


Приключения паролей: что происходит с вашими учетными данными в Интернете?

Многие люди оставляют свои данные на разных сайтах, но не всегда задумываются о том, как эта информация обрабатывается. Большинство из них, скорее всего, не знает по каким маршрутам проходит то, что они о себе написали. Мы решили исправить это и подробнее рассказать о путешествиях ваших данных.
16К открытий16К показов

Рассказывает Тайлер Эллиот Беттильон, преподаватель Galvanize и Bradfield.Переведено в Alconost.
Знакома ситуация: вводите в электронную форму в Интернете свой номер социального страхования и задумываетесь: «Я точно хочу нажать „Отправить“?» Большинство из нас доверяют веб-сайтам, чьи владельцы нам совершенно не знакомы, а стандарты эксплуатации — непонятны. Мы с готовностью забиваем в эти окошки на веб-страницах наши страховые номера, пароли, номера кредитных карт, адреса, номера телефонов и всевозможную иную конфиденциальную информацию, а потом без задней мысли куда-то отправляем эти данные. На пути к месту назначения наша конфиденциальная информация летит по воздуху в виде радиоволн, передается по медным проводам в виде электрических сигналов, проносится по оптоволоконным кабелям вспышками света. Наши данные, совершающие в Интернете этот сложный танец, зачастую проходят по общедоступным каналам, где их без труда может отследить предприимчивый хакер или бдительная государственная структура — например, АНБ или ФСБ.
Когда данные покидают ваш компьютер, куда они направляются? Что с ними происходит по пути? Какие существуют системы, обеспечивающие приватность вашей информации в пути следования и после прибытия к месту назначения? Если кратко — их много. Итак, пристегнитесь, вас ждет увлекательная экскурсия, в ходе которой мы расскажем о страшных мытарствах вашего логина и пароля, через которые им приходится пройти ради неразглашения ваших тайн в Интернете.
Мы уязвимы – еще до того, как нажимаем «Отправить»
Как правило, веб-страницы загружаются по протоколу HTTP (протокол передачи гипертекста) – вот почему в Интернете так много адресов, начинающихся с http://. Разработка этого протокола началась в 1989 году, в те времена Интернет был принципиально иным, нежели сейчас. Тогда Интернетом пользовались в основном академические исследователи, работавшие в университетах. Те, кто занимался разработкой Интернета, принадлежали к небольшому сообществу друзей и коллег, ходили друг к другу на конференции и поздравляли друг друга, когда их имена оказывались на журнальных страницах. Более того, Интернет не применялся для передачи существенных объемов приватной информации. Именно поэтому протоколы, которые легли в основу Интернета, создавались с расчетом на доверие между всеми сторонами.
Спецификации HTTP и базового протокола, поверх которого он реализован (TCP), не затрагивали (и до сих пор не затрагивают) каких-либо вопросов, связанных с приватностью, шифрованием или вообще любыми проблемами, касающимися безопасности. Текстовая информация передается в Интернете по протоколу HTTP как есть; любой, кто в состоянии «прослушать линию», может прочитать данные, передаваемые между отправителем и получателем. Более того, искусный злоумышленник может устроить атаку «человек посередине». Если где-то на пути между Бобом и Алисой удастся поставить свой компьютер, то на нем можно получать исходящие сообщения от Алисы, там же их и сохранять, а Бобу отправлять другую информацию, подменяя сообщения Алисы; в сущности, человек посередине может выдать себя за Алису, а Боб ни о чем не догадается.
