Как убрать ботов с помощью JavaScript, чтобы A/B-тесты были точнее
Как отличить людей от ботов в A/B-тестах с помощью JavaScript и сделать результаты статистически честными.

Адаптированный перевод статьи от редакции Tproger. Текст ведётся от первого лица. Автор оригинала Patrick McKenzie — разработчик библиотеки A/Bingo (open-source-инструмент A/B-тестирования на Rails).
Зачем вообще убирать ботов
Я из тех, кто не любит тратить время на фичи, пока не понятно, что они реально нужны пользователям. С open-source-проектами та же логика: не стоит всё усложнять, пока клиенты прямо не скажут, что им действительно нужно что-то посложнее (бывает, что такие клиенты способны помочь себе сами… по крайней мере, в теории).
Несколько месяцев назад один из пользователей моего проекта A/Bingo — библиотеки для A/B-тестов на Rails — попросил добавить возможность исключать ботов из подсчёта. Тогда все мои эксперименты были за формой регистрации, так что боты туда почти не попадали.
Я подумал: раз уж они не настолько умные, чтобы как-то смещать результат, то распределятся равномерно между вариантами. А раз мы измеряем не абсолютную конверсию, а разницу между вариантами, то влияние ботов должно нивелироваться само собой.
Эту мысль я и озвучил. Реакция была прохладной, и я ответил по классике: код под лицензией MIT, хочешь — форкни и добавь нужную фичу сам. Если некогда — я открыт для консультаций.
Тема всплывала ещё пару раз, но никто не был настолько мотивирован, чтобы оплатить мою работу. Пока недавно я не стал проводить серию сквозных A/B-тестов, где конверсией считалась покупка — и вот тут боты действительно оказались убийцами статистики.
Представим, что в среднем у меня около 2000 визитов в день и 5 покупок — для лета это нормальные цифры. Чтобы различить этот уровень конверсии и вариант, на 25 % лучше, потребуется примерно 56 000 визитов, то есть около месяца данных, чтобы достичь 95 %-го доверительного интервала. Отлично. Проблема в том, что A/Bingo фиксирует не 2000 визитов, а ближе к 8000 — потому что сайт постоянно штурмуют боты. В итоге измеренная конверсия падает с 0,25 % до 0,0625 %.
(Если кажется, что цифры низкие — не забывайте: это несезон, плюс я ранжируюсь по множеству длиннохвостых поисковых запросов, так что часть трафика в любом случае нецелевая.)
Влияет ли это вообще на статистику?
Теоретически я всё ещё думал, что раз боты не конвертируются по-разному между вариантами, то математически всё остаётся честным. Вот формула Z-статистики, которой я пользуюсь при проверке гипотез:
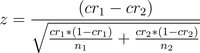
CR означает коэффициент конверсии (Conversion Rate), а n — размер выборки для двух альтернатив.
Если мы увеличим размеры выборок на некоторый постоянный коэффициент X, уравнение должно превратиться в:
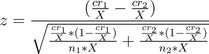
Из числителя можно вынести 1/X и перенести его в знаменатель — простая арифметика из начальной школы.

Теперь, благодаря магии алгебры старших классов:
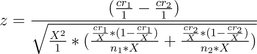
Если я здесь ошибся с математикой, команда математиков меня точно исключит:
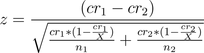
Если внимательно посмотреть на это, то это не то же уравнение, с которого мы начали. Как оно изменилось? Обратная величина коэффициента конверсии (1 – cr) стала ближе к 1, чем была раньше. (Это можно проверить, взяв предел при X, стремящемся к бесконечности.) Приближение к 1 означает, что числители знаменателя становятся больше, что означает, что знаменатель в целом становится больше, что означает, что Z-оценка становится меньше, что потенциально может навредить расчёту, который мы делаем.
Итак, предполагая, что я правильно выполнил алгебру, интуитивный ответ, который я давал людям месяцами, оказался неверным: боты действительно портят тестирование статистической значимости, искусственно занижая z-оценки и тем самым превращая статистически значимые результаты в нулевые результаты на грани.
Так что же мы можем с этим сделать?
Наивный подход: проверять User-Agent
Первое, что приходит в голову: просто отфильтровать ботов по User-Agent. Я тоже так думал. На практике это оказалось катастрофически неэффективно, по крайней мере, для тех ботов, которые атакуют мой сайт.
(Так как по ключевым словам мой сайт иногда попадает в серую тематику — вроде азартных игр, — я получаю массу лишнего внимания от скрейперов и парсеров.)
Проверка User-Agent убирала максимум половину трафика от ботов. Остальные продолжали участвовать в A/B-тестах, портя конверсии и статистику.
Более надёжный способ: заставить бота подумать
Можно было бы использовать CAPTCHA — но заставлять всех пользователей доказывать, что они люди, только ради чистоты A/B-тестов, мягко говоря, глупо.
Нужен полностью автоматический способ отличить человека от скрипта — без участия пользователя.
Решение, к счастью, уже есть: выполнение произвольного JavaScript-кода.
Пока Googlebot и ещё пара продвинутых ботов умеют исполнять JS, для большинства остальных это слишком дорого — и по ресурсам, и по сложности реализации. Написать скрипт на wget или через любую HTTP-библиотеку куда проще, чем имитировать полноценный браузер с движком JS.
