Код как у сеньора: рефакторинг
Разбираемся, чем отличается настоящий рефакторинг от банального переписывания кода на примере книги Мартина Фаулера «Рефакторинг».
Все мы знаем, что такое рефакторинг. Берешь невнятный кусок кода, выкидываешь и пишешь новый, быстрее, без багов… К сожалению, все не так просто. Давайте попробуем вместе разобраться, чем же отличается настоящий рефакторинг как практика от банального переписывания кода.
Это — первая серия проекта «Код Раковского», где Александр Раковский, Senior Java разработчик компании ITentika, расскажет о том, что считает важным и интересным в сфере программирования.

Каких-то жестких правил тут не будет, главное, запомните:
- Здесь не любят костыли и велосипеды.
- Здесь не терпят код без тестов.
- Здесь чтут отцов аджайла.
- Здесь суровое экстремальное программирование.
Возьмем пример из революционной книги Мартина Фаулера «Рефакторинг». Книге в следующем году 20 лет стукнет, поэтому пример оттуда сегодня будет смотреться необычно.
Этот небольшой проект, написанный на Java — программа для печати чека клиенту в видеопрокате. Исходники кода можно взять тут.
Она выводит арендованные фильмы и стоимость их аренды и рассчитывает общую сумму, которую должен клиент, при этом в чек выводятся баллы программы лояльности. Проект специально наполнен кучей огрехов, которые в книге называются Code Smell — так имитируется кусок кода типичного корпоративного приложения. В рамках примера нам надо будет добавить пару фич, для чего мы и проведем небольшой рефакторинг.
Что мы будем рефакторить?
Давайте посмотрим на структуру кода.
Наш проект состоит из 4 классов: главного класса, класса клиента, класса аренды и класса фильма.
В главном классе мы создаем фильмы и записи об их аренде, вызываем метод вычисления счета и выводим результат на экран.

В классе клиента есть только метод вычисления счета — это, по сути, единственная логика во всей программе. Ее-то мы и будем рефакторить.

Для вычисления счета этот класс оперирует данными аренды и фильма. Это, по сути, классы данных, не содержащие в себе никакой логики: аренда содержит в себе ссылку на фильм и срок аренды, фильм содержит в себе название и тип фильма: обычный, детский или новый релиз.


Давайте представим, что нам надо добавить две новые фичи. Во-первых, клиент хочет вывод еще и в HTML. Во-вторых, клиент хочет добавить другие типы фильмов — например драмы, комедии, триллеры. В текущую структуру эти правки ложатся с трудом, поэтому нам придется ее изменить.
Длинные и короткие методы
Первый код-смелл, который тут же бросается в глаза — длинный метод. Нередко приходится слышать, что длинные методы — это удобно, ведь все на виду, а при чтении кода, состоящего из множества мелких методов, кажется, что никакого вычисления не происходит вовсе — весь код превращается в цепочку делегирований.

Так в чем же тогда проблема длинных методов? Основных проблем две:
- Обычно весьма трудно разобраться, что в них происходит.
- Если метод уже стал большим по какой-то причине, то, скорее всего, по этой же причине он и будет расти дальше. Уверен, многие из вас видели «монстров» по несколько сотен и даже тысяч строк.
В то же время короткие методы имеют серьезные преимущества перед длинными:
— Понятный код. Если вы хорошо называете методы, то вашему коду не нужны никакие комментарии — вместо них будут работать имена.
— Простая навигация. Хорошие названия работают как оглавление. Вам не надо читать всю книгу, чтобы понять, в каком месте ее открыть.
— В конце концов, короткие методы больше способствуют переиспользованию кода.
Ну хорошо, а как понять, что метод длинный?
— Если встал вопрос, значит, скорее всего, длинный.
— Если вопрос не встал — метод, скорее всего, тоже длинный. Ведь в реальных кодовых базах есть очевидное преобладание длинных методов над короткими.
— Если за несколько секунд не удалось понять, что происходит в методе — он длинный.
— Наконец, если в нем больше 10-12 строк — абсолютно точно длинный. Хорошая длина метода — от одной до 3-4 строк.
Что же делать с длинным методом? В 99% случаев — извлекать из него маленькие методы. Извлечение метода должно стать первым инструментом на пути к более чистому коду. Первое, что делает любой программист, научившийся настоящему рефакторингу — начинает безудержно извлекать методы по поводу и без. И именно тогда он и понимает все преимущества коротких методов.

