


Взаимодействие Python и FugueSQL в Jupyter Notebooks

FugueSQL — это язык который расширяет возможности SQL. Рассказываем, как пользоваться FugueSQL в связке с Python и Jupyter Notebooks.
4К открытий4К показов
Цель языка FugueSQL — обеспечить расширенный интерфейс SQL для сквозной передачи данных. Он позволяет получать, трансформировать и загружать данные в датафреймы Python в Jupyter Notebooks. Код на языке SQL парсится в код для Pandas, Spark или Dask.
Это дает пользователям SQL возможности Spark и Dask, на нужном им языке программирования. Кроме того, FugueSQL предлагает ключевые слова для распределённых вычислений, такие как PREPARTITION и PERSIST.
В этой статье мы рассмотрим базовые возможности FugueSQL и его использование с Spark или Dask.
Преимущества FufueSQL

Во-первых, как видно на гифке выше, мы можем использовать ключевые слова LOAD и SAVE. Во-вторых, FugueSQL использует более дружелюбный синтаксис, чем SQL. Пользователи также могут вызывать функции из Python в коде на FugueSQL.
Доступ к ячейкам SQL в Notebooks можно осуществлять через магическую команду %%fsql. Благодаря этому в Jupyter Notebooks работает подсветка синтаксиса. Также эти SQL ячейки можно использовать в Python коде через функцию fsql().
Присваивание переменных
Датафреймы могут быть присвоены переменным. Подобно временным таблицам SQL или обобщённым табличным выражениям. Кроме того датафремы могут быть получены из ячеек SQL и использоваться в Python. На примере ниже, видно, как два датафрейма создаются путем изменения df. df получен с помощью Pandas в ячейке Python (это df из первой картинки). Из этих датафреймов с помощью JOIN получается итоговый датафрейм final.

