Обзор самых популярных алгоритмов машинного обучения
В машинном обучении существует множество разных алгоритмов, в которых порой не только новичку, но и профессионалу сложно разобраться. Представляем вашему вниманию краткий обзор топ-10 алгоритмов, с которых можно начать знакомство с машинным обучением.
Существует такое понятие, как «No Free Lunch» теорема. Её суть заключается в том, что нет такого алгоритма, который был бы лучшим выбором для каждой задачи, что в особенности касается обучения с учителем.
Например, нельзя сказать, что нейронные сети всегда работают лучше, чем деревья решений, и наоборот. На эффективность алгоритмов влияет множество факторов вроде размера и структуры набора данных.
По этой причине приходится пробовать много разных алгоритмов, проверяя эффективность каждого на тестовом наборе данных, и затем выбирать лучший вариант. Само собой, нужно выбирать среди алгоритмов, соответствующих вашей задаче. Если проводить аналогию, то при уборке дома вы, скорее всего, будете использовать пылесос, метлу или швабру, но никак не лопату.
Алгоритмы машинного обучения можно описать как обучение целевой функции f, которая наилучшим образом соотносит входные переменные X и выходную переменную Y: Y = f(X).
Мы не знаем, что из себя представляет функция f. Ведь если бы знали, то использовали бы её напрямую, а не пытались обучить с помощью различных алгоритмов.
Наиболее распространённой задачей в машинном обучении является предсказание значений Y для новых значений X. Это называется прогностическим моделированием, и наша цель — сделать как можно более точное предсказание.
Представляем вашему вниманию краткий обзор топ-10 популярных алгоритмов, используемых в машинном обучении.
1. Линейная регрессия
Линейная регрессия — пожалуй, один из наиболее известных и понятных алгоритмов в статистике и машинном обучении.
Прогностическое моделирование в первую очередь касается минимизации ошибки модели или, другими словами, как можно более точного прогнозирования. Мы будем заимствовать алгоритмы из разных областей, включая статистику, и использовать их в этих целях.
Линейную регрессию можно представить в виде уравнения, которое описывает прямую, наиболее точно показывающую взаимосвязь между входными переменными X и выходными переменными Y. Для составления этого уравнения нужно найти определённые коэффициенты B для входных переменных.
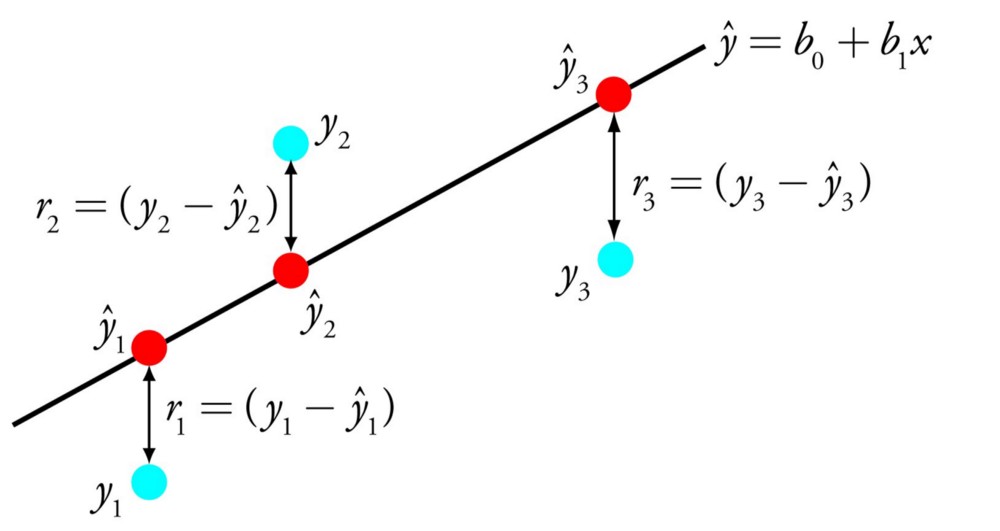
Например: Y = B0 + B1 * X
Зная X, мы должны найти Y, и цель линейной регрессии заключается в поиске значений коэффициентов B0 и B1.
