


Алгоритмы интеллектуального анализа данных

30К открытий32К показов

Рассказывает Рэй Ли, автор блога raily.net
Сегодня я постараюсь простым языком объяснить 10 самых важных алгоритмов интеллектуального анализа данных, по результатам опросов трех разных групп экспертов в этом исследовании.
После того, как я расскажу вам об этих алгоритмах, о том как они работают, что делают и где их можно найти, я надеюсь, что вы используете свои новоприобретенные знания для еще более глубокого изучения добычи данных.
Давайте начнем!
1. C4.5
Что он делает? C4.5 создает классификатор в виде дерева решений. Для этого C4.5 дается набор данных, представляющий собой уже классифицированные вещи.
Стоп, а что такое классификатор? Классификатор — это инструмент для добычи данных, который принимает некоторое количество данных, представляющих то, что мы хотим классифицировать, и пытается предсказать, к какому классу эти новые данные должны принадлежать.
А можно привести пример? Конечно. Предположим, в наборе данных есть некоторое количество пациентов. О каждом из них нам известны различные факты: их возраст, пульс, кровяное давление, история наследственных заболеваний и т.д. Их называют атрибутами.
Итак:
Учитывая эти атрибуты, мы хотим предсказать, заболеет ли пациент раком. Пациент может попасть в один из двух классов: «заболеет раком» и «не заболеет раком». Мы сообщаем C4.5 о соответствующем классе каждого пациента.
Дело вот в чем:
С помощью набора атрибутов и соответствующего класса пациента, С4.5 строит дерево решений, которое может предсказать класс новых пациентов на основе их атрибутов.
Хорошо, но что такое дерево решений? Обучение дерева решений создает что-то похожее на блок-схему для классификации новых данных. Используя тот же пример с пациентами, один конкретный путь в блок-схеме может быть таким:
- у пациента есть история заболевания раком;
- у пациента есть ген, часто встречающийся у людей больных раком;
- у пациента есть опухоли;
- у пациента есть опухоли больше 5 см в диаметре.
Итог:
В каждой точке блок-схемы есть вопрос о значении какого-либо атрибута, и пациента классифицируют в зависимости от этих значений. Можно найти множество примеров деревьев решений.
Это обучение с учителем или без? Это обучение с учителем, так как обучение набора данных маркировано классами. Используя все тот же пример с пациентами, С4.5 не самостоятельно узнает, заболеет ли пациент раком или нет. Мы сначала сообщили ему об этом, он создал дерево решений и теперь использует это дерево для классификации.
Так чем же С4.5 отличается от других систем деревьев решений?
- Для начала, С4.5 использует относительную энтропию при генерировании деревьев решений.
- Несмотря на то, что другие системы тоже используют отсечение ветвей, С4.5 использует однопроходное отсечение ветвей, чтобы упростить переобучение. Отсечение ветвей существенно улучшает работу алгоритма.
- С4.5 может работать и с непрерывными, и с дискретными данными. Указав диапазоны или пороговые значения непрерывных данных, можно их превратить в дискретные.
- Наконец, с неполными данными он разбирается особым способом.
Почему стоит попробовать С4.5? Пожалуй, главным преимуществом деревьев решений является простота их понимания и объяснения. Они также довольно быстры, весьма распространены и их вывод удобочитаемый для человека.
Где его используют? Популярную открытую Java-реализацию можно найти на OpenTox. Orange, общедоступная программа для визуализации и анализа данных использует С4.5 в своем классификаторе деревьев решений.
Классификаторы – это, конечно, здорово, но все же вам стоит прочитать про следующий алгоритм и кластерный анализ…
2. k-means
Что он делает? K-means создает k количество групп из набора объектов таким образом, чтобы члены этой группы были больше похожи. Это популярный метод кластерного анализа для изучения набора данных.
Погодите, что такое кластерный анализ? Кластерный анализ — это семейство алгоритмов, предназначенных для формирования групп, где члены этих групп похожи друг на друга сильнее, чем на тех, кто в этой группе не состоит. Кластеры и группы являются синонимами в мире кластерного анализа.
А можно пример? Ну конечно. Предположим, у нас есть набор данных пациентов. В кластерном анализе они называются признаками. О каждом из пациентов нам известны различные факты: возраст, пульс, кровяное давление, уровень холестерина, и т.д. Это вектор характеристик, представляющий пациента.
Смотрите:
О векторе характеристик можно думать, как о списке известных нам чисел, связанных с пациентом. Этот список также может быть интерпретирован как координаты в многомерном пространстве. Пульс может быть одним измерением, кровяное давление — другим и так далее.
Вы, наверное, задаетесь вопросом:
Учитывая этот набор векторов, как же мы сгруппируем вместе пациентов, близких по возрасту, с похожими значениями пульса, кровяного давления и т.д.?
Хотите узнать лучшее свойство k-means?
Вы лишь задаете количество нужных вам кластеров. K-means заботится обо всем остальном.
Как же k-means заботится обо всем остальном? У k-means есть много вариаций для оптимизации определенных типов данных.
Не вдаваясь в подробности, это происходит примерно так:
- k-means выбирает точки в многомерном пространстве для каждого из k кластеров. Их называют центроидами.