Шаблоны Jinja
FugueSQL может взаимодействовать с Python через шаблоны Jinja. Это позволяет логике на Python изменять SQL запросы, подобно параметрам в SQL.
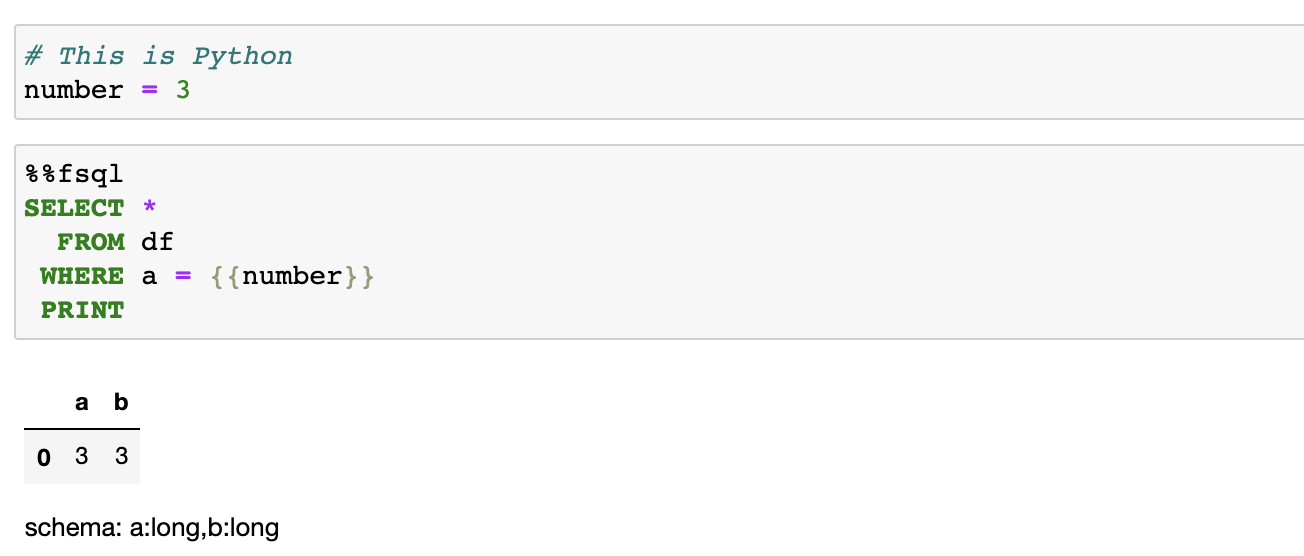
Функции Python
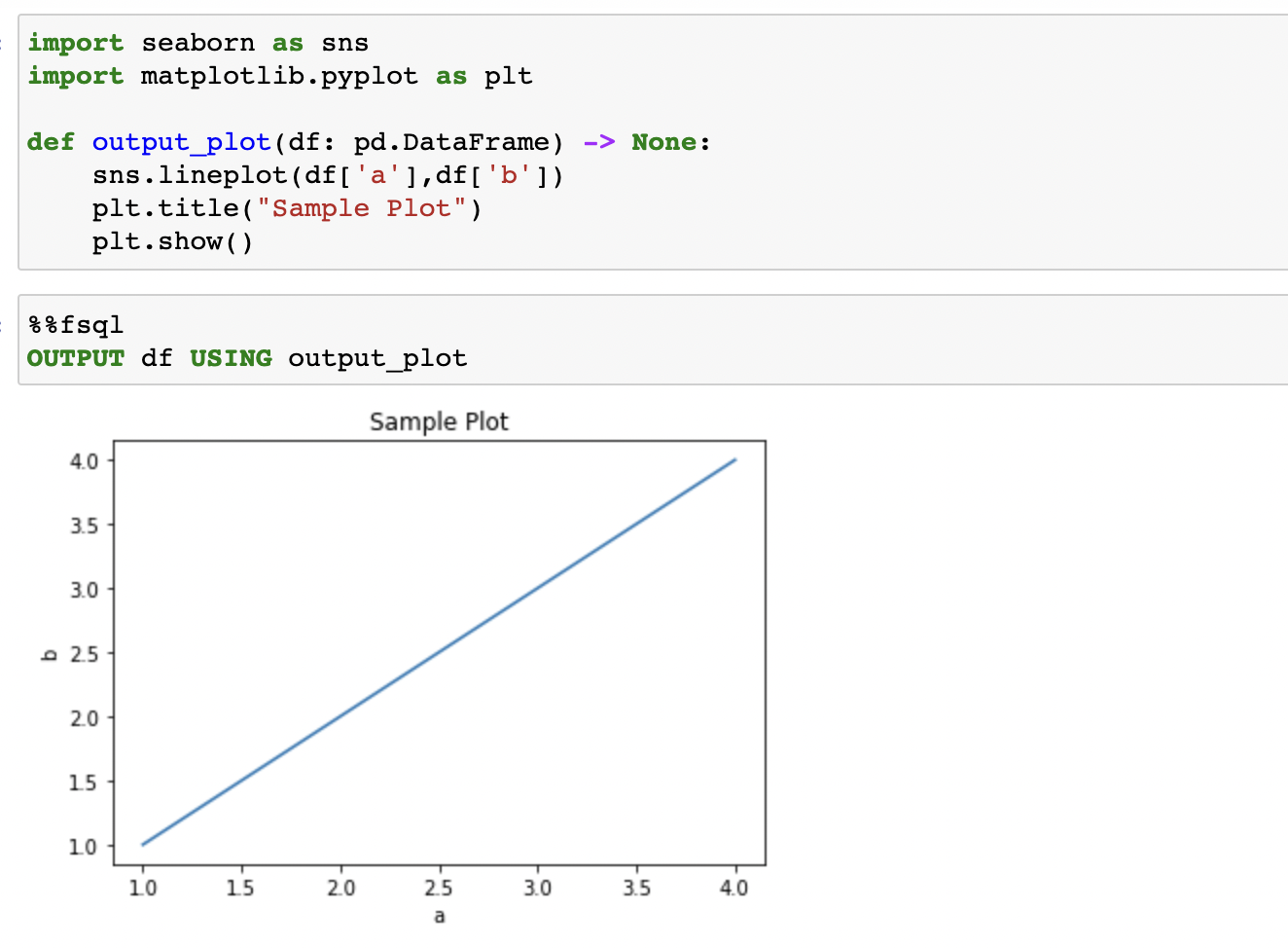
Благодаря FugueSQL, можно использовать Pyhton функции внутри блоков кода SQL. В примере ниже мы используем библиотеку seaborn чтобы нарисовать график полученный из двух колонок датафрейма. Для вызова функции используется ключевое слово OUTPUT.
Сравнение с ipython-sql
FugueSQL предназначен для работы с данными, которые уже загружены в память (работа с данными из хранилища также возможна). Проект под названием ipython-sql позволяет использовать магическую команду для ячеек %%sql. Эта команда для загрузки данных в среду Python из БД.
FugueSQL позволяет использовать один и тот же код на SQL в Pandas, Spark и Dask, не изменяя его. Основное внимание в FugueSQL уделяется вычислениям в производящимся памяти, а не загрузке данных из БД.
Распределённые вычисления в Spark и Dask
Поскольку объем данных, с которыми мы работаем, продолжает расти, механизмы распределённых вычислений, такие как Spark и Dask, становятся популярнее. FugueSQL позволяет пользователям использовать эти движки с одним и тем же кодом FugueSQL.
В приведенном ниже фрагменте кода мы изменили магическую команду с %%fsql на %%fsql spark, и теперь SQL-код будет работать на движке Spark.

