


Программисты, учите статистику или я вас поубиваю!

19К открытий19К показов

Есть вещь, которая бесит меня больше всего. Всегда раздражают рассказы программистов, которые на словах специалисты в области статистики, а на деле ничего не понимают. Я изучаю эту науку много лет и до сих пор думаю, что ничего не знаю. Эта статья — мой призыв всем кто занимается написанием программ, хорошо изучить статистику, для того чтобы понять, как мало они знают. Мне непонятно, чем обоснована такая уверенность в своих ограниченных знаниях, превосходит которую только неуверенность в себе.
Для начала, немного о себе. Я заинтересовался статистикой тогда, когда начал изучать историю математики и то, как радикально изменила статистика способы изучения окружающего нас мира. До появления статистики как науки, существовало убеждение, что мир прекрасно описывается математическими моделями и любая найденная погрешность объяснялась отсутствием соответствующей математической модели. Спасибо Декарту, который развеял этот миф и доказал, что математика не может объяснить все. Со временем, все основные науки переняли эмпирический взгляд на мир. Кроме информатики, конечно.
Я обучался информатике весьма странным образом — больше изучал социологию, бизнес, экономику и историю нежели компьютерные науки. Я посещал несколько математических курсов, изучал статистику в университете, изучал язык программирования R и прочел уйму литературы по этой теме. Однако это ничуть не прибавило мне уверенности в том, что я до конца понимаю столь широкую тему. Единственное, что я могу, это применять статистические методы для решения общих задач, с которыми я сталкиваюсь в работе. Я обожаю решать задачи измерения и настройки производительности при помощи аппарата статистики.
Вопросы измерения производительности часто становятся причиной споров, поскольку ни у кого из моих коллег нет доказательств своей правоты. Я предложу свой способ измерения, а они смеются над этим. Я пробую показать, как правильно строить временную диаграмму, а это выводит их из себя. Я ставлю под сомнение их вычисления, а коллеги пытаются привести неубедительные, с точки зрения статистики, доказательства. Я не могу их винить, поскольку, скорее всего, так их научили в университете, что логика и причинно-следственная связь более значимы, чем наблюдение и доказательства. Даже великий Кнут однажды сказал:
В приведенном выше коде возможны ошибки, я только доказал, что он верен, но не запускал его.
Слепой на планете, где никто не видит
Думаю, вы все об этом думали в какой-то момент. «Представьте, что вы на планете, где все слепы, а вы — единственный зрячий. Как вы опишите закат?» Обычно это дается в качестве обычного скучного упражнения в университете. А вот если бы эта планета была бы населена программистами, это было бы действительно интересно.
Зед: Ух ты, здесь прекрасный синий закат.
Джо: Закат красный.
Зед: Он синий. Я же зрячий, забыл?
Фрэнк: Ага, но он красный. Ты идиот. Я слышу, как закат заставляет воздух двигаться, и я знаю, что он красный.
Зед: Пойми же ты, я единственный, кто видит! Он синий.
Джо: Я писал огромные веб-приложения на всех языках программирования и даже программировал на языке VAX. Я знаю, что закат красный.
Фрэнк: Он красный из-за тепла, которое ощущает моя рука. Я уверен в этом.
Зед: Вы не правы.
Джо: Это ты не прав.
Фрэнк: Не убедил.
Вот как я себя чувствую, когда пытаюсь объяснить ошибки в чьем-то доказательстве. В таких случаях я беру одну из многих моих книг по статистике, открываю командную строку языка R, начинаю строить графики и показываю их. Но практически всегда мне говорят, что я идиот. А когда этот человек программист, это даже хуже, поскольку я еще и показываю как это лучше сделать.
Приведу еще одну аналогию. Я встретил парня из Арканзаса, который сказал, что возможно изобрести вечный двигатель. «Да, сэр, вечный двигатель возможно сконструировать. Я прочитал это в интернете вчера. Ага». Обычно, в таких разговорах я даже не знаю с чего начать. «Не верь тому, что прочитал в интернете…». Нет же, этот парень читает «Hustler», поэтому лучше пусть читает хотя-бы в интернете. «Видишь ли, закон…» Опять же нет, физику здесь лучше вообще не использовать. Мне просто нечего сказать.