Когда Всемирная Паутина превратилась в мейнстрим, пришлось разрабатывать стандарты для защиты от всевозможных атак. В 1994 году была изобретена первая версия протокола SSL (слой защищенных сокетов), и появился протокол HTTPS (HTTP по SSL). SSL и его более новая разновидность TLS (протокол защиты транспортного уровня), в отличие от TCP, создавались именно для того, чтобы защитить пользователя в среде откровенного недоверия (среди специалистов по компьютерной безопасности паранойя считается признаком профессионализма). Хотя SSL существует уже 24 года и дает существенно больше гарантий, чем практически ничего не гарантирующий TCP, протокол SSL до сих пор применяется не всеми операторами сайтов. Именно из-за таких исключений у хакеров появляется самая простая возможность украсть ваши данные еще до того, как вы успеете нажать кнопку «Отправить». Рассмотрим такую ситуацию:
Когда данные загружаются по HTTP, протокол вообще ничего не делает, чтобы проверить, на самом ли деле вы получили именно те данные, которые запрашивали. Допустим, вы забили в адресной строке http://www.facebook.com – и ваш браузер получает IP-адрес этого сервера при помощи системы доменных имен (DNS), затем направляет по данному адресу HTTP-запрос. В ответ мы ожидаем получить домашнюю страницу Facebook, расположенную на сервере Facebook. Если в данном случае удастся осуществить атаку «человек посередине», то перехватчица, назовем ее Труди, прочтет всю информацию, отправленную вами на Facebook, и вместо того чтобы просто переадресовать данные между вами и Facebook (как произошло бы на любом невредоносном сайте в Интернете), Труди сохранит эту информацию у себя, а сама слегка изменит ответы, поступающие от Facebook, добавив в них один лишний скрипт-тег:
Теперь, когда вы наводите курсор мыши на кнопку «войти», фишинговый сервер Труди считывает ваши имя и пароль, прямо когда вы их вводите. В данном случае используется событие mouseover, так как Труди рассчитывает, что, когда вы нажмете на кнопку, произойдет «нормальная» операция – вы войдете на Facebook, даже не подозревая, что ваши учетные данные только что похитили.
Если мы не хотим полагаться на действия пользователя, который должен навести на кнопку курсор мыши и нажать «отправить», то можем перехватывать нажатия клавиш, когда поле с паролем находится в фокусе, либо воспользоваться событием blur, чтобы определить, когда это поле выйдет из фокуса. Если полностью отключить в браузере JavaScript, это поможет защититься от подобных атак, однако злоумышленники все равно смогут разузнать кое-какую информацию, внедрив на сайт вредоносные таблицы CSS и вообще не прибегая к JavaScript.
Даже если пользовательский запрос, выполняемый при нажатии кнопки «войти», делается по протоколу HTTPS, мы все равно остаемся уязвимы для подобных атак, если посадочная страница была передана нам по протоколу HTTP. Естественно, если сами учетные данные передаются по HTTP, то Труди обойдется практически без всяких ухищрений: она просто запишет имя и пароль, когда они пройдут через ее компьютер, направляясь на сайт Facebook.
Для успешного выполнения атаки «человек посередине» Труди требуется проявить изобретательность, однако этого мало: еще нужно, чтобы Facebook был небрежен, а пользователь — несведущ. Реальный Facebook, где принято следовать проверенным методам, никогда не передает страницу входа по HTTP; для этого Facebook всегда использует HTTPS. Вы, подкованный пользователь, знаете, что конфиденциальную информацию никогда нельзя указывать на сайте, в адресе которого не указано HTTPS и нет картинки в виде маленького зеленого замочка. Как же HTTPS защищает нас от Труди и других заправских похитителей данных?
Рукопожатие TLS и центры сертификации
В контексте данного примера TLS обеспечивает две критически важные услуги: верификацию конечной точки и шифрование. Верификация конечной точки гарантирует, что все данные, которые вы получаете, исходят исключительно от того лица/с того сервера, откуда вы рассчитываете их получить (например, с Facebook). В предыдущем примере Труди смогла добавить крупицу своей вредоносной информации в транзакцию между нами и Facebook. Однако при верификации конечной точки мы можем быть уверены, что вся поступающая к нам информация приходит непосредственно от Facebook (даже если Труди все равно вклинилась в наше соединение). Шифрование обеспечивает, что Труди не сможет прочесть никаких данных, передаваемых между двумя сторонами.