- Каждый из пациентов будет ближе всего к одному из этих центроидов. Скорее всего, не все из них будут ближе всего к одному и тому же центроиду, так что сформируется несколько кластеров вокруг соответствующих центроидов.
- У нас теперь есть k количество кластеров, и каждый из пациентов принадлежит к одному из них.
- k-means после этого находит центр каждого кластера, опираясь на членов этих кластеров (используя векторы характеристик пациентов).
- Этот центр становится новым центроидом кластера.
- Так как центроид теперь в другом месте, пациенты могут оказаться ближе к другому центроиду. Другими словами, они могут перейти в другой кластер.
- Шаги 2-6 повторяются до тех пор, пока центроиды больше не изменяются. Это называется конвергенцией.
Это обучение с учителем или без? Большинство считают k-means самообучающимся алгоритмом. Кроме указания количества кластеров, k-means «узнает» кластеры сам по себе, без какой-либо информации о том, к какому кластеру принадлежит тот или иной признак. K-means может, тем не менее, быть полуконтролируемым.
Почему стоит попробовать k-means? Мне кажется, это понятно.
Главным преимуществом k-means является его простота. То, что он прост в реализации, означает, что он обычно быстрее и эффективнее других алгоритмов, особенно при работе с большим набором данных.
К тому же, k-means можно использовать для предварительного кластерного анализа огромных наборов данных, чтобы потом воспользоваться более затратным алгоритмом кластерного анализа на самих кластерах. K-means также может изучать упущенные связи в наборе данных путем резкого изменения k.
Но не все так радужно:
Двумя главными недостатками k-means являются его чувствительность к выбросам и первоначальному выбору центроидов. И последнее, k-means был разработан для работы с непрерывными данными. Вам придется воспользоваться некоторыми уловками для того, чтобы работать с дискретными данными.
Где он используется? Огромное количество реализаций k-means доступны в сети:
Если же деревья решений и кластеризация не произвели на вас впечатление, вам гарантированно понравится следующий алгоритм…
3. Метод опорных векторов
Что он делает? Метод опорных векторов (SVM) находит гиперплоскость для классификации данных в два класса. В двух словах, SVM выполняет задачу, аналогичную C4.5, за исключением того, что он не использует деревья решений.
Погодите, гипер-что? Гиперплоскость — это функция, к примеру, как линейное уравнение у = kх + b. Для простой задачи с классификации, где есть только два свойства, гиперплоскость может быть линией.
Как выясняется…
SVM может спроецировать ваши данные в более высокие измерения. А после этого…
… SVM находит наиболее подходящую гиперплоскость, разделяющую ваши данные в два класса.
Можно пример? Разумеется. Представим несколько красных и синих шаров на столе. Если шары не слишком сильно перемешаны, вы можете положить между ними палку, не двигая самих шаров.
Как видите:
Когда на стол кладут новый шар, зная при этом, на какой стороне палки он теперь находится, можно предсказать его цвет.
Что же символизируют шар, стол и палка? Шары символизируют точки данных, а красный и синий цвета символизируют два класса. Палка символизирует простейшую гиперплоскость – линию.
А знаете, что в этом самое замечательное?
То, что SVM сам выясняет функцию гиперплоскости.
А что, если все усложнить? Если шары перемешаны между собой, прямая палка не сработает.
Вот обходное решение:
Быстро поднимите стол — и шары окажутся в воздухе. В то время, пока шары все еще в воздухе, вы можете использовать большой лист бумаги, чтобы разделить их.
А это разве не жульничество?
Нет, поднятие стола соответствует отображению ваших данных в высших измерениях. В этом случае, мы переходим от двумерной плоскости стола к трехмерной, где шарики находятся в воздухе.
Как же SVM это делает? С использованием ядра у нас появляется приятный способ работы в высших измерениях. Большой лист бумаги все еще можно назвать гиперплоскостью, но теперь это функция плоскости, а не линии. Когда мы находимся в 3-х измерениях, гиперплоскость является плоскостью, а не линией.