Разница между каким-то деревенщиной с Арканзаса и программистом без убедительных доказательств своей правоты в том, что, по идее, программист должен знать больше. Скорее всего, он более образован или умен, а может быть и то, и другое.
Кстати, вас не удивляет, что я говорю «он»? С женщинами-программистами у меня никогда не было таких проблем. Может быть потому, что я высокий или лучше к ним отношусь, но они всегда открыты к получению новых знаний и размышляют рационально. Если же они не согласны, то ведут спор крайне расчетливо и аргументируют сказанное. Поэтому я думаю, что женщины как программисты лучше мужчин, поскольку они менее эгоцентричны и более заинтересованы в развитии, чем в доказательстве собственной правоты.
Список вещей, которые меня раздражают
Этот список я мог бы продолжать вечно, но я пройдусь по основным моментам, которые меня бесят — это повсюду в IT индустрии. Измерения производительности, планирование распределения мощностей, документация к продукту и все, что пишет Microsoft про Linux. Я подробно остановлюсь на каждом пункте и опишу, как это можно прекратить и что почитать на эту тему.
Синдром «десяти в степени»
«Все, что Вам нужно сделать, это протестировать алгоритм [вставить степень 10] раз и усреднить результаты». Обычно это число берут равным 1000, но если тестирование занимает больше двух минут (ровно такое количество времени может сохранять концентрацию средний программист), то это число равно 10. Понятие «усреднения» я рассмотрю ниже, а пока обсудим проблемы с выбором количества итераций тестов равным «степени десяти» — я продемонстрирую эти проблемы на графике, которые обычно приводятся в таких случаях.
Откуда вы взяли, что 1000 – подходящее число итераций для улучшения производительности эксперимента?
«Производительность эксперимента» — знаете ли вы что означает этот термин? По сути это вероятность того, что Ваш опыт проводится верно (не совсем верное, но довольно точное определение). Для определения этой вероятности используется серьезный математический аппарат, а в языке R для этой цели написана функция, которая определяет размер тестирующей выборки, основываясь на желаемых показателях точности эксперимента. Для справки посмотрите функции power.t.test, power.prop.test в R.
Как вы проводите тестирование?
1000 последовательных итераций? Или 10 запусков по 100 тестовых значений? Статистические данные при этом будут отличаться, но второй вариант предпочтительней. В этом случае есть возможность сравнивать средние значения результата по каждой выборке и выяснить, есть ли смещение в выборке.
Как вы определяете, что 1000 – достаточное число для того, чтобы процесс пришел в стабильное состояние?
Общей характеристикой всех процессов является то, что все процессы вначале имеют период нестабильности. Этот период обычно не учитывается при проведении исследований, за исключением тех случаев, когда тестирующая выборка имеет такую длину, которая включает в себя этот период. Многие думают, что длины выборки в 1000 элементов более, чем достаточно, но это полностью зависит от того, как функционирует система. Многим сложным интерактивным системам вполне достаточно 1000 итераций для перехода в стабильное состояние, тем более что 1000 операций такие системы выполняют быстро. Представьте себе систему проведения банковских операций, которая обрабатывает 10000 операций в секунду. Мне понадобилась целая минута, чтобы привести систему в стабильное состояние, так что тестирование на тысячу итераций это плавание по верхам.
Что делать если проведение 1000 экспериментов длится 10 часов? Как 1000 последовательных запросов поможет Вам определить производительность системы под нагрузкой?
Вы запускаете 1000 тестовых итераций последовательно, а потом выясняется, что система не выдерживает параллельной нагрузки. И это нормально, поскольку при параллельной нагрузке система имеет другие показатели производительности.