При соединениях по протоколам SSL/TLS перед обменом какой-либо конкретной информацией (например, перед передачей логина и пароля) всегда выполняется «рукопожатие». При акте рукопожатия две связывающиеся стороны устанавливают (зашифрованное) соединение, при котором проводится идентификация как минимум одной стороны. Рукопожатие проходит в несколько этапов, включает симметричное и асимметричное шифрование:
- Две стороны согласовывают «набор шифров», который будет использоваться при этом соединении. В набор шифров входит симметричный алгоритм шифрования (обычно AES), криптографический алгоритм хеширования (обычно берут какой-нибудь из семейства SHA-2 ), а также случайное одноразовое значение, именуемое «нонс», гарантирующее уникальность каждого конкретного рукопожатия (и обеспечивающее защиту от атак повторного воспроизведения).
- Сервер (в данном случае — Facebook) отправляет клиенту так называемый сертификат. В некоторых случаях сервер может потребовать сертификат и у клиента, но в нашем примере с Facebook такого не происходит.
- Клиент проверяет сертификат сервера и, если сертификат действителен, извлекает из него публичный ключ сервера. Если сертификат недействителен, то клиент отклоняет соединение.
- Клиент, оперируя согласованным набором шифров, генерирует значение, именуемое «предварительный секрет». Это значение зашифровывается публичным ключом сервера и отсылается на сервер.
- Сервер получает предварительный секрет. Исходя из набора шифров и предварительного секрета, он генерирует главный секрет. Клиент независимо от него также генерирует главный секрет. Если и клиент, и сервер при этом строго выполнят все правила, то независимо сгенерированные главные секреты совпадут.
- Главный секрет используется в качестве ключа для ранее согласованного симметричного алгоритма шифрования; теперь, когда его сгенерировали и сервер, и клиент, они начинают использовать симметричный алгоритм шифрования для коммуникации.
- Наконец, обе стороны независимо используют согласованный алгоритм хеширования для вычисления хеша всех сообщений, которыми уже успели обменяться, и отсылают друг другу вычисленные хеш-коды. Если хеш-коды не совпадут, то стороны зафиксируют вторжение и разорвут соединение. В противном случае они станут отправлять прикладные данные (ваш логин и пароль), пользуясь согласованным симметричным алгоритмом шифрования.
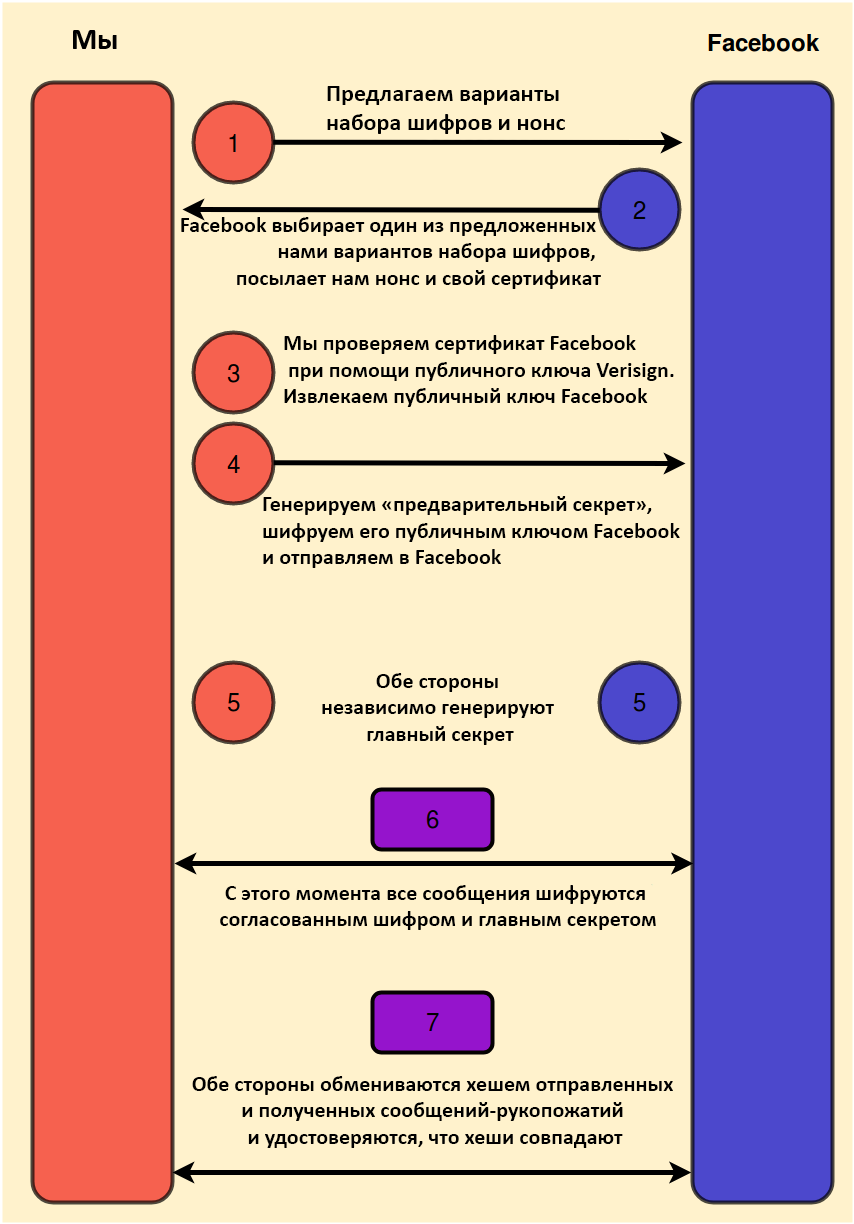
