15 полезных команд PostgreSQL
В сети много руководств по PostgreSQL, которые описывают основные команды. Но при погружении в работу возникают такие практические вопросы, для которых требуются продвинутые команды. Рассмотрим несколько таких команд на примерах, полезных как для разработчиков, так и для администраторов баз данных.

В сети много руководств по PostgreSQL, которые описывают основные команды. Но при погружении глубже в работу возникают такие практические вопросы, для которых требуются продвинутые команды.
Такие команды, или сниппеты, редко описаны в документации. Рассмотрим несколько на примерах, полезных как для разработчиков, так и для администраторов баз данных.
Получение информации о базе данных
Размер базы данных
Чтобы получить физический размер файлов (хранилища) базы данных, используем следующий запрос:
Результат будет представлен как число вида 41809016.
current_database() — функция, которая возвращает имя текущей базы данных. Вместо неё можно ввести имя текстом:
Для того, чтобы получить информацию в человекочитаемом виде, используем функцию pg_size_pretty:
В результате получим информацию вида 40 Mb.
Перечень таблиц
Иногда требуется получить перечень таблиц базы данных. Для этого используем следующий запрос:
information_schema — стандартная схема базы данных, которая содержит коллекции представлений (views), таких как таблицы, поля и т.д. Представления таблиц содержат информацию обо всех таблицах баз данных.
Запрос, описанный ниже, выберет все таблицы из указанной схемы текущей базы данных:
В последнем условии IN можно указать имя определенной схемы.
Размер таблицы
По аналогии с получением размера базы данных размер данных таблицы можно вычислить с помощью соответствующей функции:
Функция pg_relation_size возвращает объём, который занимает на диске указанный слой заданной таблицы или индекса.
Имя самой большой таблицы
Для того, чтобы вывести список таблиц текущей базы данных, отсортированный по размеру таблицы, выполним следующий запрос:
Для того, чтобы вывести информацию о самой большой таблице, ограничим запрос с помощью LIMIT:
relname — имя таблицы, индекса, представления и т.п.relpages — размер представления этой таблицы на диске в количествах страниц (по умолчанию одна страницы равна 8 Кб).pg_class — системная таблица, которая содержит информацию о связях таблиц базы данных.
Перечень подключенных пользователей
Чтобы узнать имя, IP и используемый порт подключенных пользователей, выполним следующий запрос:
Активность пользователя
Чтобы узнать активность соединения конкретного пользователя, используем следующий запрос:
Работа с данными и полями таблиц
Удаление одинаковых строк
Если так получилось, что в таблице нет первичного ключа (primary key), то наверняка среди записей найдутся дубликаты. Если для такой таблицы, особенно большого размера, необходимо поставить ограничения (constraint) для проверки целостности, то удалим следующие элементы:
- дублирующиеся строки,
- ситуации, когда одна или более колонок дублируются (если эти колонки предполагается использовать в качестве первичного ключа).
Рассмотрим таблицу с данными покупателей, где задублирована целая строка (вторая по счёту).
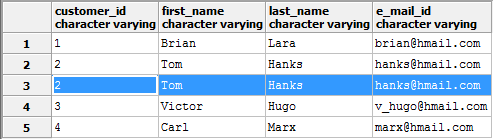
Удалить все дубликаты поможет следующий запрос:
Уникальное для каждой записи поле ctid по умолчанию скрыто, но оно есть в каждой таблице.
Последний запрос требователен к ресурсам, поэтому будьте аккуратны при его выполнении на рабочем проекте.
Теперь рассмотрим случай, когда повторяются значения полей.
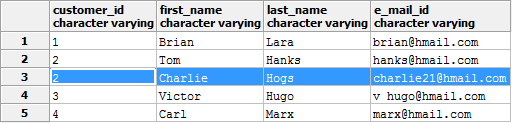
Если допустимо удаление дубликатов без сохранения всех данных, выполним такой запрос:
Если данные важны, то сначала нужно найти записи с дубликатами:

Перед удалением такие записи можно перенести во временную таблицу или заменить в них значение customer_id на другое.
Общая форма запроса на удаление описанных выше записей выглядит следующим образом:
Безопасное изменение типа поля
Может возникнуть вопрос о включении в этот список такой задачи. Ведь в PostgreSQL изменить тип поля очень просто с помощью команды ALTER. Давайте для примера снова рассмотрим таблицу с покупателями.
Для поля customer_id используется строковый тип данных varchar. Это ошибка, так как в этом поле предполагается хранить идентификаторы покупателей, которые имеют целочисленный формат integer. Использование varchar неоправданно. Попробуем исправить это недоразумение с помощью команды ALTER:
Но в результате выполнения получим ошибку:
Это значит, что нельзя просто так взять и изменить тип поля при наличии данных в таблице. Так как использовался тип varchar, СУБД не может определить принадлежность значения к integer. Хотя данные соответствуют именно этому типу. Для того, чтобы уточнить этот момент, в сообщении об ошибке предлагается использовать выражение USING, чтобы корректно преобразовать наши данные в integer:
В результате всё прошло без ошибок:

Обратите внимание, что при использовании USING кроме конкретного выражения возможно использование функций, других полей и операторов.
Например, преобразуем поле customer_id обратно в varchar, но с преобразованием формата данных:
В результате таблица примет следующий вид:
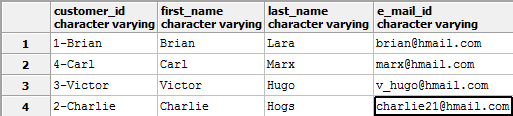
Поиск «потерянных» значений
Будьте внимательны при использовании последовательностей (sequence) в качестве первичного ключа (primary key): при назначении некоторые элементы последовательности случайно пропускаются, в результате работы с таблицей некоторые записи удаляются. Такие значения можно использовать снова, но найти их в больших таблицах сложно.

Рассмотрим два варианта поиска.
Первый способ
Выполним следующий запрос, чтобы найти начало интервала с «потерянным» значением:
В результате получим значения: 5, 9 и 11.
Если нужно найти не только первое вхождение, а все пропущенные значения, используем следующий (ресурсоёмкий!) запрос:
В результате видим следующий результат: 5, 9 и 6.
Второй способ
Получаем имя последовательности, связанной с customer_id:
И находим все пропущенные идентификаторы:
Подсчёт количества строк в таблице
Количество строк вычисляется стандартной функцией count, но её можно использовать с дополнительными условиями.
Общее количество строк в таблице:
Количество строк при условии, что указанное поле не содержит NULL:
Количество уникальных строк по указанному полю:
Использование транзакций
Транзакция объединяет последовательность действий в одну операцию. Её особенность в том, что при ошибке в выполнении транзакции ни один из результатов действий не сохранится в базе данных.
Начнём транзакцию с помощью команды BEGIN.
Для того, чтобы откатить все операции, расположенные после BEGIN, используем команду ROLLBACK.
А чтобы применить — команду COMMIT.
Просмотр и завершение исполняемых запросов
Для того, чтобы получить информацию о запросах, выполним следующую команду:
Для того, чтобы остановить конкретный запрос, выполним следующую команду, с указанием id процесса (pid):
Для того, чтобы прекратить работу запроса, выполним:
Работа с конфигурацией
Поиск и изменение расположения экземпляра кластера
Возможна ситуация, когда на одной операционной системе настроено несколько экземпляров PostgreSQL, которые «сидят» на различных портах. В этом случае поиск пути к физическому размещению каждого экземпляра — достаточно нервная задача. Для того, чтобы получить эту информацию, выполним следующий запрос для любой базы данных интересующего кластера:
Изменим расположение на другое с помощью команды:
Но для того, чтобы изменения вступили в силу, требуется перезагрузка.
Получение перечня доступных типов данных
Получим перечень доступных типов данных с помощью команды:
typname — имя типа данных.typlen — размер типа данных.
Изменение настроек СУБД без перезагрузки
Настройки PostgreSQL находятся в специальных файлах вроде postgresql.conf и pg_hba.conf. После изменения этих файлов нужно, чтобы СУБД снова получила настройки. Для этого производится перезагрузка сервера баз данных. Понятно, что приходится это делать, но на продакшн-версии проекта, которым пользуются тысячи пользователей, это очень нежелательно. Поэтому в PostgreSQL есть функция, с помощью которой можно применить изменения без перезагрузки сервера:
Но, к сожалению, она применима не ко всем параметрам. В некоторых случаях для применения настроек перезагрузка обязательна.
Мы рассмотрели команды, которые помогут упростить работу разработчикам и администраторам баз данных, использующим PostgreSQL. Но это далеко не все возможные приёмы. Если вы сталкивались с интересными задачами, напишите о них в комментариях. Поделимся полезным опытом!