Для оценки регрессионной модели используются различные методы вроде линейной алгебры или метода наименьших квадратов.
Линейная регрессия существует уже более 200 лет, и за это время её успели тщательно изучить. Так что вот пара практических правил: уберите похожие (коррелирующие) переменные и избавьтесь от шума в данных, если это возможно. Линейная регрессия — быстрый и простой алгоритм, который хорошо подходит в качестве первого алгоритма для изучения.
2 . Логистическая регрессия
Логистическая регрессия — ещё один алгоритм, пришедший в машинное обучение прямиком из статистики. Её хорошо использовать для задач бинарной классификации (это задачи, в которых на выходе мы получаем один из двух классов).
Логистическая регрессия похожа на линейную тем, что в ней тоже требуется найти значения коэффициентов для входных переменных. Разница заключается в том, что выходное значение преобразуется с помощью нелинейной или логистической функции.
Логистическая функция выглядит как большая буква S и преобразовывает любое значение в число в пределах от 0 до 1. Это весьма полезно, так как мы можем применить правило к выходу логистической функции для привязки к 0 и 1 (например, если результат функции меньше 0.5, то на выходе получаем 1) и предсказания класса.

Благодаря тому, как обучается модель, предсказания логистической регрессии можно использовать для отображения вероятности принадлежности образца к классу 0 или 1. Это полезно в тех случаях, когда нужно иметь больше обоснований для прогнозирования.
Как и в случае с линейной регрессией, логистическая регрессия выполняет свою задачу лучше, если убрать лишние и похожие переменные. Модель логистической регрессии быстро обучается и хорошо подходит для задач бинарной классификации.
3. Линейный дискриминантный анализ (LDA)
Логистическая регрессия используется, когда нужно отнести образец к одному из двух классов. Если классов больше, чем два, то лучше использовать алгоритм LDA (Linear discriminant analysis).
Представление LDA довольно простое. Оно состоит из статистических свойств данных, рассчитанных для каждого класса. Для каждой входной переменной это включает:
- Среднее значение для каждого класса;
- Дисперсию, рассчитанную по всем классам.
Предсказания производятся путём вычисления дискриминантного значения для каждого класса и выбора класса с наибольшим значением. Предполагается, что данные имеют нормальное распределение, поэтому перед началом работы рекомендуется удалить из данных аномальные значения. Это простой и эффективный алгоритм для задач классификации.
4. Деревья принятия решений
Дерево решений можно представить в виде двоичного дерева, знакомого многим по алгоритмам и структурам данных. Каждый узел представляет собой входную переменную и точку разделения для этой переменной (при условии, что переменная — число).
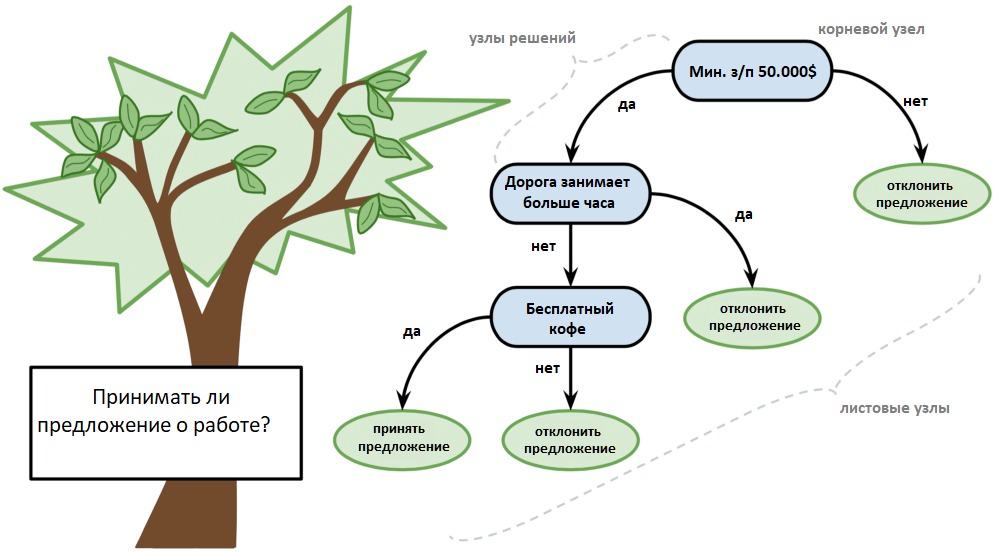
Листовые узлы — это выходная переменная, которая используется для предсказания. Предсказания производятся путём прохода по дереву к листовому узлу и вывода значения класса на этом узле.