Чтобы понять, каким образом такой поток задач защищает нас от всевозможных Труди, нужно разобраться в подробностях шифрования открытым ключом, а также в том, какова роль центров сертификации при создании и подписании сертификатов.
Концептуально шифрование открытым ключом — довольно простой феномен (а обсуждение его сложных деталей выходит за рамки этой статьи). При симметричном шифровании один и тот же ключ используется для шифрования и дешифровки любых данных, которые вы собираетесь передавать. Защита напоминает обычный замок: если к вам в квартиру кто-нибудь подселяется, то вы даете ему точно такой ключ, какой уже есть у вас. Этим ключом можно открыть или закрыть дверь. При шифровании открытым ключом должно быть сгенерировано два ключа— публичный и соответствующий ему приватный. Данные зашифровываются приватным ключом, а расшифровать их можно только публичным.
Шифрование приватным ключом напоминает древний обычай скрепления писем восковой печатью и использование восковых клейм. Если на письме стоит печать с изображением лютоволка Старков, то кто угодно может открыть его (просто сломать печать,то есть воспользоваться публичным ключом). Кроме того, первый, кто вскроет это письмо, может не сомневаться,
что оно отправлено кем-то из дома Старков.
Я за всю жизнь не придумал более безупречной метафоры, которая бы описывала шифрование публичным ключом, чем следующая. Нормальная метафора такова: шифрование данных публичным ключом напоминает работу с сейфом, в котором есть ячейка, как в почтовом ящике. Кто угодно может бросить письмо в сейф, а прочесть его может лишь владелец сейфа. Если вы знаете более точную метафору – поделитесь в комментариях!
Если отбросить метафоры, суть такова: любой оператор веб-сайта, желающий работать по протоколу HTTPS, должен сгенерировать пару ключей: публичный и приватный. Публичные ключи, как вы уже догадались, общедоступны, а приватные — тщательно оберегаются. Таким образом, кто угодно может зашифровать данные публичным ключом Facebook, и расшифровать эти данные может только Facebook. Именно это происходит с предварительным секретом: даже если Труди перехватит все данные, переданные при рукопожатии, она не сможет прочитать предварительный секрет, не имея приватного ключа Facebook. Без предварительного секрета Труди не сможет определить главный секрет и, следовательно, не сможет расшифровать данные, зашифрованные симметричным ключом.
