


Обзор методов классификации в машинном обучении с помощью Scikit-Learn

Для машинного обучения на Python написано очень много библиотек. Сегодня мы рассмотрим одну из самых популярных — Scikit-Learn.
Scikit-Learn упрощает процесс создания классификатора и помогает более чётко выделить концепции машинного обучения, реализуя их с помощью понятной, хорошо документированной и надёжной библиотекой.
Что такое Scikit-Learn?
Scikit-Learn — это Python-библиотека, впервые разработанная David Cournapeau в 2007 году. В этой библиотеке находится большое количество алгоритмов для задач, связанных с классификацией и машинным обучением в целом.
Scikit-Learn базируется на библиотеке SciPy, которую нужно установить перед началом работы.
Основные термины
В системах машинного обучения или же системах нейросетей существуют входы и выходы. То, что подаётся на входы, принято называть признаками (англ. features).
Признаки по существу являются тем же, что и переменные в научном эксперименте — они характеризуют какой-либо наблюдаемый феномен и их можно как-то количественно измерить.
Когда признаки подаются на входы системы машинного обучения, эта система пытается найти совпадения, заметить закономерность между признаками. На выходе генерируется результат этой работы.
Этот результат принято называть меткой (англ. label), поскольку у выходов есть некая пометка, выданная им системой, т. е. предположение (прогноз) о том, в какую категорию попадает выход после классификации.
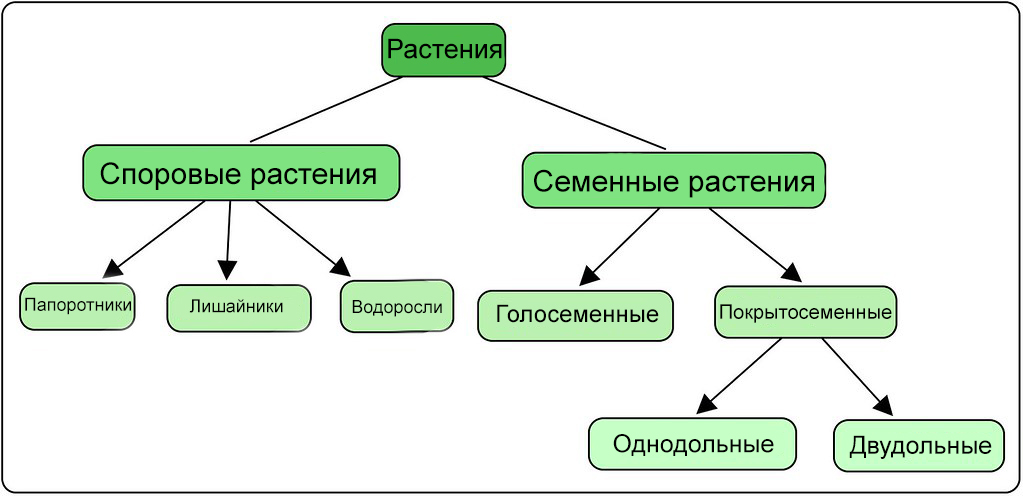
В контексте машинного обучения классификация относится к обучению с учителем. Такой тип обучения подразумевает, что данные, подаваемые на входы системы, уже помечены, а важная часть признаков уже разделена на отдельные категории или классы. Поэтому сеть уже знает, какая часть входов важна, а какую часть можно самостоятельно проверить. Пример классификации — сортировка различных растений на группы, например «папоротники» и «покрытосеменные». Подобная задача может быть выполнена с помощью Дерева Решений — одного из типов классификатора в Scikit-Learn.
При обучении без учителя в систему подаются непомеченные данные, и она должна попытаться сама разделить эти данные на категории. Так как классификация относится к типу обучения с учителем, способ обучения без учителя в этой статье рассматриваться не будет.
Процесс обучения модели — это подача данных для нейросети, которая в результате должна вывести определённые шаблоны для данных. В процессе обучения модели с учителем на вход подаются признаки и метки, а при прогнозировании на вход классификатора подаются только признаки.
