Создаём политического Twitter-бота с помощью Node.js и StdLib

Автоматизация правит миром. Разбираемся, как, используя цепи Маркова, на основе двух существующих аккаунтов, сделать самообучающегося Twitter-бота.

В мире политики пропаганда — это незаменимое оружие на поединке, где Twitter выступает в роли ринга, а Twitter-боты — читы, которые дают участнику превосходство. У команды StdLib нет политических мотивов, но есть страсть — создавать ботов. Джейден Трюдо, эксцентричный «кандидат» в премьер-министры Канады, — их новый проект, с которым легко ознакомиться при помощи сервиса StdLib Sourcecode. И подобное чудо инженерии создаётся в считанные минуты!
Twitter-бот обращается к народным массам, поэтому для создания идеального политика было решено совместить мудрость Джейдена Смитта:
Примечание переводчика «Я Постоянно Строю Пирамиды».
и нравственность Джастина Трюдо:
Примечание переводчика «Желаю Супер Хэллоуина!»
Если точнее, то целью было создать бота, который периодически публикует в Twitter сообщения в стиле Джейдена Смитта и Джастина Трюдо. В результате такой комбинации получаются чудесные твиты вроде:
Примечание переводчика «Я — Верховный Судья Утончённости».
Этот проект реализован с помощью цепей Маркова, которые также используются в алгоритме ранжирования страниц Google. На сайте StdLib программа доступна для тестирования через API и непосредственно со страницы сайта. Перед запуском в параметрах можно указать другие Twitter-аккаунты, чтобы при создании записей использовать их.

Определение цепи Маркова
Чарльз Гринстед и Лори Снелл в книге «Introduction to Probability» описывают цепь Маркова как набор состояний S = {s_1, s_2, ..., s_r}. Процесс начинается в одном из этих состояний и последовательно двигается из одного в другое. Каждое перемещение называется шагом. Если цепь размещена в состоянии s_i, то потом переместится в s_j с вероятностью p_ij. Эта вероятность не зависит от состояний, в которых цепь уже побывала.
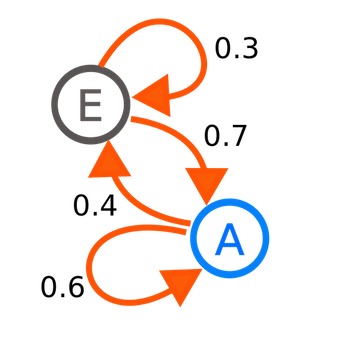
Цепь Маркова — это математическая модель, которая переходит из одного состояния в другое, не сохраняет информацию о предыдущих состояниях и обрабатывает только текущее состояние. Рассмотрим это определение на примере генератора текста:
- Разделяем корпус (текст) на звенья (слова и знаки препинания).
- Строим таблицу частот. Для каждого уникального звена в корпусе задаём ключ: каждому ключевому слову соответствует список слов, которые следуют за ним, с указанием частоты. Для начала и конца предложения устанавливаются специальные ключи. Это гарантирует, что сформированные предложения будут начинаться и заканчиваться приемлемыми словами.
- Выбираем точку отсчёта — специальное начальное звено.
- Находим случайным образом новое звено, следующее в таблице частот за предыдущим. Вероятность выбора каждого звена должна быть пропорциональна тому, как часто оно встречается после ключевого звена. Выбранное звено становится новым состоянием цепи Маркова. Повторяем этот пункт необходимое количество раз.
Примечание переводчика Наглядно эти принципы описаны в нашей статье о создании генератора текста на основе цепей Маркова.
Реализация
Теперь, когда появилось представление о дальнейших действиях, пора приступать. Сначала обработаем твиты. Это легко сделать с помощью пакета Twit.
Преобразуем полученные данные в массив цепей. Для этого убираем из твитов лишнее (URL-адреса, смайлики, неправильно построенные предложения) и разбиваем их на слова, из которых формируется таблица частот.
Записи таблицы частот могут быть обработаны по-разному. В начале, с вероятностью 50/50 слова вроде «our» («наш») или «we» («мы») будут выбраны как специальные начальные слова. Предположим, что выбрано слово «our». Тогда с вероятностью 2/5 будут выбраны слова «future» («будущее») или «differences» («различия») и вероятностью 1/5 — «relationship» («отношения»). Процесс повторяется до тех пор, пока не будет создана цепочка вроде такой:
Готово. Результат работы скрипта доступен в Twitter на странице Джейден Трюдо, а полный исходный код на странице GitHub. Конечно, возможна установка дополнительных опций. Например, для формирования нескольких предложений за раз требуется добавить границы с __END до __START и убедиться, что предложение закончено.
Я построю своего политического бота!
Для желающих написать Twitter-бота самостоятельно исходный код размещен на сайте StdLib. На странице по ссылке есть возможность даже развернуть бота непосредственно через браузер!
1. Нажимаем кнопку «Create Service from Source» («Создать службу из источника») и заполняем форму:

Первое поле — токен библиотеки StdLib, который оставляем без изменений. Остальные четыре находим на странице управления приложениями Twitter.
2. Нажимаем кнопку «Create New App» («Создать новое приложение») и заполняем форму:

3. Нажимаем кнопку «Create» («Создать») и на экране видим четыре ключа.
4. Копируем ключи в форму и нажимаем кнопку «Deploy» («Развернуть»).
5. Чтобы увидеть код локально и внести изменения нужен CLI, который установим с помощью NPM, выполнив команду в терминале:
6. Создаём рабочее пространство StdLib и получаем код, развёрнутый на предыдущем шаге:
7. По умолчанию бот использует цепи Маркова для формирования твитов. Чтобы переключить на другой метод, открываем файл __main__.js:
В 12-й строке изменяем вызываемую функцию lib.steve[twitter-markov-chain] на свою.
8. Собираем бота заново, выполнив команду:
Бот готов! Политический бот — это лишь одно из возможных применений описанных технологий: цепей Маркова, библиотеки StdLib и создания Twitter-бота.

7К открытий7К показов
Хотите в Data Science, но не знаете, какое направление выбрать? Собрали признаки, которые помогут определиться и выбрать профессию.

Рассказали, как инструменты на базе нейросетей работают и помогают разработчикам игр как с рутинными, так и с комплексными задачами.

Советы выпускника онлайн-университета для тех, кто хочет извлечь из учебы как можно больше и дойти до конца.

Исследование показало, что помощники, такие как Copilot, пишут код, который по качеству похож на «хаотичную работу неопытного аутсорсера».