Центр сертификации (CA | Certification Authority) — это доверенная третья сторона; не Facebook и не пользователь, но (предположительно) обе эти стороны доверяют центру сертификации. Роль CA в данном процессе — «подписать» сертификат Facebook своим публичным ключом. Передача информации выстраивается так:
- Facebook запрашивает Verisign (крупный центр сертификации) создать и подписать для него сертификат. При этом Verisign получает от Facebook его публичный ключ.
- Verisign создает сертификат, в котором содержится идентификационная информация о Facebook и о публичном ключе Facebook.
- Verisign шифрует сертификат своим приватным ключом. Это означает, что кто угодно может расшифровать эти данные, воспользовавшись публичным ключом Verisign; а также что прочитать сертификат можно только после такой расшифровки. Если кто-нибудь попробует расшифровать сертификат при помощи публичного ключа Verisign, и данные действительно окажутся в читаемом виде, то мы будем уверены, что сертификат действительно был подписан приватным ключом Verisign.
- Когда Facebook присылает нам свой сертификат, мы расшифровываем его публичным ключом Verisign. Если сертификат откроется, и мы сможем извлечь оттуда публичный ключ Facebook, мы тем самым убедимся, что действительно общаемся с Facebook (поскольку доверяем Verisign).
Итак, работая по протоколу SSL/TLS, можно установить безопасное соединение и удостовериться, что мы действительно подключились к тому серверу (вышли на контакт с тем лицом), с которым собирались (при условии, что мы доверяем Verisign). Но случай с грандиозным взломом Equifax всегда напоминает, что даже если наши данные зашифрованы при передаче, это еще не гарантирует, что они будут защищены и в период хранения.
Чтение по теме: Предупреждён – значит вооружён: от чего не спасает HTTPS
Хранение и хеширование паролей
Когда наша информация получена и сервер Facebook ее расшифровал, Facebook должен проверить наши учетные данные. Это значит, что Facebook должен сравнить информацию, только что поступившую от нас к нему на сервер, с информацией о нас, которая у него зарегистрирована. Если кто-нибудь пришлет ваш логин, сопроводив его не вашим паролем, а чем-то другим, то этому лицу должно быть отказано в обслуживании. Да, Facebook мог бы сохранить ваш пароль в своей базе данных как обычный текст, когда вы только заводили аккаунт; в таком случае он, естественно, мог бы сравнить эту информацию с тем паролем, который вы указали при попытке входа. Однако такая практика чревата серьезной уязвимостью.
Допустим, вы работаете в Facebook, в частности, управляете некоторыми базами данных компании. У вас есть права администратора, и это означает, что вы в любой момент можете обратиться к базе данных и проверить, какие данные там находятся. Далее предположим, вы знаете, что в Facebook о вас распускают грязные слухи. Согласитесь, хочется подсмотреть пароль обидчика, войти в систему под его именем и публично извиниться перед собой от лица обманутого таким образом негодяя. Либо, скажем, сотрудника ущемил сам Facebook, и он хочет немного отыграться, нелегально сбыв на черном рынке большой кэш с комбинациями логинов и паролей. Наконец, существует риск, что в базу данных проникнет посторонний (хакер), и такой риск тоже никогда нельзя свести к нулю. Даже если вы полностью доверяете всем своим сотрудникам, всегда сохраняется риск, что вашу базу данных могут взломать.
Основная проблема хранения паролей состоит в том, как сохранить достаточное количество информации, нужное для аутентификации пользователя, но при этом не допустить, чтобы кто-нибудь проник в базу данных и выдал себя за этого пользователя? Иными словами, как удостовериться, что нам предоставили корректный пароль, не сохраняя сам пароль? Для этого применяются криптографически безопасные хеш-функции.