Принимаемые сетью данные делятся на две группы: набор данных для обучения и набор для тестирования. Не стоит проверять сеть на том же наборе данных, на которых она обучалась, т. к. модель уже будет «заточена» под этот набор.
Типы классификаторов
Scikit-Learn даёт доступ ко множеству различных алгоритмов классификации. Вот основные из них:
- Метод k-ближайших соседей (K-Nearest Neighbors);
- Метод опорных векторов (Support Vector Machines);
- Классификатор дерева решений (Decision Tree Classifier) / Случайный лес (Random Forests);
- Наивный байесовский метод (Naive Bayes);
- Линейный дискриминантный анализ (Linear Discriminant Analysis);
- Логистическая регрессия (Logistic Regression);
На сайте Scikit-Learn есть много литературы на тему этих алгоритмов с кратким пояснением работы каждого из них.
Метод k-ближайших соседей (K-Nearest Neighbors)

Этот метод работает с помощью поиска кратчайшей дистанции между тестируемым объектом и ближайшими к нему классифицированным объектами из обучающего набора. Классифицируемый объект будет относится к тому классу, к которому принадлежит ближайший объект набора.
Классификатор дерева решений (Decision Tree Classifier)
Этот классификатор разбивает данные на всё меньшие и меньшие подмножества на основе разных критериев, т. е. у каждого подмножества своя сортирующая категория. С каждым разделением количество объектов определённого критерия уменьшается.
Классификация подойдёт к концу, когда сеть дойдёт до подмножества только с одним объектом. Если объединить несколько подобных деревьев решений, то получится так называемый Случайный Лес (англ. Random Forest).
Наивный байесовский классификатор (Naive Bayes)
Такой классификатор вычисляет вероятность принадлежности объекта к какому-то классу. Эта вероятность вычисляется из шанса, что какое-то событие произойдёт, с опорой на уже на произошедшие события.
Каждый параметр классифицируемого объекта считается независимым от других параметров.
Линейный дискриминантный анализ (Linear Discriminant Analysis)
Этот метод работает путём уменьшения размерности набора данных, проецируя все точки данных на линию. Потом он комбинирует эти точки в классы, базируясь на их расстоянии от центральной точки.
Этот метод, как можно уже догадаться, относится к линейным алгоритмам классификации, т. е. он хорошо подходит для данных с линейной зависимостью.
Метод опорных векторов (Support Vector Machines)
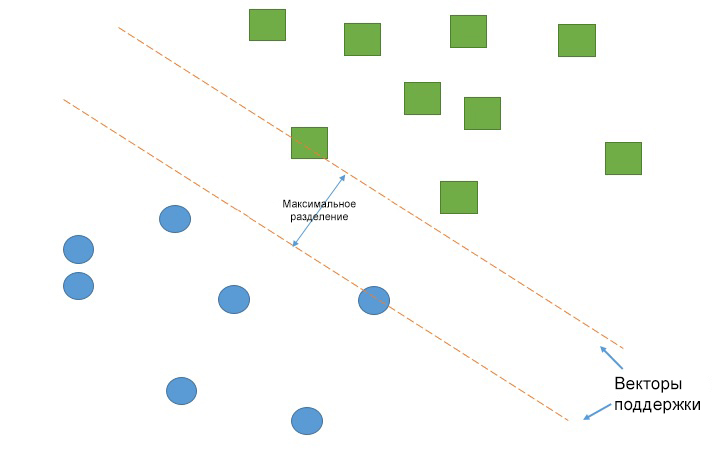
Работа метода опорных векторов заключается в рисовании линии между разными кластерами точек, которые нужно сгруппировать в классы. С одной стороны линии будут точки, принадлежащие одному классу, с другой стороны — к другому классу.
