context-async-sqlalchemy — лучший способ использовать sqlalchemy в async python приложении
context-async-sqlalchemy помогает очень просто работать с sqlalchemy в async python приложениях через контекст. Автоматическое управление engine, session, transaction.

Сначала кратко пройдемся по теории из чего состоит sqlalchemy и как ее происходит интеграция в python приложение. Посмотрим какие есть нюансы и как context-async-sqlalchemy помогает вам удобно работать.
Важно что речь идет только об async python.
Краткая сводка по sqlalchemy
sqlalchemy предоставляет Engine, который отвечает за пул подключений к базе данных. Так же sqlalchemy предоставляет Session через которую мы и делаем sql запросы. Сессия обладает одним единственным коннектом, который она получает от engine.
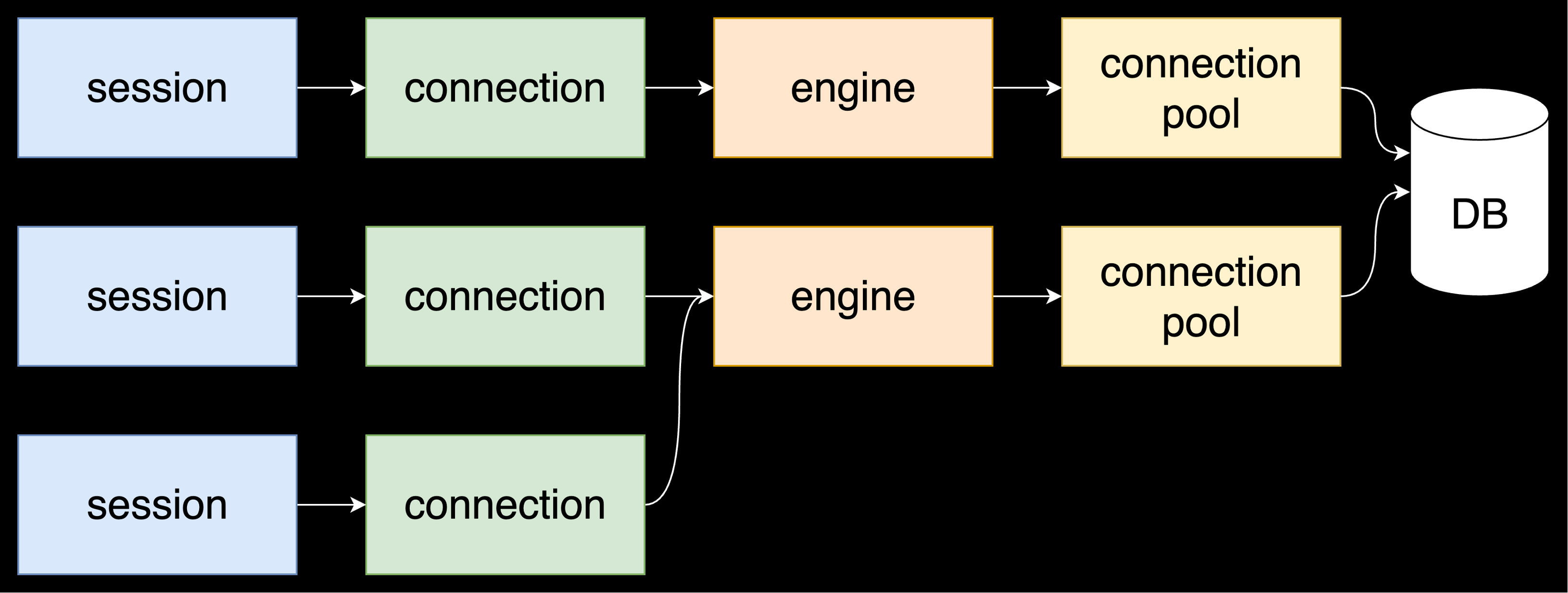
Engine должен жить долго, чтобы долго жил пул коннектов к бд. А вот сессии должны жить как можно короче, чтобы как можно быстрее отдавать коннект конкурирующим операциям.