Если все что вы делаете для замера производительности системы это запуск 1000 тестов и расчет среднего, то, как тогда выявить узкие места в производительности? Прочитайте раздел «Только средние значения» чтобы узнать больше. Эту проблему можно наглядно продемонстрировать на графике. Используя следующий код на R:
Здесь создается два множества случайных чисел, распределенных по нормальному закону. Теперь, если я просто возьму среднее (среднее арифметическое или медиану) двух множеств, эти значения почти совпадают:
Оба значения приблизительно равны 30 (число 30 было передано вторым параметром). На этом моменте программисты могут закидать меня камнями, потому что если вы посмотрите на график значений величин, то увидите разницу (а – оранжевый, b – синий)
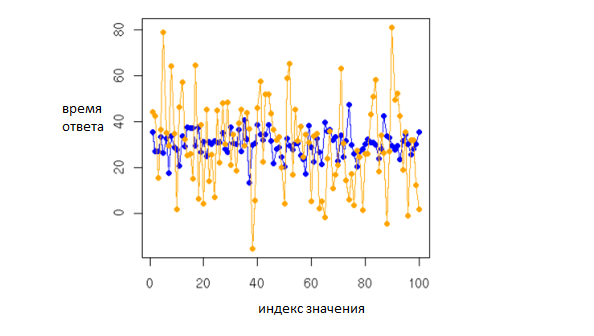
Третий параметр указывает на то, что мы хотим получить значения с разными среднеквадратическими отклонениями. Это сделает диапазон возможных ответов «шире» и при этом графики величин будут отличаться при одинаковых значениях среднего арифметического и медианы. Результат работы функции summary из языка R:
Даже без построения графика ясно, что диапазоны значений разные.
Только средние значения
Один очевидный момент доводит меня до исступления. Обычно это происходит, когда программист утверждает, что его система может обрабатывать [степень десяти] запросов в секунду. Цифра [степень десяти] для меня действует как красная тряпка для быка . [Степень десяти] неплохой показатель, если он был получен в результате тщательного исследования. Но обычно эта цифра берется с потолка.
Но больше всего меня тревожит то, что, кроме средних значений, нет никакой информации о диапазоне значений или дисперсии. Если взглянуть на предыдущие графики, то можно визуально понять, почему это проблема. Два средних значения равны, но кроют в себе большие различия в поведении. Без среднеквадратического отклонения невозможно выяснить находятся ли значения близко друг от друга. Для нормально распределенных данных лучше использовать тест Стьюдента для проверки есть ли различия между значениями.
Рассмотрим среднеквадратическое отклонение двух выборок:
Вот теперь видно различия! Если бы это были бы значения производительности веб-сервера, я бы сказал, что второй сервер (обозначенный b) нестабилен. Нет, он не будет ломаться, но его производительность настолько непредсказуема, что вы никогда не сможете спрогнозировать, время выполнения запроса. Несмотря на то, что среднее время обработки запросов у двух серверов одинаковое, пользователи все равно будут думать, что второй сервер работает медленнее, поскольку время обработки команд у того случайно. Конечно, среднеквадратическое отклонение не может быть характеристикой производительности сервера, поскольку тот имеет отрицательные временные значения, но это было приведено для примера.
Почему это так важно? Вот еще два графика иллюстрирующих как важно последовательное поведение для измерения производительности – и собственно, всех характеристик процессов, которые можно измерить. Первый график – это выборка а, и второй график выборка b:
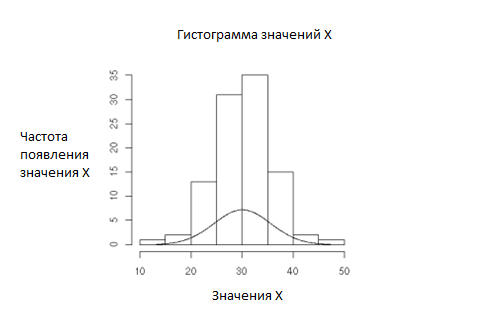
Обычно таких графиков не получается после измерений производительности, но идея остается той же. Первый график представляет из себя гладкую кривую. При этом график соответствует гистограмме. Так должен выглядеть процесс с последовательным поведением.
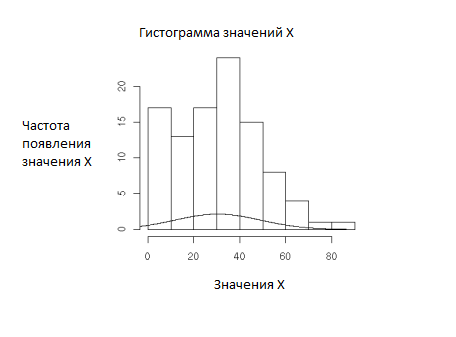
Второй график демонстрирует полный хаос, который происходит во время процесса. Этот график иллюстрирует тот факт, что процессы с непоследовательным поведением не соответствуют своему предполагаемому распределению. Мы знаем, что значения распределены по нормальному закону, но график показывает обратное.