Классификатор будет пытаться увеличить расстояние между рисуемыми линиями и точками на разных сторонах, чтобы увеличить свою «уверенность» определения класса. Когда все точки построены, сторона, на которую они падают — это класс, которому эти точки принадлежат.
Логистическая регрессия (Logistic Regression)
Логистическая регрессия выводит прогнозы о точках в бинарном масштабе — нулевом или единичном. Если значение чего-либо равно либо больше 0.5, то объект классифицируется в большую сторону (к единице). Если значение меньше 0.5 — в меньшую (к нулю).
У каждого признака есть своя метка, равная только 0 или только 1. Логистическая регрессия является линейным классификатором и поэтому используется, когда в данных прослеживается какая-то линейная зависимость.
Примеры задач классификации
Задача классификации — эта любая задача, где нужно определить тип объекта из двух и более существующих классов. Такие задачи могут быть разными: определение, кошка на изображении или собака, или определение качества вина на основе его кислотности и содержания алкоголя.
В зависимости от задачи классификации вы будете использовать разные типы классификаторов. Например, если классификация содержит какую-то бинарную логику, то к ней лучше всего подойдёт логистическая регрессия.
По мере накопления опыта вам будет проще выбирать подходящий тип классификатора. Однако хорошей практикой является реализация нескольких подходящих классификаторов и выбор наиболее оптимального и производительного.
Реализация классификатора
Первый шаг в реализации классификатора — его импорт в Python. Вот как это выглядит для логистической регрессии:
Вот импорты остальных классификаторов, рассмотренных выше:
Однако, это не все классификаторы, которые есть в Scikit-Learn. Про остальные можно прочитать на соответствующей странице в документации.
После этого нужно создать экземпляр классификатора. Сделать это можно создав переменную и вызвав функцию, связанную с классификатором.
Теперь классификатор нужно обучить. Перед этим нужно «подогнать» его под тренировочные данные.
Обучающие признаки и метки помещаются в классификатор через функцию fit:
После обучения модели данные уже можно подавать в классификатор. Это можно сделать через функцию классификатора predict, передав ей параметр (признак) для прогнозирования:
Эти этапы (создание экземпляра, обучение и классификация) являются основными при работе с классификаторами в Scikit-Learn. Но эта библиотека может управлять не только классификаторами, но и самими данными. Чтобы разобраться в том, как данные и классификатор работают вместе над задачей классификации, нужно разобраться в процессах машинного обучения в целом.
Процесс машинного обучения
Процесс содержит в себе следующие этапы: подготовка данных, создание обучающих наборов, создание классификатора, обучение классификатора, составление прогнозов, оценка производительности классификатора и настройка параметров.
Во-первых, нужно подготовить набор данных для классификатора — преобразовать данные в корректную для классификации форму и обработать любые аномалии в этих данных. Отсутствие значений в данных либо любые другие отклонения — все их нужно обработать, иначе они могут негативно влиять на производительность классификатора. Этот этап называется предварительной обработкой данных (англ. data preprocessing).
Следующим шагом будет разделение данных на обучающие и тестовые наборы. Для этого в Scikit-Learn существует отличная функция traintestsplit.
Как уже было сказано выше, классификатор должен быть создан и обучен на тренировочном наборе данных. После этих шагов модель уже может делать прогнозы. Сравнивая показания классификатора с фактически известными данными, можно делать вывод о точности классификатора.
Вероятнее всего, вам нужно будет «корректировать» параметры классификатора, пока вы не достигните желаемой точности (т. к. маловероятно, что классификатор будет соответствовать всем вашим требованиям с первого же запуска).
Ниже будет представлен пример работы машинного обучения от обработки данных и до оценки.
Реализация образца классификации
Поскольку набор данных iris достаточно распространён, в Scikit-Learn он уже присутствует, достаточно лишь заложить эту команду:
Тем не менее, тут ещё нужно подгрузить CSV-файл, который можно скачать здесь.
Этот файл нужно поместить в ту же папку, что и Python-файл. В библиотеке Pandas есть функция read_csv(), которая отлично работает с загрузкой данных.