(На схеме 2 engine подключено к одной бд, что конечно странно. Тут хотелось просто подсветить что каждый engine имеет свой пул. В приложении вы будете иметь один engine для одной бд. Например 1 для мастера и 1 для реплики)
Внедрение и использование в приложении
Прямое использование
Для начала посмотрим на самое простое внедрение и ручное использование в котором используется только sqlalchemy и это можно внедрить куда угодно.
Создаем engine и создаем session_maker чтобы создавать сессии:
И вот представим у нас есть функция создания юзера, которая является ручкой:
На 2 строке мы открыли сессию, на 3 строке открыли транзакцию и наконец на 4 строке мы выполнили какой-то sql запрос относящийся к созданию юзера.
А теперь представим, что мы делаем два sql запроса в рамках создания юзера
Тут появляется 2 проблемы:
- Используется 2 транзакции, хотя вероятно мы бы хотели получить одну транзакцию
- Дублирование кода
Можно попытаться решить эту проблему, если вынести контекстные менеджеры повыше:
Но если мы теперь взглянем на несколько ручек, то увидим что дублирование кода не исчезло:
Dependency
Можно использовать dependency и вынести управление сессией и транзакцией туда. Например в FastAPI это можно сделать так:
Эту проблему можно было бы решить, если в dependency возвращать не сессию напрямую, а например какой-то DI контейнер и из него уже извлекать сессии и иметь возможность их закрывать. Но это увеличивает количество кода практически как в предыдущем варианте и готовых решений в интернете я не нашел.
Так же теперь session нужно прокидывать по всему стеку вниз, до момента где эта сессия реально потребуется:
Как видите do_first сам не использует сессию, но вынужден принимать аргумент чтобы прокинуть его ниже. Лично мне это очень не нравится. Мне нравится инкапсулировать такое внутрь insert_to_database, тут скорее вкусовщина и борьба философий.
Обертки над sqlalchemy
Есть разные обертки над sqlalchemy которые могут предоставлять разные удобства, но я из даже рассматривать тут не буду потому что у них есть важный нюанс: новый синтаксис. То есть разработчики знающие sqlalchemy не сразу смогут работать через библиотеку обертку.
Новая библиотека
Все выше указанное мне не очень понравилось. Мне не понравилось что в своем новом FastAPI сервисе мне нужно написать кучу кода, чтобы было удобно работать с sql и готовых решений которые позволили бы писать мало кода, но и не ограничивали бы ручное управление сессиями и транзакциями я не нашел. И сначала я написал удобно для себя и теперь делюсь этим с миром.
Что хотелось получить от библиотеки при работе с ней:
- Мало кода без дублирования
- Автоматический commit или rollback, когда нет нужды вручную этим управлять
- Есть возможность ручного управления сессией и транзакцией
- Удобно для CRUD и удобно для сложных сценариев
- Не привносит новый синтаксис как обертки
- Не зависит от веб фреймворка
И вот что получилось:
Простейший сценарий
Вот пример простейшего сценария, когда просто в ручке хочется сделать один sql запрос и чтобы сессия как-то сама создалась, сама открылась транзакция и само все закрылось. Мне тут не нужно обо всем этом париться. Я просто знаю, что в конце обработки запроса все это точно будет закрыто.
Функция db_session создает новую сессию с которой можно работать. Сессия будет закрыта в конце обработки запроса. Все. Вот так просто. 1 строка для получения сессии и выполняем нужные sql запросы.
А вот так выглядит несколько запросов в рамках одной сессии и транзакции:
Функция db_session не будет создавать новую сессию если она уже есть. Таким образом insert_user_profile использует ту же самую сессию и ту же транзакцию.
Досрочное закрытие транзакции
А что если хочется закоммитить заранее? Можно!
Или вот например такой кейс: у вас есть функция insert_something, которая используется в одной ручке, где автокоммит в конце запроса - хорошо. И вы хотите переиспользовать insert_something внутри другой ручки, в которой нужен досрочный коммит. Не нужно никак модифицировать insert_something, можно сделать так:
А еще лучше сделать вот так, как бы обернуть функцию в отдельную транзакцию:
Можно так же досрочно сделать rollback через rollback_db_session .
