Работа с данными по-новому: Pandas вместо SQL
Статья покажет, как переписать SQL-запросы для Pandas и многое другое. Эта библиотека хорошо подходит для структурированных данных.
Раньше SQL как инструмента было достаточно для исследовательского анализа: быстрого поиска данных и предварительного отчёта по ним.
Сейчас данные бывают разных форм и не всегда под ними подразумевают «реляционные базы данных». Это могут быть CSV-файлы, простой текст, Parquet, HDF5 и многое другое. Здесь вам и поможет библиотека Pandas.
Что такое Pandas?
Pandas — это библиотека на языке Python, созданная для анализа и обработки данных. Имеет открытый исходный код и поддерживается разработчиками Anaconda. Эта библиотека хорошо подходит для структурированных (табличных) данных. Дополнительную информацию можно найти в документации. Pandas позволяет формировать запросы к данным и многое другое.
SQL — декларативный язык. Он позволяет объявлять всё таким образом, что запрос похож на обычное предложение в английском языке. Синтаксис Pandas сильно отличается от SQL. Здесь вы применяете операции к набору данных и объединяете их в цепочку для преобразования и изменения.
Разбор SQL-запроса
SQL-запрос состоит из нескольких ключевых слов. Между этими словами добавляются характеристики данных, которые вы хотите видеть. Пример каркаса запросов без конкретики:
SELECT… FROM… WHERE…GROUP BY… HAVING…ORDER BY…LIMIT… OFFSET…
Есть и другие выражения, но эти самые основные. Чтобы перевести выражения в Pandas, нужно сначала загрузить данные:
Скачать эти данные можно здесь.
SELECT, WHERE, DISTINCT, LIMIT
Ниже представлено несколько вариантов выражений с оператором SELECT. Ненужные результаты отсекаются с помощью LIMIT и отфильтровываются с помощью WHERE. Для удаления дублированных результатов используется DISTINCT.

SELECT со множественным условием
Несколько условий выбора объединяются с помощью операнда &. Если нужно только подмножество некоторых столбцов из таблицы, это подмножество применяется в другой паре квадратных скобок.

ORDER BY
По умолчанию Pandas сортирует данные по возрастанию. Для обратной сортировки используйте выражение ascending=False.

IN и NOT IN
Чтобы фильтровать не одно значение, а целые списки, существует условие IN. В Pandas оператор .isin() работает точно так же. Чтобы отменить любое условие, используйте ~ (тильда).

GROUP BY, COUNT, ORDER BY
Группировка осуществляется с помощью оператора .groupby(). Есть небольшая разница между семантикой COUNT в SQL и Pandas. В Pandas .count() вернёт значения non-null/NaN. Для получения результата как в SQL, используйте .size().

Ниже приведена группировка по нескольким полям. По умолчанию Pandas сортирует по одному и тому же списку полей, поэтому в первом примере нет необходимости в .sort_values(). Если нужно использовать разные поля для сортировки или DESC вместо ASC, как во втором примере, выборку необходимо задавать явно:

Использование .to_frame() и .reset_index() обуславливается сортировкой по конкретному полю (size). Это поле должно быть частью типа DataFrame. После группировки в Pandas в результате получается другой тип, называемый GroupByObject. Поэтому нужно преобразовать его обратно в DataFrame. С помощью .reset_index() перезапускается нумерация строк для фрейма данных.
HAVING
В SQL можно дополнительно фильтровать сгруппированные данные, используя условие HAVING. В Pandas можно использовать .filter() и предоставить функцию Python (или лямбда-выражение), которая будет возвращать True, если группа данных должна быть включена в результат.

Первые N записей
Допустим, сделаны некоторые предварительные запросы и теперь имеется фрейм данных с именем by_country, который содержит количество аэропортов в каждой стране:

В следующем примере упорядочим данные по airport_count и выберем только первые 10 стран с наибольшим количеством аэропортов. Второй пример — более сложный случай, в котором выбираются «следующие 10» после первых 10 записей:

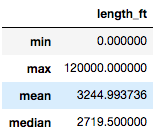
Агрегатные функции: MIN, MAX, MEAN
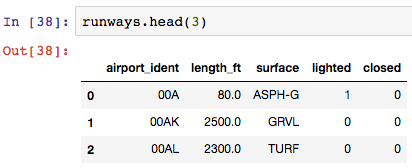
Учитывая фрейм данных выше (данные взлётно-посадочной полосы), рассчитаем минимальную, максимальную и среднюю длину ВПП.

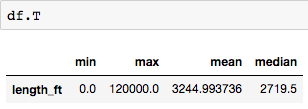
Заметьте, что с SQL-запросом данные представляют собой столбцы. Но в Pandas данные представлены строками.
Фрейм данных можно легко транспонировать с помощью .T, чтобы получить столбцы.
JOIN
Используйте .merge(), чтобы присоединить фреймы данных в Pandas. Необходимо указать, к каким столбцам нужно присоединиться (left_on и right_on), а также тип соединения: inner (по умолчанию), left (соответствует LEFT OUTER в SQL), right (RIGHT OUTER в SQL) или outer (FULL OUTER в SQL).

UNION ALL и UNION
pd.concat() — эквивалент UNION ALL в SQL.

Эквивалентом UNION (дедупликация) является .drop_duplicates().
INSERT
Пока осуществлялась только выборка, но в процессе предварительного анализа данные можно изменить. В Pandas для добавления нужных данных нет эквивалента INSERT в SQL. Вместо этого следует создать новый фрейм данных, содержащий новые записи, а затем объединить два фрейма.

UPDATE
Предположим, теперь нужно исправить некоторые неверные данные в исходном фрейме.

DELETE
Самый простой и удобный способ удалить данные из фрейма в Pandas — это разбить фрейм на строки. Затем получить индексы строк и использовать их в методе .drop().

Неизменность
По умолчанию большинство операторов в Pandas возвращают новый объект. Некоторые операторы принимают параметр inplace=True, что позволяет работать с исходным фреймом данных вместо нового. Например, вот так можно сбросить индекс на месте:
Однако оператор .loc (выше в примере с UPDATE) просто находит индексы записей для их обновления, и значения меняются на месте. Также, если все значения в столбце обновлены (df['url'] = 'http://google.com') или добавлен новый столбец (df['total_cost'] = df['price'] * df['quantity']), эти данные изменятся на месте.
Pandas — это больше, чем просто механизм запросов. С данными можно делать и другие преобразования.
Экспорт во множество форматов
Составление графиков
Получим:
Возможность поделиться своими работами
Лучшее место для публикации запросов Pandas, графиков и тому подобного — Jupyter notebook. Некоторые люди (например Джейк Вандерплас) публикуют там даже целые книги. Новую запись в блокноте создать просто:
После этого вы можете:
- перейти по адресу localhost:8888;
- нажать «New» и дать имя вашему блокноту;
- запросить и отобразить данные;
- создать репозиторий GitHub и добавить туда свой блокнот (файл с расширением
.ipynb).
У GitHub есть отличный встроенный просмотрщик для блокнотов Jupyter с оформлением Markdown.
В качестве подсказки на старте работы с библиотекой воспользуйтесь одной из наших шпаргалок по Python. Вам также может быть полезна подборка книг по SQL.