Благодаря тому, что данные уже были подготовлены, долгой предварительной обработки они не требуют. Единственное, что может понадобиться — убрать ненужные столбцы (например ID) таким образом:
Теперь нужно определить признаки и метки. С библиотекой Pandas можно легко «нарезать» таблицу и выбрать определённые строки/столбцы с помощью функции iloc():
Код выше выбирает каждую строку и столбец, обрезав при этом последний столбец.
Выбрать признаки интересующего вас набора данных можно также передав в скобках заголовки столбцов:
После того, как вы выбрали нужные признаки и метки, их можно разделить на тренировочные и тестовые наборы, используя функцию train_test_split():
Чтобы убедиться в правильности обработки данных, используйте:
Теперь можно создавать экземпляр классификатора, например метод опорных векторов и метод k-ближайших соседей:
Теперь нужно обучить эти два классификатора:
Эти команды обучили модели и теперь классификаторы могут делать прогнозы и сохранять результат в какую-либо переменную.
Теперь пришло время оценить точности классификатора. Существует несколько способов это сделать.
Нужно передать показания прогноза относительно фактически верных меток, значения которых были сохранены ранее.
Вот, к примеру, результат полученных метрик:
Поначалу кажется, что KNN работает точнее. Вот матрица неточностей для SVC:
Количество правильных прогнозов идёт с верхнего левого угла в нижний правый. Вот для сравнения метрики классификации для KNN:
Оценка классификатора
Когда дело доходит до оценки точности классификатора, есть несколько вариантов.
Точность классификации
Точность классификации измерять проще всего, и поэтому этот параметр чаще всего используется. Значение точности — это число правильных прогнозов, делённое на число всех прогнозов или, проще говоря, отношение правильных прогнозов ко всем.
Хоть этот показатель и может быстро дать вам явное представление о производительности классификатора, его лучше использовать, когда каждый класс имеет хотя бы примерно одинаковое количество примеров. Так как такое будет случаться редко, рекомендуется использовать другие показатели классификации.
Логарифмические потери
Значение Логарифмических Потерь (англ. Logarithmic Loss) — или просто логлосс — показывает, насколько классификатор «уверен» в своём прогнозе. Логлосс возвращает вероятность принадлежности объекта к тому или иному классу, суммируя их, чтобы дать общее представление об «уверенности» классификатора.
Этот показатель лежит в промежутке от 0 до 1 — «совсем не уверен» и «полностью уверен» соответственно. Логлосс сильно падает, когда классификатор сильно «уверен» в неправильном ответе.
Площадь ROC-кривой (AUC)
Такой показатель используется только при бинарной классификации. Площадь под ROC-кривой представляет способность классификатора различать подходящие и не подходящие какому-либо классу объекты.
Значение 1.0: вся область, попадающая под кривую, представляет собой идеальный классификатор. Следовательно, 0.5 означает, что точность классификатора соответствует случайности. Кривая рассчитывается с учётом точности и специфичности модели. Подробнее о расчётах можно прочитать здесь.
Матрица неточностей
Матрица неточностей (англ. Confusion Matrix) — это таблица или диаграмма, показывающая точность прогнозирования классификатора в отношении двух и более классов. Прогнозы классификатора находятся на оси X, а результат (точность) — на оси Y.
Ячейки таблицы заполняются количеством прогнозов классификатора. Правильные прогнозы идут по диагонали от верхнего левого угла в нижний правый. Про это можно почитать в данной статье.
Отчёт о классификации
В библиотеке Scikit-Learn уже встроена возможность создавать отчёты о производительности классификатора. Эти отчёты дают интуитивно понятное представление о работе модели.
Заключение
Чтобы лучше вникнуть в работу с Scikit-Learn, неплохо было бы узнать больше о работе различных методов классификации. После этого стоит лучше узнать о замере производительности классификаторов. Однако понимание многих нюансов в классификации приходит только со временем.