Мне это помогла понять следующая визуализация:
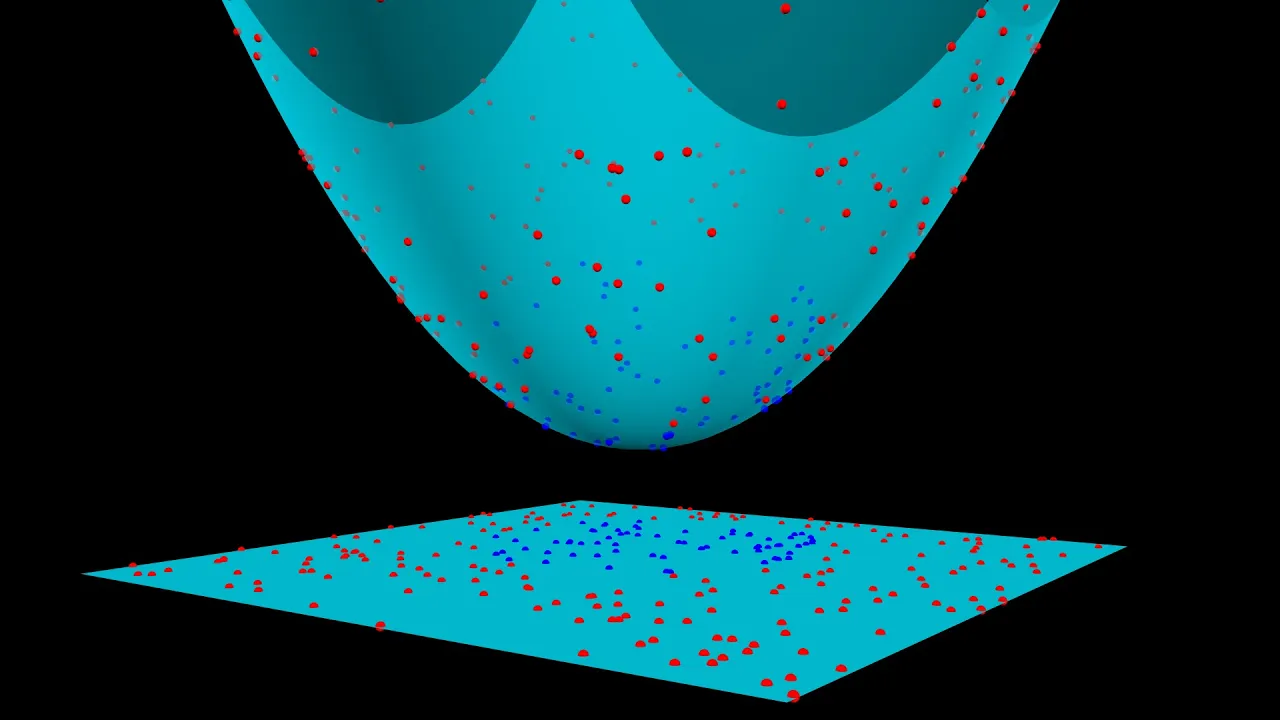
На Reddit тоже есть два замечательных объяснения на ELI5 и ML.
Как же шары на столе или в воздухе соотносятся с реальными данными? У шара на столе есть местоположение, которое можно определить с помощью координат. Например, шар может лежать на 20 см от левого края и 50 см от нижнего края. Другими словами, шар находится у (x, y) координат, или (20, 50). x и y – два измерения этого шара.
Дело вот в чем:
Если пациент является набором данных, у каждого из них есть множество характеристик: пульс, уровень холестерина, кровяное давление и т.д. Каждая из них является измерением.
В итоге:
SVM делает свое дело, отображает их в высшем измерении и потом находит гиперплоскость для разделения классов.
Зазоры часто связаны с SVM. Что это такое? Зазоры – это расстояние между гиперплоскостью и двумя ближайшими точками данных из соответствующих классов. Возвращаясь к примеру с шаром и столом, расстояние между палкой и ближайшим красным и синим шарами называется зазором.
Главное:
SVM пытается максимизировать зазор, чтобы гиперплоскость была одинаково далеко от красного и синего шаров. Таким образом, уменьшается вероятность ошибки в классификации.
Почему это называется методом опорных векторов? Возвращаясь к примеру со столом и шаром, поясним, что гиперплоскость равноудалена от красного и синего шара. Эти шары, или точки данных, называют опорными векторами, потому что на них опирается гиперплоскость.
Это обучение с учителем или без? Это обучение с учителем, так как набор данных в первую очередь используется, чтобы обучить SVM классам. Только в этом случае SVM сможет классифицировать новые данные.
Почему стоит использовать именно SVM? SVM и C4.5 — два классификатора, которые стоит попробовать в первую очередь. Нет классификатора, идеального во всех смыслах из-за теоремы No Free Lunch. Кроме того, другими недостатками алгоритма являются выбор ядра и интерпретируемость.
Где он используется? Существует достаточно много реализаций SVM. Самыми известными из них являются scikit-learn, MATLAB и, конечно же, libsvm.
Следующий алгоритм — один из моих любимых…
4. Apriori
Что он делает? Алгоритм Apriori ищет ассоциативные правила и применят их к базе данных, содержащей большое количество транзакций.
Что такое ассоциативные правила? Поиск ассоциативных правил — это метод извлечения данных для изучения корреляций и взаимосвязи между переменными в базе данных.
Приведите пример Apriori. Представим, что у нас есть база данных, полная транзакций одного супермаркета. Можно думать о базе данных, как о гигантской таблице, где каждая строка — транзакция клиента, а каждый столбец представляет собой разный продукт.
Лучшая новость такова:
Применяя Apriori, мы можем узнать о том, какие продукты приобретаются вместе, т.е. об ассоциативных правилах.
То есть, вы можете найти те товары, которые покупают вместе чаще, чем другие. Вместе они называются элементами набора. Конечной целью является увеличение количества покупок.
К примеру:
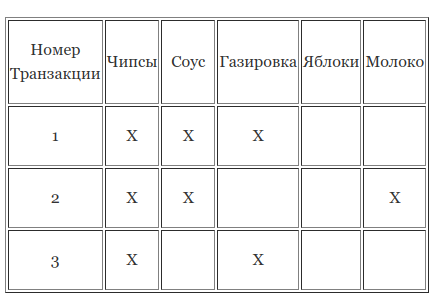
Вы скорее всего понимаете, что чипсы и газировку часто покупают вместе. Их называют 2-элементным набором. При достаточно большом наборе данных будет сложнее увидеть такие взаимоотношения, особенно если вы имеете дело с 3-элементными наборами и более. Это именно то, в чем вам может помочь Apriori!