Деревья быстро обучаются и делают предсказания. Кроме того, они точны для широкого круга задач и не требуют особой подготовки данных.
5 . Наивный Байесовский классификатор
Наивный Байес — простой, но удивительно эффективный алгоритм.
Модель состоит из двух типов вероятностей, которые рассчитываются с помощью тренировочных данных:
- Вероятность каждого класса.
- Условная вероятность для каждого класса при каждом значении x.
После расчёта вероятностной модели её можно использовать для предсказания с новыми данными при помощи теоремы Байеса. Если у вас вещественные данные, то, предполагая нормальное распределение, рассчитать эти вероятности не составляет особой сложности.
Наивный Байес называется наивным, потому что алгоритм предполагает, что каждая входная переменная независимая. Это сильное предположение, которое не соответствует реальным данным. Тем не менее данный алгоритм весьма эффективен для целого ряда сложных задач вроде классификации спама или распознавания рукописных цифр.
6. K-ближайших соседей (KNN)
К-ближайших соседей — очень простой и очень эффективный алгоритм. Модель KNN (K-nearest neighbors) представлена всем набором тренировочных данных. Довольно просто, не так ли?
Предсказание для новой точки делается путём поиска K ближайших соседей в наборе данных и суммирования выходной переменной для этих K экземпляров.
Вопрос лишь в том, как определить сходство между экземплярами данных. Если все признаки имеют один и тот же масштаб (например, сантиметры), то самый простой способ заключается в использовании евклидова расстояния — числа, которое можно рассчитать на основе различий с каждой входной переменной.
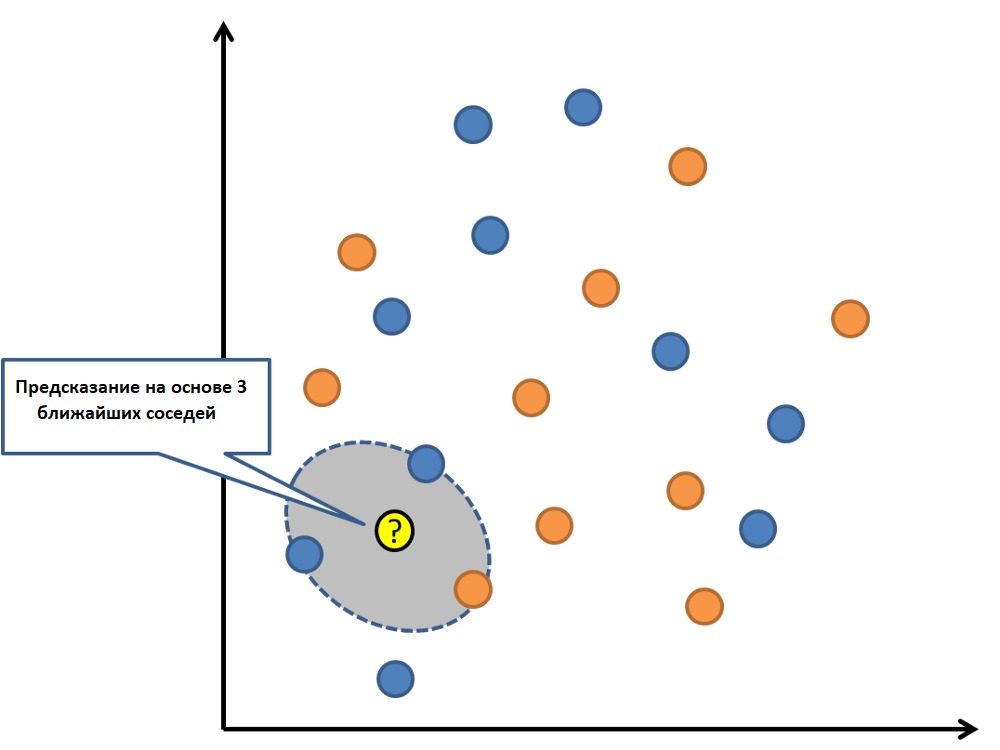
KNN может потребовать много памяти для хранения всех данных, но зато быстро сделает предсказание. Также обучающие данные можно обновлять, чтобы предсказания оставались точными с течением времени.
