Предположим, у вас есть простая задача — создать форму, которая даст пользователю возможность подписаться на e-mail оповещения. Разумеется, вам необходимо предотвратить ввод в эту форму всякого мусора, при этом не должно получаться так, чтобы валидный адрес вдруг был забракован системой.
Как же выглядит e-mail адрес? Интуитивно можно предположить, что так:
// Пример адреса:
johndoe@example.com
// В виде составных частей:
${MAILBOX}@${SUBDOMAIN}.${TLD}
// Регулярка, которую можно было бы использовать
[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+
Выглядит хорошо, но это совершенно не тот случай, когда стоит доверять интуиции. Доверять следует спецификации. А спецификация говорит нам следующее:
// Пропущен домен? Всё нормально, письмо уйдёт на локаль!
john-doe
// Да, это тоже валидно, но такого ящика не существует с вероятностью 99%
john-doe@com
// И это валидно, но доменов из одной буквы не существует
john-doe@example.c
// Оу, мы кажется забыли про субдомены. Мы же не можем просто забыть про .co.uk?
john@doe.example.com
// Да, IP адрес в качестве сервера это тоже нормально
john@[192.168.1.1]
// По спецификации подходит, но такой домен не может быть зарегистрирован
john@-doe.com
// А ещё можно делать так:
john.doe@example.com
// Но нельзя так:
john..doe@eaxmple.com
.john@example.com
john.@example.com
Конечно, и тут можно обойтись с помощью регулярного выражения:
Как вы будете проверять правильность этого монстра? Такие регулярные выражения переходят «из уст в уста» на форумах, и каждый добавляет в них функциональность до тех пор, пока работа с выражением становится невозможной. И это именно тот случай.
Я бы не сказал, что регулярные выражения такой длины эффективнее, чем другие методы. Чем длиннее выражение, тем дольше оно будет компилироваться (сравнение всегда происходит за O(n)).
С помощью регулярного выражения можно сделать только проверку на соответствие. Выполнить проверку на то, находится ли домен в чёрном списке, у вас уже, увы, не получится.
Давайте пойдём другим путём
Вот основа нашей проверки:
char[] input; // Строка, которую нужно проверить
int index = 0; // Итератор для input
char ch; // Текущий символ (input[index])
int state = 0; // Состояние проверки (-1 для ошибки)
while (index <= input.length && state != -1) {
if (index == input.length) {
ch = '\0'; // Символ, по которому проверка прекращается
}
else {
ch = input[index];
}
switch (state) {
// case 0: {...
}
index++;
}
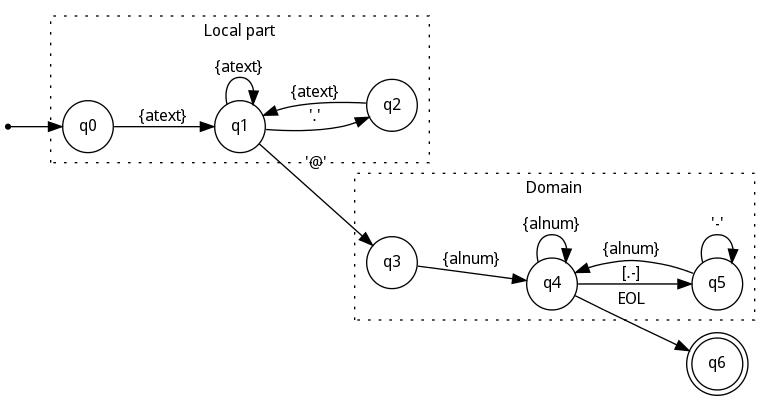
А вот диаграмма, описывающая алгоритм, по которому наша программа будет работать:
Если вы заметили, что тут не все правила соблюдаются — не волнуйтесь, мы вернёмся к этому позже. Если вы не заметили, и вообще не понимаете, что тут происходит, то сейчас объясню.
Вершина графа — состояние проверки. Ребро графа — прочитанный символ. Если в результате считывания символа невозможно перейти ни по одному ребру, значит, адрес не валиден. Вот, например, как будет реализована первая часть этого алгоритма:
case 0: {
if (ch >= 'a' && ch <= 'z') {
count++;
break; // State stays the same
}
if (ch == '\0') {
state = 1; // EOL
break;
}
state = -1; // Error
break;
}
Теперь о проверках, которые мы сделаем, после того, как код пройдёт по этой диаграмме:
public class Validator {
public static boolean isValid(final char[] input) {
int state = 0;
char ch;
int index = 0;
String local = null;
ArrayList<String> domain = new ArrayList<String>();
// Код проверки по диаграмме
// [..]