Как же работает Apriori? Перед тем, как разобраться в основе алгоритма, вам нужно определиться с тремя пунктами:
- Размер вашего элементного набора.
- Поддержка, или количество транзакций, в которых встречается этот элементный набор, деленный на общее количество транзакций. Элементный набор, чья поддержка больше или равна минимальной поддержке, называется частым элементным набором.
- Достоверность, или условная вероятность того, как часто некоторый элемент встречается в вашем элементном наборе, при наличие в нем другого определенного элемента. К примеру, если в элементном наборе есть чипсы, то с достоверностью 67% там также есть и газированный напиток.
В основе Apriori 3 этапа:
- Объединение. Сканирование всей базы данных, чтобы определить, как часто встречаются 1-элементные наборы.
- Сокращение. Эти элементные наборы, удовлетворяющие поддержку и достоверность, проходят в следующий раунд для 2-элементных наборов.
- Повтор. Эта последовательность повторяется для каждого элементного набора, пока не достигнут определенный ранее размер.
Это обучение с учителем или без? Apriori обычно считают самообучающимся алгоритмом, так как он часто используется для нахождения и извлечения интересных закономерностей и взаимосвязей.
Но погодите, это еще не все…
Apriori можно модифицировать, чтобы классифицировать на основе нужных данных.
Почему стоит использовать Apriori? Apriori легко понять, реализовать, и у него есть множество производных.
С другой стороны…
Алгоритм может быть достаточно требователен по отношению к памяти и времени генерации элементных наборов.
Где его используют? Apriori достаточно часто встречается. Некоторыми из самых известных применений являются ARtool, Weka, и Orange.
Следующий алгоритм, как мне кажется, понять сложнее всего…
5.EM
Что он делает? В извлечении данных EM чаще всего используется как алгоритм кластеризации (как k-means) для обнаружения знаний.
В статистике EM итерирует и оптимизирует правдоподобие увидеть наблюдаемые данные при оценке параметров статистической модели с ненаблюдаемых переменных.
Давайте я объясню…
Я не статистик, так что надеюсь, что мое упрощенное объяснение будет правильным и поможет вам его понять.
Вот несколько понятий, которые помогут вам это понять…
Что такое статистическая модель? Я считаю, что модель — это что-то, что описывает, как генерируются наблюдаемые данные. К примеру, если оценки за экзамен соответствуют кривой нормального распределения, то предположение, что оценки сгенерированы через кривую нормального распределения, является моделью.
Погодите, что такое распределение? Распределение представляет вероятности для всех измеримых результатов. Например, оценки за экзамен могут соответствовать нормальному распределению. Это нормальное распределение представляет все вероятности определенной оценки.
Другими словами, учитывая оценку, вы можете использовать это распределение, чтобы определить, сколько сдающих этот экзамен, как ожидается, получат именно эту оценку.
Хорошо, а что такое параметры модели? Параметр характеризует распределение, являющееся частью модели. Например, кривая нормального распределения может быть охарактеризована ее средним значением и дисперсией.
Возвращаясь к сценарию экзамена, распределение оценок за экзамен (измеримые результаты) соответствовало кривой нормального распределения. Среднее значение — 85, дисперсия — 100 .
Чтобы охарактеризовать нормальное распределение нужны следующие два параметра:
- среднее значение,
- дисперсия.
А правдоподобие? Возвращаясь к нашему примеру, представьте, что у нас есть некоторое количество оценок, и мы знаем, что они соответствуют кривой нормального распределения. Тем не менее, нам не предоставили все оценки, только некую выборку.
Дело вот в чем:
Мы не знаем среднее значение или дисперсию всех оценок, но мы можем сделать предположение о них с помощью выборки. Правдоподобие — это вероятность того, что кривая нормального распределения с предполагаемыми средним значением и дисперсией приведет нас к этим оценкам.
Другими словами, можно предположить параметры, если у нас есть набор измеряемых результатов. Гипотетическая вероятность результатов при использовании этих предполагаемых параметров и называется правдоподобием.
Не забудьте, что это гипотетическая вероятность существующих оценок, а не вероятность будущих оценок.
Вам, наверное, интересно, чем же тогда является вероятность?
Снова возвращаясь к примеру с кривой нормального распределения, предположим, что мы знаем среднее значение и дисперсию. Мы также знаем, что оценки соответствуют кривой нормального распределения. То, как часто нам встретятся определенные оценки, и есть вероятность.
В общем, с учетом данных параметров, можно предположить, какой выйдет результат. Это то, в чем нам помогает вероятность.
Здорово! Тогда в чем разница между наблюдаемыми и ненаблюдаемыми данными? Наблюдаемые данные – это данные, которые у вас есть. Ненаблюдаемые данные – это недостающие данные. Данных может не быть по многим причинам (не учтены, проигнорированы и т.д.).
Соль вот в чем:
Для извлечения и кластеризации информации важно считать класс точек данных недостающими данными. Мы не знаем о классе, так что интерпретация недостающих данных таким образом имеет решающее значение для применения EM к задаче кластеризации.
Повторим: алгоритм EM итерирует и оптимизирует правдоподобие видения наблюдаемых данных при предположении параметров статистической модели с ненаблюдаемыми переменными. Будем надеяться, что этот способ вам теперь более понятен.