Мораль сей басни такова – если вы измеряете средние значения без среднеквадратической ошибки, вы точно делаете что-то не так. Основная цель измерений – получить краткую и точную картину происходящего в системе, и если вы не нашли среднеквадратическое отклонение и не построили хотя бы пару графиков, тогда вы облажались.
Неоднозначность, неоднозначность, неоднозначность
Неоднозначность. Самая элементарная часть любого научного эксперимента, которую, тем не менее, сложнее всего объяснить программисту. Принцип довольно прост: нужно измерять только однородные величины. Тоже мне новость! Но этот принцип сложнее выполнять в лабораторных исследованиях, особенно если они связаны с сельским хозяйством. При этом неоднозначности программисты могут легко избежать при помощи разделения систем.
Вот пример, почему неоднозначность это плохо. Представьте, что Вам поручено сравнить несколько вкусов мороженого, но часть брикетов подтаяла, а часть заморожена. То есть температурный показатель при этом имеет неоднородную структуру для проведения Вашего сравнительного анализа. Для того, чтобы избавится от этой проблемы нужно все мороженое привести к одной температуре. Можно, конечно, и заморозить его, но идея, думаю, понятна.
А как определить факт того, что измеряемые величины неоднозначны, неоднородны? В реальных условиях иногда это сделать невозможно, поэтому умные люди предлагают уменьшить влияние неоднородности данных. Один из способов – это перемешать в случайном порядке значения неоднородного элемента таким образом, чтобы неоднородность не влияла на исследование. Если необходимо узнать какое удобрение лучшее, но свойства почвы и воды отличаются на всех 20 акрах поля, то Вам нужно поместить удобрения в случайные места на поле. Задача становится еще более сложной, поскольку есть участки поля с очень плохой плодородностью.
Погодите, мы же программисты, а не фермеры. Можно взять строку кода и протестировать ее. Можно проверить один запрос к БД, что в таком случае нас останавливает? Глупость, вот что. Программисты просто не сталкиваются с неоднозначностью данных и компании используют их для сравнения производительности или безопасности систем, которые полностью состоят из неоднородных элементов.
Классическим примером является приложение Pet Store от Sun. Pet Store – пример приложения, которое показывает основы J2EE. Потом Microsoft реализовала аналогичное приложение при помощи ASP. При этом по производительности приложение обставило аналогичное написанное на Java. При этом провести сравнительный анализ систем оказалось невозможно. Приложения были запущены на различных ОС, отличались URL, элементы форм, базы данных на сервере и процедура тестирования отличались кардинально. Сравнение приложения проводилось для замера количества пользователей Х, но не включало в себя время выполнения на одной странице, какие конфигурации БД были использованы, системные настройки.
Для проведения такого сравнительного анализа необходимо свести к минимуму количество отличающихся элементов. Одинаковые БД, ОС, одинаковый дизайн страниц и форм, логика приложения. Еще более правильный подход – это сравнивать производительность не на всех этапах работы приложения, а только интересующие моменты, например производительность при отрисовкe HTML страниц.
Возможность исключить неоднозначные элементы чтобы понять суть проблемы – также ценный инструмент анализа. Я работал на финансовую компанию, которая выпустила приложение для отдела продаж. Мы провели всю ночь воскресения, настраивая систему, а на утро понедельника получили странные 2-3 минутные задержки при выполнении некоторых запросов. Наш прямой начальник (это женщина) поручила мне разобраться с этим.
Ответственный менеджер утверждал, что виноват администратор БД. Виновны мы программисты. В общем, он обвинял всех и вся. Я проверил программный код, но ничего странного не заметил. Я решил пройтись по каждому элементу в цепочке, по которой обрабатывался запрос. Отрисовка JSP? Нет, время отрисовки – доли секунды со среднеквадратическим отклонением в доли секунд. Программный код контроллера? Нет. БД Microsoft SQL? Нет. БД показывает прекрасную производительность и стабильное поведение.
