Оконные функции в SQL — что это и зачем они нужны
Краткий гайд, который поможет разобраться в оконных функциях ORDER BY и PARTITION BY.
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
%save-sc0%
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
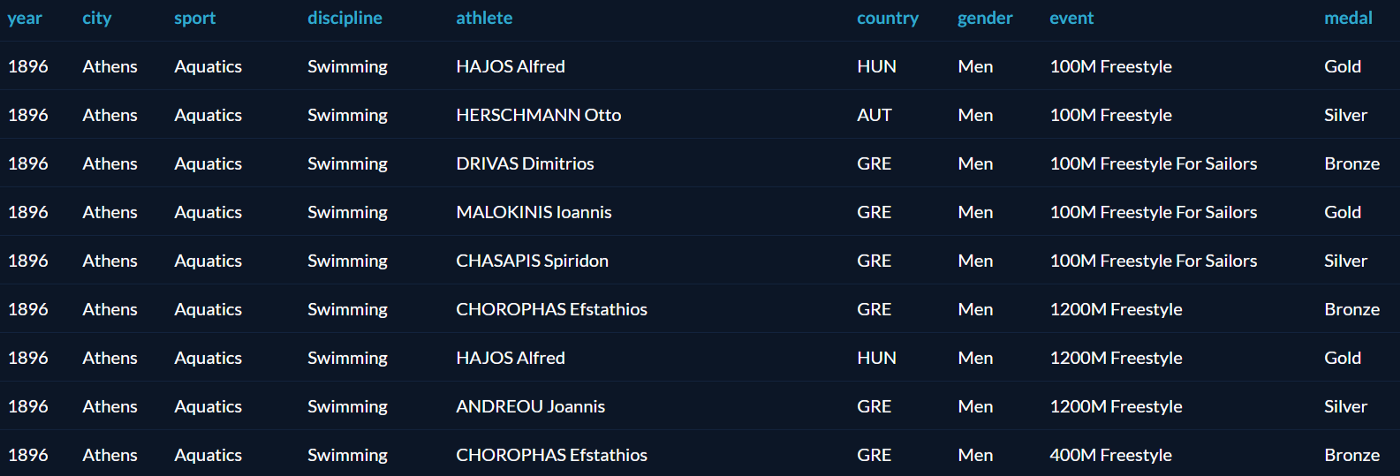
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
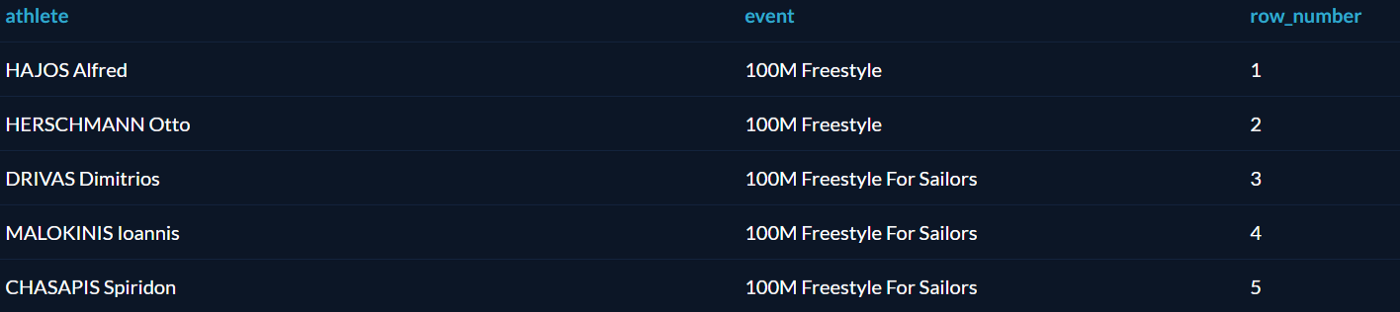
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:

PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
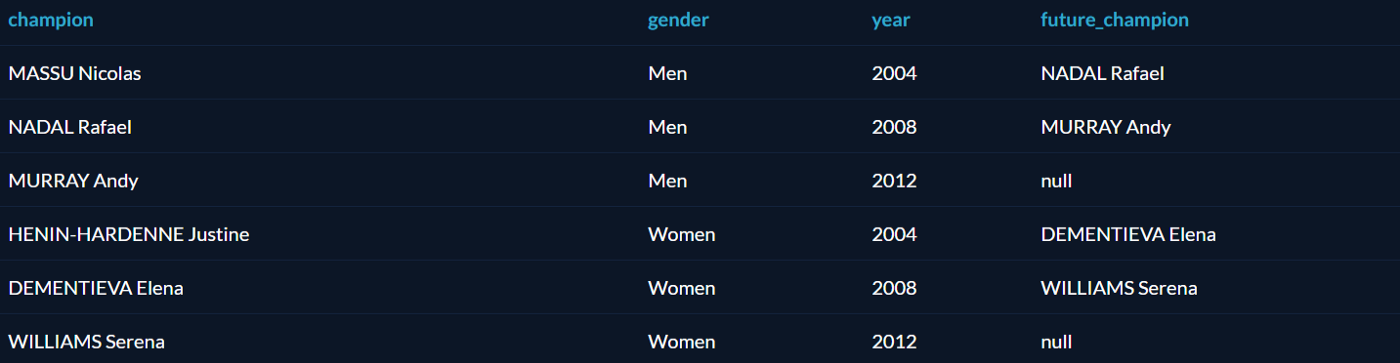
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:

LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает. Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
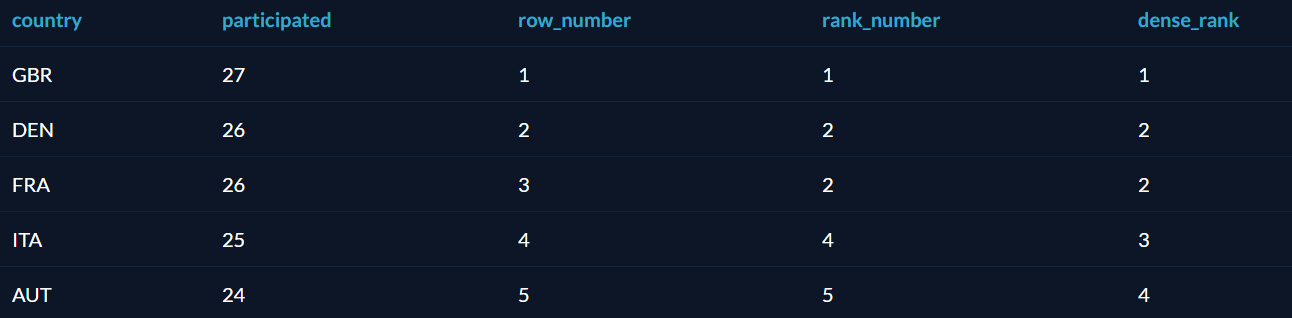
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.




{kind=link}