Лучше всего, что…
Оптимизируя правдоподобие, EM генерирует замечательную модель, которая присваивает классам точки данных. Как по мне, так это похоже на кластеризацию!
Как же EM помогает с кластеризацией? EM начинает с угадывания параметров модели.
Потом он вступает в следующий итеративный трехшаговый процесс:
- E-этап: на основании параметров модели вычисляются вероятности для присвоения значений каждой точки данных к кластеру.
- M-этап: обновляются параметры модели на основании кластерных присвоений из предыдущего шага.
- Повторять пока параметры модели и присвоения кластера стабилизируются (конвергенция).
Это обучение с учителем или без? Так как мы не предоставляем маркированную информацию класса, это обучение без учителя.
Почему стоит попробовать EM? Главным достоинством EM является простая и прямолинейная реализация. К тому же, он не только может оптимизировать параметры модели, но и многократно пытается угадывать недостающие данные.
Благодаря этому, он отлично подходит для кластеризации и создания модели с параметрами. Зная кластеры и параметры модели, можно рассуждать о том, что у кластеров общего и к какому кластеру принадлежат новые данные.
У EM все же есть недостатки…
- EM быстр на ранних итерациях, но становится медленнее в последующих.
- EM не всегда находит оптимальные параметры и застревает в локальных оптимумах, а не в глобальных оптимумах.
Где он используется? Алгоритм EM доступен в Weka. У R есть реализация в пакете mclust. scikit-learn также использует его в модуле gmm.
Какой метод добычи данных использует Google? Давайте посмотрим…
6.PageRank
Что он делает? PageRank является алгоритмом ссылочного ранжирования, разработанным для определения относительной «важности» какого-либо объекта в сети объектов.
Мда… Что такое ссылочное ранжирование? Это тип анализа сетей, исследующий связи (ссылки) между объектами.
Вот вам пример: поисковик Google. Несмотря на то, что их поисковая система не полагается исключительно на PageRank, это все же один из способов, который Google использует для определения важности веб-страницы.
Позвольте объяснить:
Веб-страницы во всемирной паутине ссылаются друг на друга. Если на tproger.ru есть ссылка на CNN, ему начисляется «голос», обозначающий, что tproger.ru считает веб-страницу CNN актуальной.
Но это не все
Голоса tproger.ru в свою очередь меряются по авторитетности и актуальности самого tproger.ru. Другими словами, любая веб-страница, проголосовавшая за tproger.ru, повышает его актуальность.
Итог?
Такая концепция голосования и актуальности и есть PageRank. Голос tproger.ru за CNN увеличивает PageRank CNN, и авторитетность tproger.ru влияет на то, как сильно этот голос влияет на PageRank CNN.
Что означает PageRank 0, 1, 2, 3 и т.д.? Хотя точное значение числа PageRank Google не разглашает, мы можем получить представление о его примерном значении.
Вот он и есть:

Это что-то вроде рейтинга популярности. У нас у всех есть представление о том, какие сайты актуальны и популярны. PageRank – это просто очень элегантный способ это определить.
Где еще применяется PageRank? PageRank был разработан специально для всемирной паутины.
Подумайте, по своей сути, PageRank – это просто очень эффективный способ анализа ссылок. Объекты, связанные друг с другом, не обязаны быть веб-страницами.
Вот 3 инновационных применения PageRank:
- Доктор наук Стефано Аллесина (Dr. Stefano Allesina) из университета Чикаго применил PageRank к экологии, чтобы определить, какие виды имеют решающее значение для поддержки экосистемы.
- Твиттер разработал WTF (Who-to-Follow, кого-стоит-читать), который по сути является персонализированной системой рекомендаций PageRank о том, кого стоит читать в Твиттере.
- Бен Цзян (Bin Jiang) из Гонконгского политехнического университета использовал версию PageRank, чтобы предсказать скорость передвижения людей в Лондоне на основе топографических показателей.
Это обучение с учителем или без? PageRank, как правило, считается самообучающимся алгоритмом, так как он часто используется для обнаружения важности и актуальности веб-страницы.
Почему стоит попробовать PageRank? Пожалуй, главным преимуществом PageRank является его устойчивость, ибо получение соответствующей входящей ссылки достаточно трудно.
Проще говоря:
Если у вас есть график или сеть, и вы хотите узнать их относительную важность, рейтинг или актуальность, вам стоит попробовать PageRank.
Где он используется? Товарный знак PageRank принадлежит Google. Тем не менее, алгоритм на самом деле запатентован Стэнфордским университетом.
Вам наверное интересно, имеете ли вы право пользоваться PageRank.
Я не юрист, так что лучше всего вам проконсультироваться с настоящим юристом, но вы скорее всего можете использовать алгоритм, если он не конкурирует коммерчески с Google или Стэнфордом.
Вот 3 реализации PageRank:
- C++ OpenSource PageRank Implementation
- Python PageRank Implementation
- igraph – Пакет анализа сетей (R)
7. AdaBoost
Что он делает? AdaBoost — это алгоритм усиления классификаторов.
Как вы, наверное, помните, классификатор принимает некоторое количество данных и пытается предсказать или классифицировать, к какому классу принадлежит новый элемент данных.