Тогда я посмотрел на IBM DB2. И тут была зарыта собака. Почти все запросы выполнялись прекрасно, кроме одного, который, в среднем, отрабатывал за доли секунды, но со среднеквадратическим отклонением в 60 секунд!! Я сделал график времени выполнения запросов, сделал разбивку по таблице и сказал «Дело не в самой базе данных, а в ее настройках. Вот расчеты, которые это показывают».
На следующий день уже IBM исправляло эту проблему (оказалось, что проблема возникала при обновлении индекса БД) и все мы сохранили свои должности.
Определение «пользователя»
Я работал с одним кретином, которого мы называли Mr. BJ, который постоянно утверждал, что мои вычисления не стоят ломаного гроша. Я проводил сравнительный анализ системы Х и показал, что она не выдержит большого количества запросов от студентов (это была университетская система). Он сказал, что я ошибся, поскольку я не измерил какое количество«пользователей» выдержит система. Я спросил у Mr. BJ как он определяет «пользователя», на что он ответил: «Ну, он заполняет формы, клацает везде».
Перед тем, как что-либо измерять, нужно вначале получить четкое понимание того, что мы измеряем. Вам нужно измерять значения только одной атомарной величины, чтобы не смешивать все. До сих пор я вижу разработчиков, которые выпрашивают огромные суммы денег на покупку дурацкой программы, которая даже не подразумевает подсчет каких-то статистических показателей вроде «среднеквадратического отклонения», но зато оперирует «пользователями».
Больше всего меня бесит то, что люди в IT верят всем характеристикам, которые измеряются в рамках «среднего пользователя». Существуют целые научные дисциплины для определения, что же такое «средний пользователь». Ваш ничтожный Jmeter со своими мерзкими графиками и еще более худшим подсчетом статистики ничем не поможет Вам со сбором статистики от Ваших пользователей.
Какое количество данных может быть обработано за секунду?
Конечно, «количество данных» зависит от приложения, но если Вам необходимо обрабатывать 1000 запросов в секунду, а Ваш Веб-сервер максимально обрабатывает 100 запросов, то Ваше приложение, пусть даже использующее JSP+EJB+Hibernate+SOAP, не выдаст результатов лучше.
Измерение любы других параметров это как определять у кого самый быстрый автомобиль поехав за яйцами в супермаркет. В итоге, все что вы получите — это битые яйца.
Дополнительная информация по теме
Я прочитал много книг по теме, но есть несколько, которые вы можете посмотреть:
- «Statistics» by Freedman, Pisani, Purves, and Adhikari. Norton publishers.
- «Introductory Statistics with R» by Dalgaard. Springer publishers.
- «Statistical Computing: An Introduction to Data Analysis using S-Plus» by Crawley. Wiley publishers.
- «Statistical Process Control» by Grant, Leavenworth. McGraw-Hill publishers.
- «Statistical Methods for the Social Sciences» by Agresti, Finlay.Prentice-Hall publishers.
- «Methods of Social Research» by Baily. Free Press publishers.
- «Modern Applied Statistics with S-PLUS» by Venables, Ripley. Springer publishers.
Также есть несколько книг по статистике и процессу разработки ПО, которые можно сразу использовать в работе. Кроме того, можно посмотреть www.r-project.org – язык программирования, который использовался в статье. Этот язык программирования прекрасно подходит для изучения статистики, поскольку обладает широкими возможностями визуализации. Изучение R также поспособствует лучшему пониманию статистики.
Перевод статьи «Programmers Need To Learn Statistics Or I Will Kill Them All».

19К открытий19К показов

Как балансировщики нагрузки распределяют HTTP-запросы между серверами. Рассматриваем подходы: от простых базовых алгоритмов до больших современных решений.

Microsoft выпустила Visual Studio 2026 и .NET 10: 5000 исправлений, 300 функций, новый Fluent UI, интеграция Copilot и рост скорости

Кто в ИТ имеет самый высокий доход. Рейтинг специальностей с самыми высокими зарплатами в 2025. Какие профессии стоит освоить.

Google представила Pixel 10 с чипом Tensor G5 и Gemini Nano: десятки ИИ-функций, включая Magic Cue, Voice Translate и Pixel Journal