Что извлекать? Подсказками будут циклы, условные операторы и комментарии. Также стоит смотреть на места с высокой плотностью обращения к одной и той же переменной.
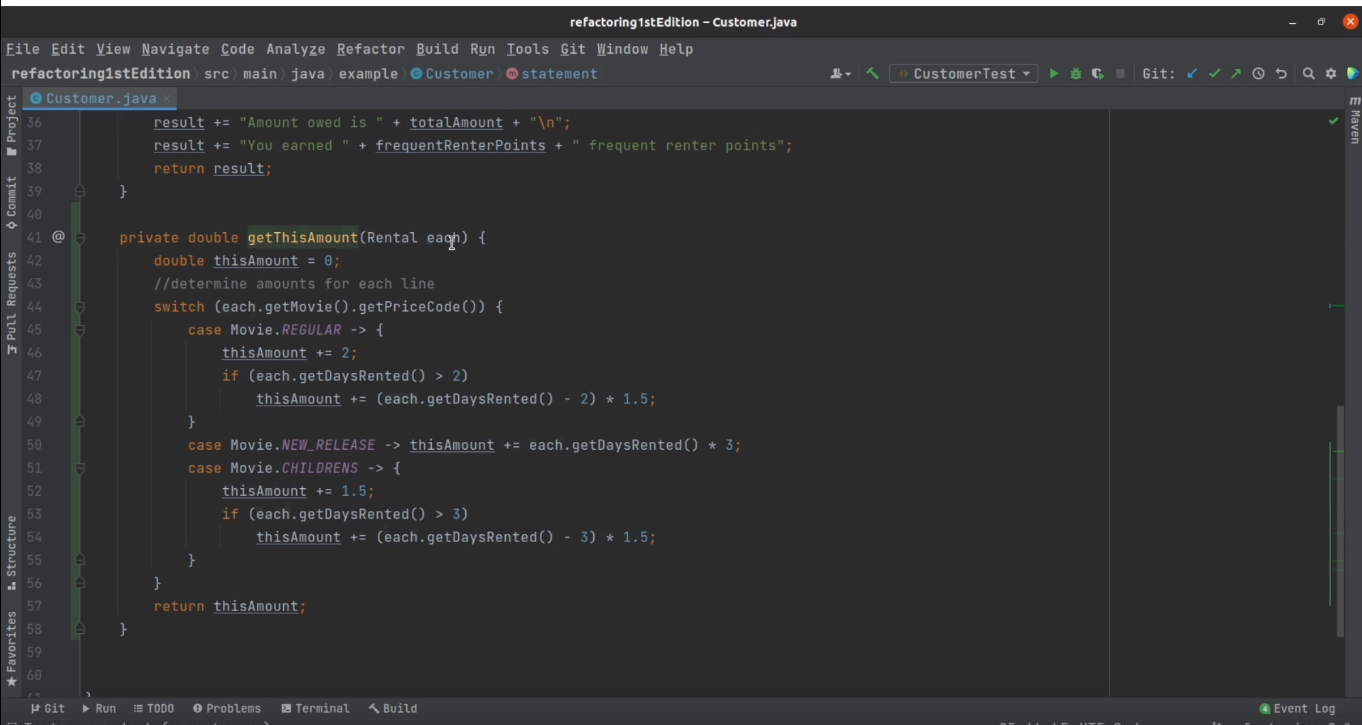
После каждого рефакторинга я обязательно проверяю, что тесты все еще зеленые, и сохраняю прогресс в системе контроля версий. Это позволит откатиться обратно в случае красных тестов.
Feature Envy
Следующий код-смелл Feature Envy в русском переводе называется «завистливая функция». Весь смысл объектов в том, данные живут вместе с поведением, однако часто приходится видеть, как метод заинтересован больше в чужом классе, чем в своем. Вот и в нашем случае метод getCharge активно использует данные класса Аренды, а вот методы и поля же собственного класса он попросту игнорирует.