Досрочное закрытие сессии
Бывают ситуации, что нам нужно закрыть сессию, чтобы отпустить коннект, пока мы например делаем другую долгую работу. Можно сделать так:
close_db_session закрывает сессию. Когда update_something вызовет db_session он уже получит новую сессию и другой коннект.
Конкурентное исполнение запросов
В sqlalchemy нельзя делать 2 конкурентных запроса в одной сессии. Для этого нужно создавать отдельную сессию.
Библиотека предоставляет 2 способа чтобы можно было легко делать конкурентные запросы.
run_in_new_ctx запускает функцию в новом контексте, таким образом функция получит новую сессию. Так можно например использовать функции в gather или asyncio.create_task
Либо можно вообще использовать сессию не используя контекст вообще. Как в ручном режиме про который я рассказывал в начале
Эти способы можно комбинировать:
Другие сценарии
В репозитории есть примеры интеграциий в приложения. Там же можно увидеть различные сценарии, как можно пользоваться библиотекой. Через эти же сценарии сама библиотека и тестируется, в контексте приложения, а не в абстракции.
Интеграция библиотеки с приложением
Теперь посмотрим как интегрировать эту библиотеку в свое приложение. Я хотел сделать так, чтобы это было очень просто.
Начнем как раз с создания engine и session_maker, а так же ответим на вопрос что такое connect который все время передается в функции библиотеки. За параметры соединения с базой данных отвечает DBConnect
Предполагаемое использование - глобальный инстанс, который отвечает за жизненный цикл engine и session_maker.
Он принимает на вход 2 фабрики:
engine_creator- фабрика по созданиюenginesession_maker_creator- фабрика по созданиюsession_maker
Вот примеры:
host - опциональный параметр хоста базы данных к которой нужно подключиться.
Почему хост опционален и почему фабрики? Потому что либа позволяет переподключаться к бд в рантайме. Это важно, например, при работе с мастером и репликой.
У DBConnect есть еще один опциональный параметр - обработчик, который будет вызван перед созданием новой сессии. Там вы можете поместить какую угодно логику:
В конце жизни вашего приложения нужно корректно закрыть соединение. Для этого у DBConnect есть метод close
А вот всю самую важную магию по управлению сессиями и транзакциями берет на себя middleware. Ее очень просто подключить.
Вот пример для FastAPI:
Так же есть чистая ASGI middleware
Тестирование
Тестирование - очень важная часть разработки. Я предпочитаю тестировать с реальным живым postgresql. И в таком случае есть важная проблема, которую нужно решить - изоляция данных между тестами. И базово есть 2 подхода:
- удалять данные из бд между тестами. Тогда у приложения своя транзакция, у теста своя
- делать общую транзакцию между тестом и приложением, чтобы делать rollback
Первый подход очень удобен в отладке и иногда только с помощью такого подхода можно протестировать сложные сценарии где много транзакций открывается и закрывается. Или конкурентные запросы. Так же это "честный" способ тестирования. Мы проверяем как наше приложение работает с сессиями.
Но есть минус: долго выполняются. А все из-за очистки данных между тестами. Например это можно делать через truncate, но все равно по всем таблицам долго пробежаться.
Второй подход как раз наоборот очень быстрый за счет rollback, но не такой честный, потому что мы должны подготовить сессию и транзакцию для приложения заранее.
В своих сервисах я использую оба подхода сразу. Общая транзакция в большинстве тестов с простой логикой и меньшинство сложных тестов в отдельных транзакциях.
Библиотека предоставляет пару удобств для тестирования:
Первая из них это rollback_session - сессия, которая всегда будет откатываться в конце. Ее на самом деле в обоих видах тестов стоит использовать
А вот специально для тестов с общими транзакциями есть set_test_context и put_savepoint_session_in_ctx
Эта фикстура создаст контекст заранее. Таким образом приложение будет работать в этом контексте, а не будет создавать свое. А так же там будет лежать подготовленная сессия, которая вместо commit будет делать release save point.