Что такое усиление? Усиление — это агрегация алгоритмов обучения, которая берет несколько алгоритмов обучения (например, деревья решений) и объединяет их. Цель в том, чтобы взять агрегацию или группу слабых учеников и объединить их для создания одного сильного ученика.
Каково различие между сильным и слабым учеником? Слабый ученик классифицирует с точностью только чуть выше случайности. Известным примером слабого ученика является одноуровневое дерево решений.
С другой стороны…
У сильного ученика точность намного выше, и часто используемым примером сильного ученика является SVM.
Можно привести пример AdaBoost? Давайте начнем с трех слабых учеников. Мы обучим их в 10 раундов на учебном наборе данных, содержащем данные о пациентах. Набор данных содержит подробную информацию о медицинских записях пациента.
Как бы нам предсказать, получит ли пациент рак?
Вот как AdaBoost отвечает на этот вопрос…
В первом раунде: AdaBoost берет образец учебного набора и тестирует его, чтобы увидеть насколько точен каждый ученик. В результате мы находим лучшего ученика.
Кроме того, неправильно классифицированным образцам присваивается больший вес, чтобы у них был более высокий шанс быть выбранными в следующий раунд.
Еще кое-что: лучшему ученику тоже присваивается вес, полагаясь на его точность, и его включают в агрегацию учеников (сейчас есть только один ученик).
Во втором раунде: AdaBoost снова пытается найти лучшего ученика.
И соль вот в чем:
Образец данных пациента для тренировки теперь находится под влиянием в большей степени неправильно классифицированных образцов. Другими словами, у ранее неправильно классифицированного пациента появляется более высокий шанс появиться в образце.
Почему?
Это что-то вроде “сохранения” в видеоиграх, когда тебе не приходится начинать игру с самого начала, когда твоего персонажа убивают. Вместо этого ты можешь сосредоточить все свои усилия на том, чтобы перейти на следующий уровень.
Кроме того, первый ученик, скорее всего, классифицировал некоторых пациентов правильно. Вместо того, чтоб классифицировать их снова, все усилия сосредоточены на классификации ранее неправильно классифицированных пациентов.
Лучшему ученику снова присваивается вес и его включают в агрегацию; неправильно классифицированным пациентам присваивается вес таким образом, что у них больше шансов быть выбранными. И все это повторяется снова.
По окончании десяти раундов: у нас теперь есть агрегация учеников, тренированных и повторно тренированных на неправильно классифицированных данных из предыдущих раундов.
Это обучение с учителем или без? Это обучение с учителем, так как каждая итерация тренирует слабых учеников имеющимся набором данных.
Почему стоит использовать AdaBoost? AdaBoost прост. Алгоритм достаточно легко реализовать.
Вдобавок, он очень быстр! Слабые ученики обычно намного проще сильных. То, что они проще, означает что они, вероятно, быстрее выполняются.
Еще кое-что…
Это очень элегантный способ автонастройки классификатора, так как в каждый последующий раунд AdaBoost уточняет значимость для каждого из лучших учеников. Все, что вам нужно указать — это количество раундов.
Наконец, он гибок и универсален. AdaBoost может включить в себя любой алгоритм обучения, и он может работать с очень разнообразными данными.
Где он используется? У AdaBoost есть очень много реализаций и вариаций. Вот несколько из них:
Если вам нравится сериал про мистера Роджерса, вам понравится следующий алгоритм…
8. kNN
Что он делает? kNN, или k ближайших соседей — алгоритм для классификации. Однако он отличается от ранее описанных классификаторов тем, что он является ленивым учеником.
Что такое ленивый ученик? Ленивый ученик особо ничего не делает во время процесса обучения, кроме сохранения данных обучения. Этот тип ученика классифицирует только тогда, когда введены новые немаркированные данные.
С другой стороны, старательный ученик строит модель классификации во время обучения. Когда вводятся новые немаркированные данные, этот тип ученика передает данные в модель классификации.
Что насчет C4.5, SVM и AdaBoost? Они все являются старательными учениками.
Вот почему:
- C4.5 строит дерево решений во время обучения.
- SVM создает модель классификации в виде гиперплоскости во время обучения.
- AdaBoost cоздает агрегацию моделей классификации во время обучения.
Так что же делает kNN? kNN не создает таких моделей классификации. Вместо этого, он просто хранит маркированные данные.
Когда вводятся новые немаркированные данные, kNN делает вот что:
- Сначала он смотрит на k ближайших маркированных точек данных. Другими словами, на k ближайших соседей.
- Потом, используя классы соседей, kNN получает лучшее представление о том, как новые данные должны быть классифицированы.
Вы, наверное, задаетесь следующим вопросом…
Как kNN выясняет, что находится ближе? Для непрерывных данных, kNN использует функцию дистанции, например, дистанцию в евклидовом пространстве. Выбор функции дистанции в значительной степени зависит от данных. Кто-то даже предлагает определять функции дистанции, основываясь на данных обучения. Есть огромное количество работ о функции дистанции kNN.
Идея в том, чтобы преобразовать дискретные данные в непрерывные. Вот два примера:
- Использование расстояния Хэмминга для метрики «близости» двух текстовых строк.
- Преобразование дискретных данных в двоичные функции.