Идея ближайших соседей может плохо работать с многомерными данными (множество входных переменных), что негативно скажется на эффективности алгоритма при решении задачи. Это называется проклятием размерности. Иными словами, стоит использовать лишь наиболее важные для предсказания переменные.
7 . Сети векторного квантования (LVQ)
Недостаток KNN заключается в том, что нужно хранить весь тренировочный набор данных. Если KNN хорошо себя показал, то есть смысл попробовать алгоритм LVQ (Learning vector quantization), который лишён этого недостатка.

LVQ представляет собой набор кодовых векторов. Они выбираются в начале случайным образом и в течение определённого количества итераций адаптируются так, чтобы наилучшим образом обобщить весь набор данных. После обучения эти вектора могут использоваться для предсказания так же, как это делается в KNN. Алгоритм ищет ближайшего соседа (наиболее подходящий кодовый вектор) путём вычисления расстояния между каждым кодовым вектором и новым экземпляром данных. Затем для наиболее подходящего вектора в качестве предсказания возвращается класс (или число в случае регрессии). Лучшего результата можно достичь, если все данные будут находиться в одном диапазоне, например от 0 до 1.
8. Метод опорных векторов (SVM)
Метод опорных векторов, вероятно, один из наиболее популярных и обсуждаемых алгоритмов машинного обучения.
Гиперплоскость — это линия, разделяющая пространство входных переменных. В методе опорных векторов гиперплоскость выбирается так, чтобы наилучшим образом разделять точки в плоскости входных переменных по их классу: 0 или 1. В двумерной плоскости это можно представить как линию, которая полностью разделяет точки всех классов. Во время обучения алгоритм ищет коэффициенты, которые помогают лучше разделять классы гиперплоскостью.
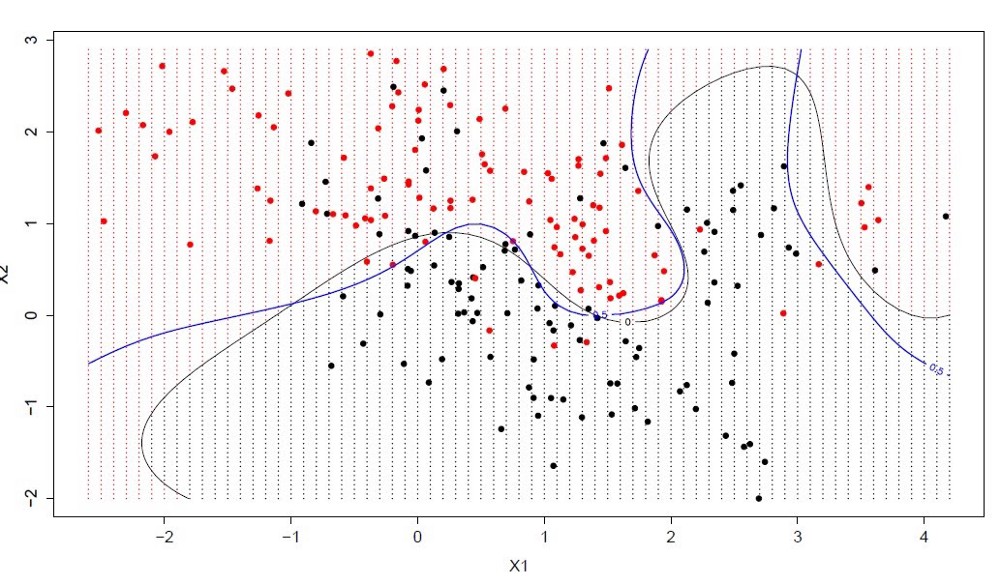
Расстояние между гиперплоскостью и ближайшими точками данных называется разницей. Лучшая или оптимальная гиперплоскость, разделяющая два класса, — это линия с наибольшей разницей. Только эти точки имеют значение при определении гиперплоскости и при построении классификатора. Эти точки называются опорными векторами. Для определения значений коэффициентов, максимизирующих разницу, используются специальные алгоритмы оптимизации.