Криптографическая хеш-функция – это «однонаправленное» отображение некого информативного ввода фиксированной длины (вашего пароля) на вывод фиксированной длины (вывод называется хеш-код или хеш-значение). Если вы получите хеш-код с конкретным значением, вам не хватит информации, чтобы восстановить ввод, на основе которого он сделан. Более того, любое входное значение (в идеале) должно отображаться на уникальном значении вывода – это означает, что даже два одинаковых пароля никогда не результируют в один и тот же хеш-код.
Поскольку длина вывода фиксирована, теоретически невозможно обеспечить такое свойство хеш-функции. Например, если длина хеш-кода всего 8 разрядов, то может быть всего 256 уникальных соответствующих хеш-кодов. Таким образом, как только будет сохранено 257 уникальных паролей, как минимум между двумя значениями возникнет коллизия, независимо от того, каким образом хеш-код вычислялся. Современные криптографические хеш-алгоритмы генерируют длинные хеш-коды: в порядке вещей значения длиной от 512 до 2048 разрядов. 512-разрядный хеш-код дает 2⁵¹² ~= 1.34e+154 уникальных вариантов (это число со 154 нулями — вот так много). 2048-разрядные хеш-коды дают примерно 3.2e+617 уникальных значений (это число с 617 нулями). Поэтому хотя теоретически и невозможно обеспечить гарантированное отсутствие коллизий между любыми двумя хеш-кодами, можно добиться, чтобы случайная коллизия такого рода стала крайне маловероятна, а намеренно создать такую коллизию при помощи вычислительной машины было бы технически невозможно.
Поэтому Facebook, чтобы не сохранять ваш пароль, сохраняет его криптографический хеш. Если хеш-функция сделана хорошо, то со сгенерированным хеш-кодом совпадет всего один вариант ввода – ваш пароль. Поскольку на основе хеш-кода невозможно сгенерировать пароль, который ему соответствует (криптографические функции являются «однонаправленными»), кто бы ни взломал базу данных с хешированными паролями, все равно не сможет при помощи этой информации выдать себя за другого пользователя. Когда вы хотите войти в систему, Facebook просто заново вычисляет хеш-код вашего пароля и сравнивает его с хеш-кодом, сохраненным в базе данных. Если совпадают хеш-коды, то совпадают и пароли, и Facebook может снова избавиться от пароля, записанного обычным текстом.
К сожалению, хакеры научились обходить и такой механизм хранения данных.
Радужные таблицы
В конечном итоге многие криптографические хеш-функции действительно «выходят из строя». Время от времени рост вычислительных мощностей приводит к тому, что новая машина может искусственно создать коллизию методом «в лоб» (простым перебором). Машина генерирует тучи случайных паролей и хеширует их до тех пор, пока какой-нибудь хеш-код не повторится. Бывает, что в алгоритме обнаруживается уязвимость, которая ранее оставалась незамеченной. Именно это случилось с алгоритмом MD5, когда в 2012 году он пал под напором «коллизионной атаки»— основного орудия червя Flame. Сломать алгоритм MD5 удалось общими усилиями высококлассных экспертов: задачу решали аналитики из ЦРУ, АНБ и армии Израиля.
Чтобы сломать сильный хеш-алгоритм, требуется редкостное сочетание знаний и опыта в информатике. Более распространенные попытки взлома криптографических хеш-функций основаны на совершенно иных приемах. Как это часто бывает в сфере безопасности, основной источник уязвимостей в области хешированных паролей – это человеческий фактор. Потенциальные взломщики быстро осознали, что эксперты по безопасности годами скрупулезно ваяют алгоритмы, предназначенные именно для того, чтобы отвадить потенциальных взломщиков; а вот от Васи Пупкина, который «ни хрена не смыслит в криптографии» они подстраховаться не догадываются.
Радужная таблица – это атака, нацеленная на базы данных с хешированными паролями. Она основана на допущении, что большинству людей свойственна как минимум одна из этих слабостей:
- Многократно применяют один и тот же пароль на разных сервисах.
- Придумывают простой пароль, который легко разгадать.
- Берут пароль, которым уже пользовался кто-то другой (предполагается, что большинство из нас не особенно оригинальны, когда требуется придумывать пароли).