В этих двух тредах Stack Overflow вы найдете больше предложений для работы с дискретными данными:
А как kNN классифицирует новые данные, когда соседи противоречат друг другу? kNN достаточно легко справляется, когда все соседи одного класса. Можно предположить, что в этом случае новые данные с большой вероятностью попадут в этот же класс.
Могу поспорить, что вы можете угадать, в каком случае все перестает быть таким простым…
Как же kNN определяет класс, когда у соседей он разный?
Есть два распространенных метода для борьбы с этим:
- Возьмите простое большинство голосов от соседей. Тот класс, у которого больше голосов, становится классом новой точки данных.
- Возьмите голоса, но задайте больший вес ближайшим соседям. Проще всего использовать взаимное расположение. Например, если сосед находится на расстоянии пяти единиц, то его вес его голоса — 1/5. Чем дальше сосед, тем взаимное расположение становится меньше и меньше… А это именно то, что нам надо!
Это обучение с учителем или без учителя? Это обучение с учителем, так как kNN предоставляется маркированный набор данных для обучения.
Почему стоит использовать kNN? Простота в понимании и реализации — главные причины для использования kNN. В зависимости от функции расстояния, kNN может быть достаточно точным.
Но это лишь одна сторона медали…
Вот пять вещей, которых стоит остерегаться:
- kNN может стать очень затратным в вычислениях, когда он пытается определить ближайших соседей в большом наборе данных.
- Неточные данные могут помешать правильной классификации.
- Свойства с большим диапазоном значений могут доминировать в функции расстояний относительно характеристик с меньшим диапазоном, так что выбор масштаба очень важен.
- Так как обработка данных откладывается, kNN обычно требует больше места для хранения, чем старательные классификаторы.
- Выбор подходящей функции расстояния имеет решающее значение для точности kNN.
Где он используется?
- MATLAB k-nearest neighbor classification
- scikit-learn KNeighborsClassifier
- k-Nearest Neighbour Classification in R
Спам? Забудьте о нем! Читайте дальше, чтобы узнать больше о следующем алгоритме…
9. Наивный байесовский классификатор
Что он делает? Наивный байесовский является не единым алгоритмом, а семейством алгоритмов классификации, которые разделяют одно общее предположение:
Каждое из свойств классифицируемых данных не зависит от всех других свойств.
Что имеется в виду под независимым? Два свойства являются независимыми, если их значение не имеет никакого влияния на значение другого свойства.
К примеру:
Скажем, у вас есть набор данных пациента с такими свойствами как пульс, уровень холестерина, вес, рост и почтовый индекс. Все свойства были бы независимыми, если бы их значения никак не влияли друг на друга. Для этого набора данных разумно предположить, что рост и почтовый индекс пациента являются независимыми, так как рост пациента никак не зависит от его почтового индекса.
А другие свойства независимы?
А сожалению, нет. Вот три взаимосвязанные свойства:
- Если увеличивается рост, вес вероятно тоже увеличится.
- Если увеличился уровень холестерина, то вес тоже, скорее всего, увеличился.
- Если увеличился уровень холестерина, то пульс тоже, скорее всего, увеличился.
По моему опыту, свойства набора данных чаще всего не являются независимыми.
И это приводит нас к следующему вопросу…
Почему он называется наивным? То предположение, что все особенности набора данных независимы, и является причиной того, что он назван наивным. Ибо чаще всего характеристики набора данных не независимы.
Кто такой Байес? Томас Байес был британским статистиком, в честь которого названа теорема Байеса. Вы можете узнать больше о теореме Байеса здесь.
В двух словах, теорема позволяет прогнозировать класс при данном наборе характеристик, используя вероятность.
Упрощенная формула для классификации выглядит примерно так:

Давайте немного углубимся в это…
Что представляет собой эта формула? Эта формула находит вероятность Класса А в зависимости от свойств 1 и 2. Другими словами, если вы видите Свойства 1 и 2, это и есть вероятность того, что данные принадлежат Классу А.
Уравнение гласит: вероятность Класса А, учитывая Свойства 1 и 2, является дробью.
- Числителем дроби является вероятность Свойства 1, в Классе А, умноженная на вероятность Свойства 2 в Классе А, умноженную на вероятность Класса А.
- Знаменателем дроби является вероятность Свойства 1, умноженного на вероятность Свойства 2.
Что является примером Наивного байесовского классификатора? Ниже отличный пример со Stack Overflow.
Итак:
- У нас есть учебный набор данных с 1000 фруктов.
- Фрукт может быть Бананом, Апельсином или Другим (это наши классы).
- Фрукт может быть Длинным, Сладким или Желтым (это наши свойства).
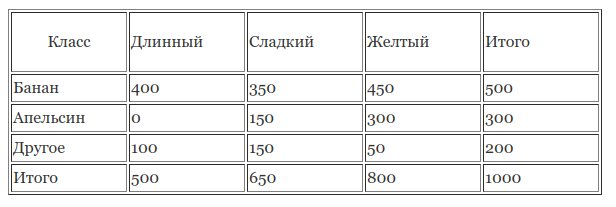
Что мы видим в учебном наборе данных?
- из 500 бананов, 400 длинных, 350 сладких и 450 желтых;
- из 300 апельсинов, 0 длинных, 150 сладкий и 300 желтых;
- из оставшихся 200 фруктов, 100 длинных, 150 сладких и 50 желтых.