(Да, Googlebot действительно умеет исполнять JavaScript. SEO-специалисты технического толка это хорошо знают: бот может частично выполнять код страницы, а иногда и полностью — как человек. Проверить это легко: поставьте в коде экспериментальный запрос, и Googlebot вскоре появится в логах по этому URL.)
Чтобы точно отличать людей от машин (и при этом не мешать Googlebot, который честно указывает свой User-Agent), нужно заставить браузер выполнить три простых задачи:
- Сложить два случайных числа. (Для браузера с JS это тривиально.)
- Сделать AJAX-запрос через Prototype или jQuery. (Подгрузить и выполнить эти библиотеки без реального движка JS почти невозможно.)
- Выполнить POST-запрос. (Googlebot на POST обычно не ходит. Он делает много GET-запросов и даже пытается угадывать параметры, чтобы обойти больше страниц — но POST для него запретная зона.)
Пример на Prototype
И в jQuery
На сервере мы принимаем параметры a, b и c и проверяем, что они образуют корректную тройку. Если всё сходится — считаем, что это человек. Если нет — продолжаем считать клиента ботом.
Можно было бы усложнить задачу, например, попросить вычислить MD5 от случайного значения, сохранённого в сессии, чтобы отсеивать ботов, которые пытаются просто повторить старый ответ. Но мне это не нужно: цель не в защите от злонамеренных атак, а в фильтрации большинства «безобидных» ботов, которые лишь засоряют статистику.
Никто не получает выгоды, ломая мои A/B-тесты, так что я не жду целенаправленных атак. Это не защита — просто средство наведения порядка.
Да, я исхожу из того, что пользователи умеют выполнять JavaScript. (Мой сайт без JS всё равно не работает.)
Так что если кто-то вроде Ричарда Столлмана с включённым NoScript не сможет участвовать в моих тестах — что ж, я переживу.
Как всё связать вместе
Теперь мы умеем отличать тех, кто действительно исполняет JavaScript, от тех, кто нет.
Осталась одна мелочь: браузер сообщает о своей человечности уже после того, как пользователь начал участвовать в A/B-тесте.
Это абсолютно нормальная ситуация. Например, человек заходит на первую страницу, где где-то внутри встроен тест. Он выполняет JS-код, который посылает на сервер доказательство, что он человек. Но делает это уже после того, как A/Bingo зарегистрировал его участие в тесте.
Решение оказалось простым.
A/Bingo и так отслеживает, в каких экспериментах пользователь уже участвовал, чтобы не считать его повторно. В «антибот-режиме» это поведение чуть меняется:
- система продолжает записывать участие и конверсии,
- но не добавляет их в общую статистику, пока пользователь не подтвердил, что он человек.
Когда подтверждение приходит (браузер выполнил JS и прошёл проверку), система просматривает все предыдущие тесты, где пользователь уже участвовал, и задним числом добавляет его участие в подсчёты.
Если кому-то интересно посмотреть, как именно это реализовано, код доступен для изучения — всё лежит на официальной странице проекта.
А если не хочется разбираться в деталях, а просто нужно быстро сделать свои A/B-тесты ботоустойчивыми, — посмотрите последнюю запись в FAQ. Там объясняется, как включить этот режим в один клик.
Другие применения
Этот приём с проверкой через JavaScript можно использовать не только в A/B-тестах.
У него есть и другие, вполне практичные применения.
1. Невидимая CAPTCHA для комментариев
С небольшой доработкой это превращается в CAPTCHA без взаимодействия с пользователем — отличное решение для блогов, форумов и любых форм обратной связи.
Принцип такой:
- все пользователи (и люди, и боты) сразу видят свой комментарий после отправки,
- но сайт публикует его только после того, как получит подтверждение JavaScript-выполнения.
Никаких галочек Я НЕ РОБОТ — просто задержка публикации, пока браузер не выполнит нужный код.
Можно сделать проверку чуть сложнее и добавить состояние на сервере, чтобы она была уникальной для каждого запроса.
Минус очевиден: ваш сайт, скорее всего, навсегда останется без комментариев от Ричарда Столлмана и других любителей NoScript.
Но, согласитесь, это не самая высокая цена за чистоту данных.
2. Автоматическое дискриминирование пользователей под нагрузкой
Ещё одна идея — всегда различать, кто человек, а кто нет. Когда сервер оказывается на грани по ресурсам, можно временно отключать тяжёлые функции для тех, кто ещё не доказал свою человечность.
Так вы избавитесь от резких просадок производительности из-за всплесков ботов и сможете спокойно выдерживать пики нагрузки.
А если ситуация критическая — можно вообще заблокировать ботов на время. Обычные пользователи этого даже не заметят.
3. Защита от разрушительных действий
И наконец, проверку можно использовать, чтобы предотвратить опасные или разрушительные операции.
Хотя, по-хорошему, такие действия и так должны быть защищены — спрятаны за POST-запросом и аутентификацией. Но дополнительная проверка на человечность нужна, особенно если ошибка может что-то удалить или повредить данные.
От редакции Tproger
Если вам понравился этот перевод — обсудите материал в комментариях.
Мы стараемся находить и адаптировать для вас лучшие тексты о разработке, данных и инженерном мышлении. Поделитесь своими мыслями: сталкивались ли вы с ботами, которые ломают аналитику, и как вы с этим справлялись?