Метод опорных векторов, наверное, один из самых эффективных классических классификаторов, на который определённо стоит обратить внимание.
9 . Бэггинг и случайный лес
Случайный лес — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом.
Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения.
В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению.

В алгоритме случайного леса для всех выборок из тренировочных данных строятся деревья решений. При построении деревьев для создания каждого узла выбираются случайные признаки. В отдельности полученные модели не очень точны, но при их объединении качество предсказания значительно улучшается.
Если алгоритм с высокой дисперсией, например, деревья решений, показывает хороший результат на ваших данных, то этот результат зачастую можно улучшить, применив бэггинг.
10 . Бустинг и AdaBoost
Бустинг — это семейство ансамблевых алгоритмов, суть которых заключается в создании сильного классификатора на основе нескольких слабых. Для этого сначала создаётся одна модель, затем другая модель, которая пытается исправить ошибки в первой. Модели добавляются до тех пор, пока тренировочные данные не будут идеально предсказываться или пока не будет превышено максимальное количество моделей.
AdaBoost был первым действительно успешным алгоритмом бустинга, разработанным для бинарной классификации. Именно с него лучше всего начинать знакомство с бустингом. Современные методы вроде стохастического градиентного бустинга основываются на AdaBoost.
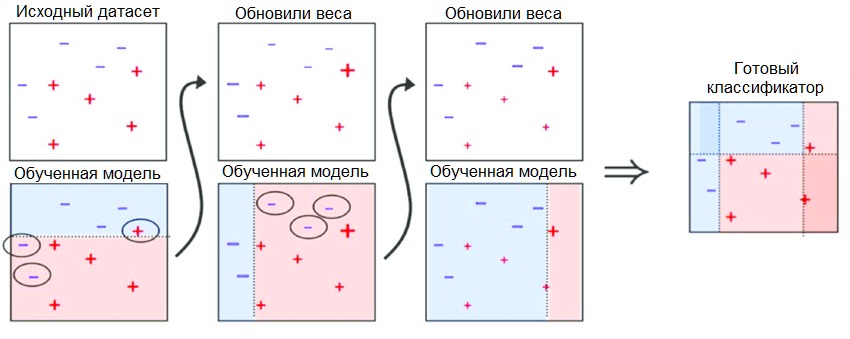
AdaBoost используют вместе с короткими деревьями решений. После создания первого дерева проверяется его эффективность на каждом тренировочном объекте, чтобы понять, сколько внимания должно уделить следующее дерево всем объектам. Тем данным, которые сложно предсказать, даётся больший вес, а тем, которые легко предсказать, — меньший. Модели создаются последовательно одна за другой, и каждая из них обновляет веса для следующего дерева. После построения всех деревьев делаются предсказания для новых данных, и эффективность каждого дерева определяется тем, насколько точным оно было на тренировочных данных.
Так как в этом алгоритме большое внимание уделяется исправлению ошибок моделей, важно, чтобы в данных отсутствовали аномалии.
Пара слов напоследок
Когда новички видят всё разнообразие алгоритмов, они задаются стандартным вопросом: «А какой следует использовать мне?» Ответ на этот вопрос зависит от множества факторов:
- Размер, качество и характер данных;
- Доступное вычислительное время;
- Срочность задачи;
- Что вы хотите делать с данными.
Даже опытный data scientist не скажет, какой алгоритм будет работать лучше, прежде чем попробует несколько вариантов. Существует множество других алгоритмов машинного обучения, но приведённые выше — наиболее популярные. Если вы только знакомитесь с машинным обучением, то они будут хорошей отправной точкой.