Вооружившись тремя этими допущениями и комбинируя их с другими фишинговыми атаками, злоумышленники создают большие базы данных известных паролей, заранее вычисляя для них хеш-коды. Такую таблицу начинают составлять со списка самых распространенных паролей (например, password12345, 123abc, 1q2w3e4r5t6y), а также тех паролей, что удалось добыть путем фишинга. Для всех известных паролей, попавших в список, по популярным хеш-алгоритмам вычисляются хеш-коды, которые затем сохраняются в базе данных. Такая база данных именуется «радужной таблицей».
Теперь, когда злоумышленник наконец-то взломает базу данных Facebook, ему не придется ничего «расшифровывать», не придется даже устраивать коллизий. Злоумышленнику придется всего лишь определить, совпадает ли хеш-код из базы данных Facebook с каким-либо из заранее вычисленных хеш-кодов из радужной таблицы. Если хеш-код совпадает, то злоумышленник просто смотрит, какой текстовый пароль дал этот хеш-код, занесенный в радужную таблицу. Распространенные пароли встречаются часто, поэтому взломанная база данных будет в значительной степени совпадать с радужной таблицей.
Для борьбы с радужными таблицами в большинстве современных баз данных для хранения паролей применяется иная тактика – так называемая «соль».
Подсоленный хеш: не просто перекус на завтрак
Составляя радужную таблицу, злоумышленник исходит из того, что на основе известных паролей можно заранее вычислить хешированные значения, которые будут присутствовать в базе данных с хешированными паролями. Такие вычисления начинаются загодя, гораздо раньше, чем удастся взломать реальную базу данных. Когда база данных с хешированными паролями будет взломана, станет совершенно просто сопоставить добытые из нее хеши с соответствующими паролями, записанными обычным текстом и хранящимися в радужной таблице. Для борьбы с радужными таблицами специалисты по безопасности используют соль. Смысл соли – внести в хеши паролей долю неопределенности, чтобы пароли было невозможно заготовить заранее, опираясь на радужную таблицу.
Смысл соли удобнее всего объяснить на примере – с него и начнем. Допустим, мой пароль — “superSafe123”. Запустив в командной строке команду openssl, можно вычислить хеш моего пароля по алгоритму sha-256 (-n в следующем коде нужна, чтобы не появлялись переходы на новую строку от echo, а 256 я выбрал, потому что такой вариант лучше помещается на большинстве мониторов — 512 было бы надежнее):
Если мы не просто хешируем сам пароль, а добавим соли, то соль (некое случайное значение) подцепляется к паролю. Затем мы прицепляем соль к началу сгенерированного хеша и добавляем разделительный знак (обычно в таком качестве используется двоеточие или точка с запятой, но конкретный знак в данном случае не важен – просто нужно придерживаться выбранного варианта), и впоследствии легко можем отделить соль от хеша. Итак, продолжая наш пример, предположим, что я случайным образом сгенерировал значение 4321» и использовал его в качестве соли. Теперь хеширование приобретает примерно такой вид (на практике значение-соль должно быть длиннее, в идеале оно должно быть глобально уникальным):
После подсаливания хеш значительно изменился; в случае с криптографической хеш-функцией так и должно быть. Если хотя бы чуть-чуть модифицировать ввод, результирующие хеш-коды кардинально меняются. Прежде, чем можно будет сохранить это значение в нашей базе данных, нужно пометить, какое именно значение мы в него добавили в качестве соли (в качестве разделительного знака я поставил двоеточие):
Соль совершенно не доставляет проблем, если требуется всего лишь удостовериться, что полученный нами пароль совпадает с паролем, сохраненным в базе данных. Просто запрашиваем в нашей таблице имя пользователя, убираем соль (отсекаем все символы, которые идут до разделительного знака), подцепляем полученный результат к тому паролю, что нам прислали, и хешируем как обычно. Однако для тех, кто пытается вести радужные таблицы, соль – это настоящий кошмар.