// Не прошло валидацию
if (state != 6)
return false;
// Домен должен быть по меньшей мере второго уровня
if (domain.size() < 2)
return false;
// RFC 5321 ограничивает длину имени ящика до 64 символов
if (local.length() > 64)
return false;
// RFC 5321 ограничивает длину адреса до 254 символов
if (input.length > 254)
return false;
// Доменная зона должна состоять только из букв и быть по меньше мере два символо длинной
index = input.length - 1;
while (index > 0) {
ch = input[index];
if (ch == '.' && input.length - index > 2) {
return true;
}
if (!((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))) {
return false;
}
index--;
}
return true;
}
}
Собираем всё вместе
public class EmailValidator {
public static boolean isValid(final char[] input) {
if (input == null) {
return false;
}
int state = 0;
char ch;
int index = 0;
int mark = 0;
String local = null;
ArrayList<String> domain = new ArrayList<String>();
while (index <= input.length && state != -1) {
if (index == input.length) {
ch = '\0'; // Так мы обозначаем конец нашей работы
}
else {
ch = input[index];
if (ch == '\0') {
// символ, которым мы кодируем конец работы, не может быть частью ввода
return false;
}
}
switch (state) {
case 0: {
// Первый символ {atext} -- текстовой части локального имени
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')
|| (ch >= '0' && ch <= '9') || ch == '_' || ch == '-'
|| ch == '+') {
state = 1;
break;
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 1: {
// Остальные символы {atext} -- текстовой части локального имени
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')
|| (ch >= '0' && ch <= '9') || ch == '_' || ch == '-'
|| ch == '+') {
break;
}
if (ch == '.') {
state = 2;
break;
}
if (ch == '@') { // Конец локальной части
local = new String(input, 0, index - mark);
mark = index + 1;
state = 3;
break;
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 2: {
// Переход к {atext} (текстовой части) после точки
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')
|| (ch >= '0' && ch <= '9') || ch == '_' || ch == '-'
|| ch == '+') {
state = 1;
break;
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 3: {
// Переходим {alnum} (домену), проверяем первый символ
if ((ch >= 'a' && ch <= 'z') || (ch >= '0' && ch <= '9')
|| (ch >= 'A' && ch <= 'Z')) {
state = 4;
break;
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 4: {
// Собираем {alnum} --- домен
if ((ch >= 'a' && ch <= 'z') || (ch >= '0' && ch <= '9')
|| (ch >= 'A' && ch <= 'Z')) {
break;
}
if (ch == '-') {
state = 5;
break;
}
if (ch == '.') {
domain.add(new String(input, mark, index - mark));
mark = index + 1;
state = 5;
break;
}
// Проверка на конец строки
if (ch == '\0') {
domain.add(new String(input, mark, index - mark));
state = 6;
break; // Дошли до конца строки -> заканчиваем работу
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 5: {
if ((ch >= 'a' && ch <= 'z') || (ch >= '0' && ch <= '9')
|| (ch >= 'A' && ch <= 'Z')) {
state = 4;
break;
}
if (ch == '-') {
break;
}
// Если встретили неправильный символ -> отмечаемся в state об ошибке
state = -1;
break;
}
case 6: {
// Успех! (На самом деле, мы сюда никогда не попадём)
break;
}
}
index++;
}
// Остальные проверки
// Не прошли проверку выше? Возвращаем false!
if (state != 6)
return false;
// Нам нужен домен как минимум второго уровня
if (domain.size() < 2)
return false;
// Ограничения длины по спецификации RFC 5321
if (local.length() > 64)
return false;
// Ограничения длины по спецификации RFC 5321
if (input.length > 254)
return false;
// Домен верхнего уровня должен состоять только из букв и быть не короче двух символов
index = input.length - 1;
while (index > 0) {
ch = input[index];
if (ch == '.' && input.length - index > 2) {
return true;
}
if (!((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))) {
return false;
}
index--;
}
return true;
}
}
В Точке мы обучаем наших AI-ассистентов, а для этого нужно много данных. В статье расскажу, как быстро собрать информацию практически с любого сайта при помощи фреймворка Scrapy.
Руководство для программистов: как создать сервис, который помогает выбрать лучший курс обмена криптовалюты. Работа с API, фильтрация обменников, подводные камни и честный итог.
Как выучить SQL с нуля в 2025? Сравниваем 6 платформ: SYNC STUDY, SQL Academy, Karpov Courses и другие. Бесплатные и платные курсы, задачи из реальной аналитики, поддержка PostgreSQL. Советы по выбору для новичков и профессионалов.