Одна из распространенных операций, для которой будет полезен переход в распределенную вычислительную среду — это получение медианы каждой группы.
Во-первых, мы определяем в Jupyter Notebooks функцию Python, которая принимает фрейм данных, выводит user_id и медианное измерение. Эта функция предназначена для работы только с одним идентификатором пользователя одновременно. Даже если функция определена в Pandas, она будет работать на Spark и Dask.
Затем мы можем использовать ключевое слово PREPARTITION для разделения наших данных по user_id и применить функцию get_median.

По мере увеличения размера данных распараллеливание будет приносить больше пользы. В примере движок Pandas выполнял эту операцию около 520 секунд. Работа Spark (распараллеленного на 4 ядра) заняла около 70 секунд для набора данных с 320 миллионами строк.
Другой распространенный вариант использования Dask — обработка утечек памяти и запись данных на диск. Благодаря этому пользователи могут обрабатывать больше данных, прежде чем столкнутся с проблемами нехватки памяти.
Установка FugueSQL в Jupyter Notebooks
Fugue (и FugueSQL) доступны через PyPI. Они могут быть установлены с помощью pip (Dask и Spark устанавливаются отдельно).
В Jupyter Notebook, после запуска функции настройки, можно использовать магическую команду %%fsql. Это позволит работать подсветке синтаксиса команд SQL.

4К открытий4К показов

Разбираем, какие скилы и знания станут обязательными в 2026 году, что будут ценить работодатели и как новичку не потеряться на входе в ИТ-индустрию

Где учиться на продакт- и проджект-менеджера в 2025 году? В статье — проверенные курсы от Softline, TOP Academy, Нетологии и других школ с реальными отзывами, ценами и гарантией трудоустройства. Подробный разбор программ, форматов обучения и карьерных перспектив для начинающих.

Даже самая идеальная микросервисная архитектура может упасть. В статье обсудим зарубежный материал, где автор рассказывает о проблеме Context Collapse.

Обзор лучших инструментов для оценки качества программного кода! Эксперты подготовили подробную статью о том, для чего необходимо проводить валидацию кода, и подобрали лучшие сервисы