Уникальная соль позволяет сгенерировать даже из самых распространенных паролей уникальные хеш-коды, если пароль хешируется в подсоленном виде. Любые атаки на основе заранее вычисленных значений в таком случае будут безуспешны, если только злоумышленник не научится систематически угадывать, какая именно соль добавляется к каждому конкретному паролю. Внося такую долю случайности, мы хорошо страхуемся против радужных таблиц, поскольку заранее вычислить все возможные исходные комбинации для хешей (пароль+соль) невозможно, тогда как вычислить хеши для всевозможных паролей вполне реально.
Что все это значит лично для меня?
Компьютерная безопасность – это война на истощение. Хакеры постоянно изобретают новые приемы, а специалисты по безопасности вырабатывают контрмеры. Чтобы защитить от хакеров себя и свою компанию, лучше всего постоянно обновлять ПО. При большинстве атак используются хорошо известные уязвимости, найденные в старых версиях программ. Среднестатистический хакер не занимается поиском новейших уязвимостей, а отыскивает, где уже установлен старый софт, уязвимости которого давно известны. С чем бы вы ни работали, будь то серверный фреймворк, операционная система или браузер – всегда устанавливайте новейшие обновления систем безопасности.
Обращаюсь к рядовому пользователю Интернета: не работайте с паролями, которые легко разгадать. На каждом сайте, где вы бываете, применяйте уникальные пароли и никогда не указывайте конфиденциальных данных на сайтах, не вызывающих доверия. Ни в коем случае нельзя доверять сайту, где не используется протокол HTTPS (ищите в адресной строке изображение зеленого замочка). Освойте менеджер паролей и попробуйте установить в том браузере (или во всех ваших браузерах), с которым(и) работаете, соответствующее расширение HTTPS Everywhere от компании EFF.
Чтение по теме: Как перестать использовать пароль «123456» и начать жить
Обращаюсь к тем, кто занят поддержкой сайтов: если в настоящее время ваш сайт работает по протоколу HTTP, а не HTTPS, приобретите SSL-сертификат и сделайте все необходимое для защиты ваших пользователей — внедрите у себя HTTPS. Можно начать с программы Let’s Encrypt от Linux Foundation. Кроме того, убедитесь, что никогда не сохраняете паролей (или других конфиденциальных данных) в незашифрованном текстовом формате. Подсаливайте и хешируйте пароли ваших пользователей, постарайтесь соблюдать такую тактику при работе с любой конфиденциальной информацией, которую вам, возможно, придется проверять: к примеру, с номерами социального страхования. Также попробуйте обратиться в частную фирму, которая могла бы выполнить аудит безопасности вашего приложения. Так вы сможете лучше понять ваши слабые места и пропатчить любые уязвимости, которые удастся обнаружить.
Эта статья – лишь верхушка айсберга по сравнению с подробным рассказом о том, как можно (и как нельзя) обращаться со своими данными прежде, чем выкладывать их в открытый Интернет. Надеюсь, она помогла вам составить впечатление о том, какая огромная работа выполняется для защиты и кражи онлайновой информации и сколько здесь нюансов. Подробнее эти темы рассмотрены в разделах «Security» и «Privacy» на сайте EFF.
О переводчикеПеревод статьи выполнен в Alconost.Alconost занимается локализацией игр, приложений и сайтов на 68 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.Подробнее

16К открытий16К показов

Обзор лучших альтернатив Notion для ведения базы знаний в IT-проектах в 2025 году. Сравнение функционала, интеграций и удобства для разработчиков и команд.

Artezio опубликовала рейтинг самых защищенных мессенджеров 2025 года: в топ вошли Signal, Olvid, Threema и другие. Telegram выбыл из списка из-за проблем с безопасностью.
В этой части Юсуп Изрипов рассказывает, что такое хуки и кастомные хуки, а также про Compound Components и Серверные компоненты и Suspense.

Redis выпустил экстренные исправления для уязвимости CVE-2025-49844, которая позволяет удалённое выполнение кода и ставит под угрозу сотни тысяч серверов.