢⱼ — это соответствующие представления на слое L входного изображения X и изображения стиля A. Nl описывает количество карт объектов, каждая из которых имеет размер Ml = высота * ширина. Исходя из этого, функция потерь всех слоёв будет такой:
где взвешивается влияние потери каждого слоя от какого-либо фактора wl. В этом случае все слои «взвешиваются» одинаково:
А вот, собственно, и реализация:
Градиентный спуск
Если вы не знакомы с градиентным спуском или обратным распространением, то вот ресурс, чтобы это исправить.
Чтобы минимизировать потери при переносе стиля, понадобится оптимизатор Adam. Для минимизации нужно многократно обновлять выходное изображение: не стоит как-либо изменять веса в сети. Вместо этого можно тренировать вход изображения. Чтобы это сделать, нужно понять, каким образом рассчитываются потери и градиенты. Используя Adam, можно понять функциональность autograd/gradient tape в собственных циклах обучения.
Расчёт потери и градиентов
Нужно создать всего лишь одну маленькую функцию, которая будет подгружать изображения стиля и контента, а потом передавать их сети. В будущем это даст представления признаков стиля и контента в модели:
Для расчёта градиента тут используется tf.GradientTape. Этот способ даёт преимущество использования автоматического дифференцирования, доступного благодаря трассировке последующих вычислений градиента. В этом случае во время прямого прохода операции кэшируются. Это даст возможность рассчитать потери градиента на обратном проходе.
В итоге расчёт градиента сводится к этому:
Запуск процесса переноса стиля
Вот так выглядит фактический запуск сети:
На этом всё!
Чтобы запустить нейронный перенос стиля, нужно просто вызвать функцию, передав ей пути к входным изображениям:


Вот ещё крутые примеры работы сети:


Ключевые моменты
В этой статье были разобраны следующие этапы:
- создание нескольких различных функций потерь и использование обратного распространения для входного изображения;
- для этого использовалась предварительно обученная модель и изученные карты признаков для описания содержимого на изображении;
- функциями потерь в основном являлись вычисления расстояний различных представлений;
- всё это выполнялось благодаря собственной модели и моментальным исполнениям;
- построение модели осуществлялось благодаря Functional API;
- моментальное исполнение позволило динамически работать с тензорами, используя естественный поток управления Python;
- управление тензорами велось напрямую, а это в свою очередь облегчило отладку и работу в целом.

23К открытий25К показов

Обзор российских локальных нейросетей, работающих без VPN: Study AI, Савви, ruGPT, Chad AI и BotHub. Сравниваем возможности, сценарии использования и тарифы для разработчиков, бизнеса и учебы.

Акции и прибыль NVIDIA падают из-за новой экономической политики США. Рассказываем, что происходит с рынком чипов и при чем здесь Китай.

На рынке появляются мягкие игрушки с искусственным интеллектом, обещающие заменить детям экранное время. Но безопасны ли такие AI-друзья и как они влияют на развитие ребёнка?

Что такое Security Operations Center. Показываем, как SOC защищает данные. Рассматриваем основные метрики и нюансы ✔ Tproger