Как все работает
Вот схема как все работает:
middleware инициализирует контекст. Ваше приложение приложение обращается к этому контексту через функции библиотеки. В конце middleware закрывает все незакрытое и закрывает контекст.
Как работает middleware:
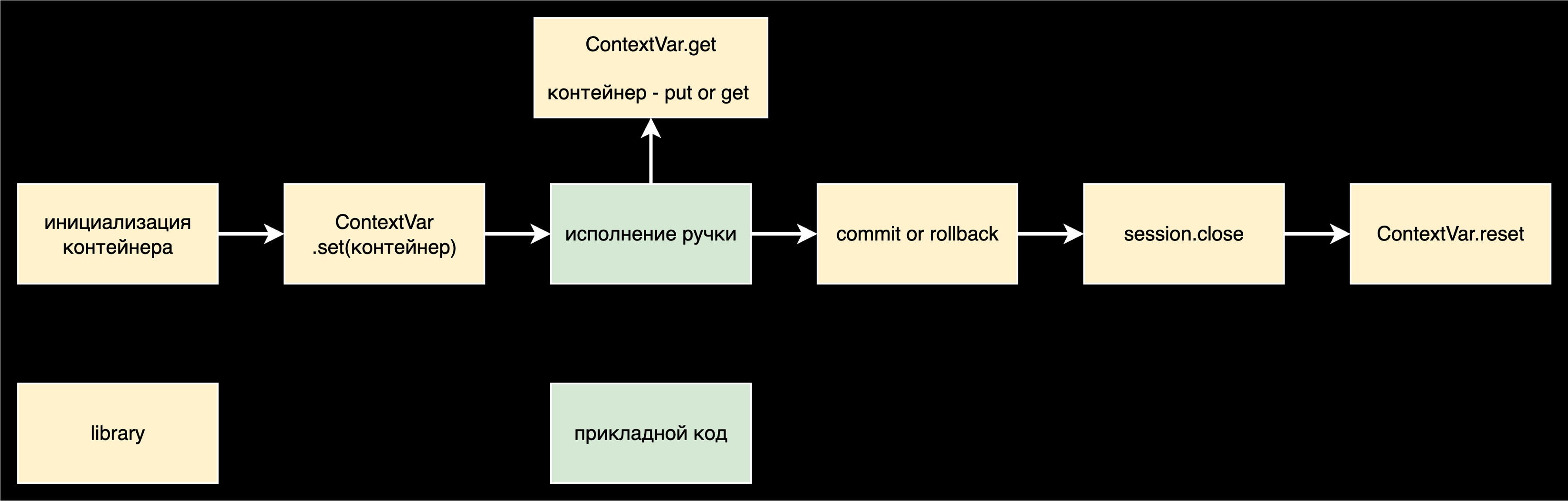
Тот самый контекст про который шла речь это ContextVar. В нем хранится мутабельный контейнер. Как раз когда ваше приложение обращается к библиотеки для получения сессии, библиотека работает с этим контейнером. И именно потому что контейнер мутабельный можно досрочно закрывать сессии и транзакции. Middleware будет работать только с тем, что осталось незакрытым в контейнере.
Итог
Подведем итог. Получилась классная либа, которая помогает работать с sqlalchemy:
- Мало кода без дублирования
- Автоматический commit или rollback, когда нет нужды вручную этим управлять
- Есть возможность ручного управления сессией и транзакцией
- Удобно для CRUD и удобно для сложных сценариев
- Не привносит новый синтаксис как обертки
- Не зависит от веб фреймворка
- удобно тестировать
Используйте!
- Библиотека доступна под MIT лицензией
- Открытый исходный код на github
- Есть документация
- Доступен в pypi
Я использую эту библиотеку в реальном production приложении. Так что смело используйте в любых своих проектах и приносите фидбэк! Я открыт к улучшениям, доработкам, замечаниям!
Не забудьте поставить звезду на github, если понравился проект! Спасибо!