Если нам даны длина, сладость и цвет фрукта (не зная его класс), мы теперь можем вычислить вероятность того, что это банан, апельсин или другой фрукт.
Предположим, мы знаем, что фрукт длинный, сладкий и желтый.
Вот как мы вычислим все вероятности в 4 этапа:
Этап 1: Вычисляем вероятность того, что это банан. Это вероятность класса Банан, учитывая свойства Длинный, Сладкий и Желтый, или в более лаконичной форме:
P(Банан| Длинный, Сладкий, Желтый)
Это идентично уравнению, обсуждавшемуся ранее.
Этап 2: Начиная с числителя, давайте вставим все в формулу.
- P(Длинный| Банан) = 400/500 = 0.8
- P(Сладкий| Банан) = 350/500 = 0.7
- P(Желтый| Банан) = 450/500 = 0.9
- P( Банан) = 500/1000 = 0.5
Перемножив все друг с другом (как в уравнении), мы получаем:
0.8 х 0.7 х 0.9 х 0.5 = 0.252
Этап 3: игнорируем знаменатель, так как он будет одинаковым для все других расчетов.
Этап 4: проводим похожие вычисления для всех других классов:
- P(Апельсин| Длинный, Сладкий, Желтый) = 0
- P(Другое| Длинный, Сладкий, Желтый) = 0.01875
Так как 0.252 больше 0.01875, Наивный Байесовский классифицирует этот длинный, сладкий и желтый фрукт как банан.
Это обучение с учителем или без? Это обучение с учителем, так как Наивному Байесовскому предоставляется маркированный учебный набор данных для создания таблиц.
Почему стоит использовать Наивный Байесовский классификатор? Как вы видите из выше представленного примера, Наивный Байесовский предполагает простую арифметику. Он просто сводится к подсчету, умножению и делению.
Как только таблицы частот рассчитаны, классифицирование неизвестного фрукта включает в себя лишь вычисление вероятностей для всех классов, а затем выбор наиболее вероятного класса.
Несмотря на его простоту, Наивный Байесовский классификатор может быть удивительно точным. К примеру, он был признан эффективным в фильтрации спама.
Где он используется? Реализацию Наивного Байесовского можно найти в Orange, scikit-learn, Weka и R.
Наконец, перейдем к десятому алгоритму…
10. CART
Что он делает? CART означает дерево классификации и регрессии (Classification and Regression Tree). Это метод обучения способом построения деревья решений, который выдает либо деревья классификации, либо регрессии. Как и C4.5, CART является классификатором.
Дерево классификации похоже на дерево решений? Дерево классификации является видом дерева решений. Выводом дерева классификаций является класс.
К примеру, имея набор данных пациента, вы можете попытаться предсказать, заболеет ли пациент раком или нет. Класс тогда будет либо «заболеет раком», либо «не заболеет раком».
Что такое дерево регрессий? В отличие от дерева классификаций, которое предсказывает класс, дерево регрессий предсказывает числовое или непрерывное значение. Например, время пребывания пациента в больнице или цену смартфона.
Вот простой способ запомнить…
Деревья классификаций выдают классы, а деревья регрессий — числа.
Так как мы уже обсудили, как деревья решений используются для классификации данных, давайте сразу перейдем к сути…
Как можно сравнить CART с C4.5?

Это обучение с учителем или без? CART – это метод обучения с учителем, так как ему дается маркированный учебный набор для создания модели деревьев классификации и регрессии.
Почему стоит использовать CART? Большинство причин, по которым вы бы стали использовать C4.5, так же применимы к CART, так как оба метода используют деревья решений. Легкость в интерпретации и понимании также являются преимуществами CART.
Как и C4.5, он достаточно быстрый, широко используемый, а вывод удобен для понимания человека.
Где он используется? scikit-learn реализует CART в его классификаторе деревья решений. Пакет деревьев R также имеет свою реализацию CART. Им также пользуются Weka и MATLAB.
Интересные ссылки
- Apriori algorithm for Data Mining – made simple
- What Is Google PageRank and How Is It Earned and Transferred?
- AdaBoost Tutorial
- Тонна литературы по теме
Теперь ваша очередь…
Вот я и поделился с вами о моим мнением об этих алгоритмах интеллектуального анализа данных, так что теперь ваш черед.
- Собираетесь ли вы теперь попробовать извлечение данных?
- О каких алгоритмах, не упомянутых в этой статье, вы знаете?
- Есть ли у вас какие-либо вопросы?
Оставьте комментарий и поделитесь своим мнением.
Перевод статьи «Top 10 data mining algorithms in plain english»

30К открытий32К показов

Разработчик изучил рекомендательную систему Netflix: как алгоритмы и инфраструктура персонализируют контент и удерживают зрителей

Самые лучшие курсы по Big Data. В предложенной подборке актуальные варианты обучения от проверенных школ, а так же рейтинги и цены на курсы для аналитиков Big Data

Разбираем, какие скилы и знания станут обязательными в 2026 году, что будут ценить работодатели и как новичку не потеряться на входе в ИТ-индустрию

О катастрофическом забывании: почему модели теряют навыки и что делать разработчикам