К счастью, решение очевидно: если ваш волк смотрит в лес — отпустите его туда. То есть, если метод getCharge так интересуется с классом аренды, то, собственно, там ему и место. Давайте перенесем уже, наконец, этот метод в его новый дом. Для этого воспользуемся автоматическим рефакторингом.
Локальные переменные
Следующее проблемное место в коде — это изобилие локальных переменных. Это не то чтобы код-смелл, скорее просто верный спутник длинных методов. Прочесть локальную переменную можно только в области их видимости. Это и есть причина роста этой самой области и, как следствие, появления длинных методов.
Другая беда в том, что переменная может не раз изменить значение в течение своей жизни, тем самым неприятно удивив разработчика. Это ее свойство — неиссякаемый источник багов, которые потом может быть сложно отладить.
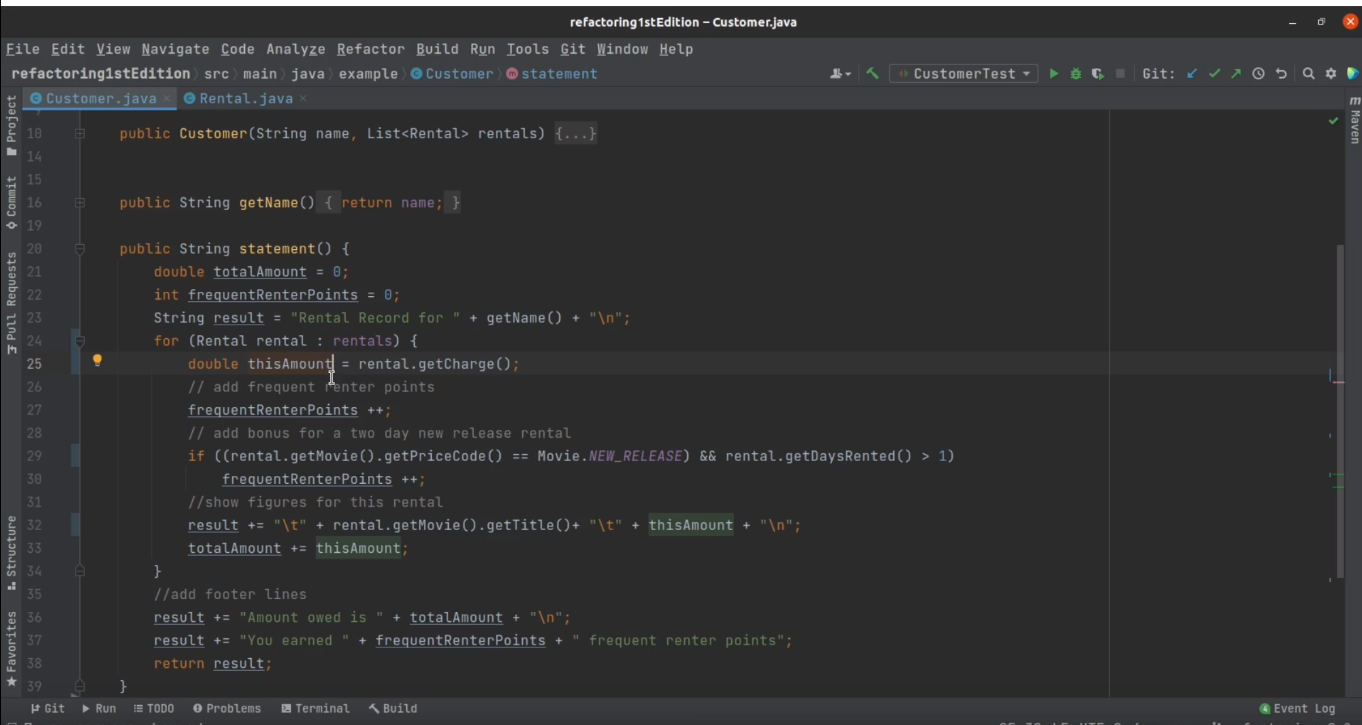
Чтобы избавиться от локальной переменной, мы воспользуемся методом рефакторинга «Встраивание переменной».
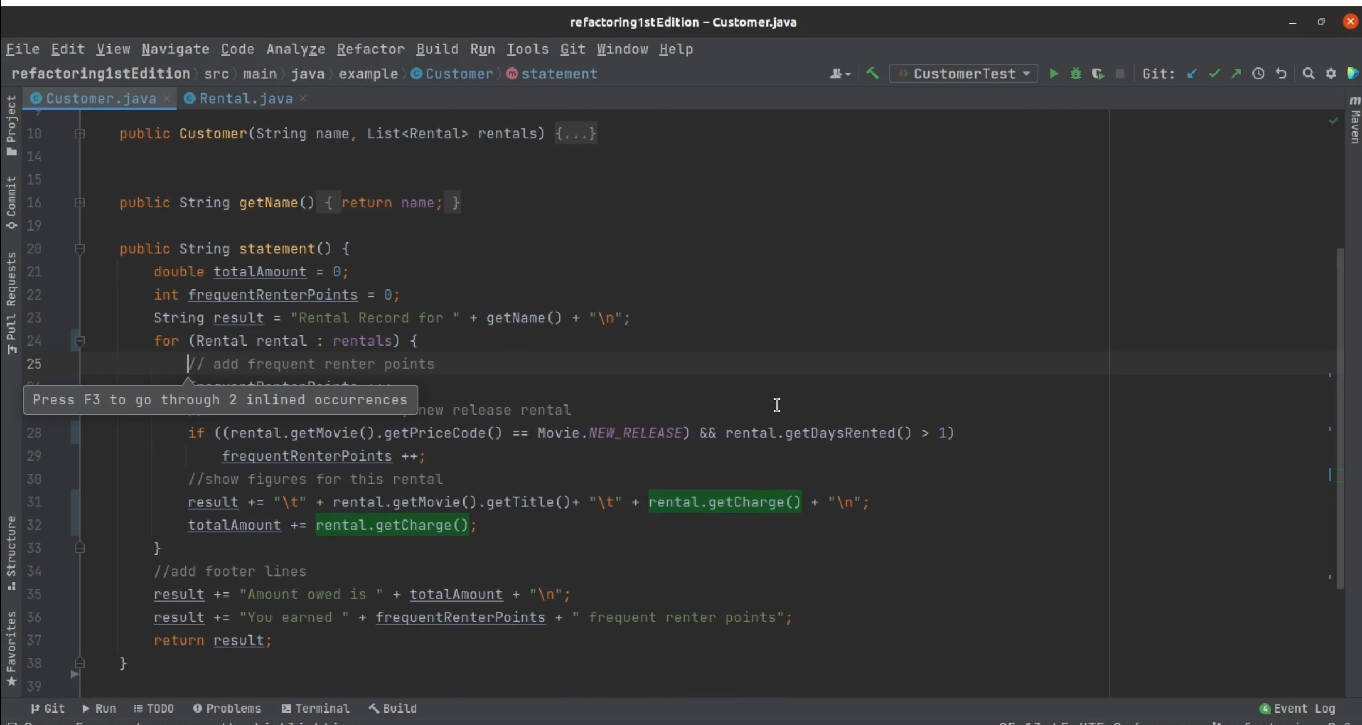
Кто-то может возразить, что мы таким образом снижаем производительность нашей системы. Действительно, вместо одного раза метод вызывается дважды — так что озабоченность понятна, но не рациональна.
О производительности можно и нужно разговаривать. Но, во-первых, только тогда, когда это действительно требуется, во-вторых, исключительно имея реальные замеры кода. То есть оптимизация — это отдельная работа, направленная на устранение бутылочных горлышек. В реальной практике я отказываю себе во встраивании переменной только в случае работы с файловой системой, сетью, ну или если у метода есть сайд-эффект.
Продолжаем декомпозировать длинный метод
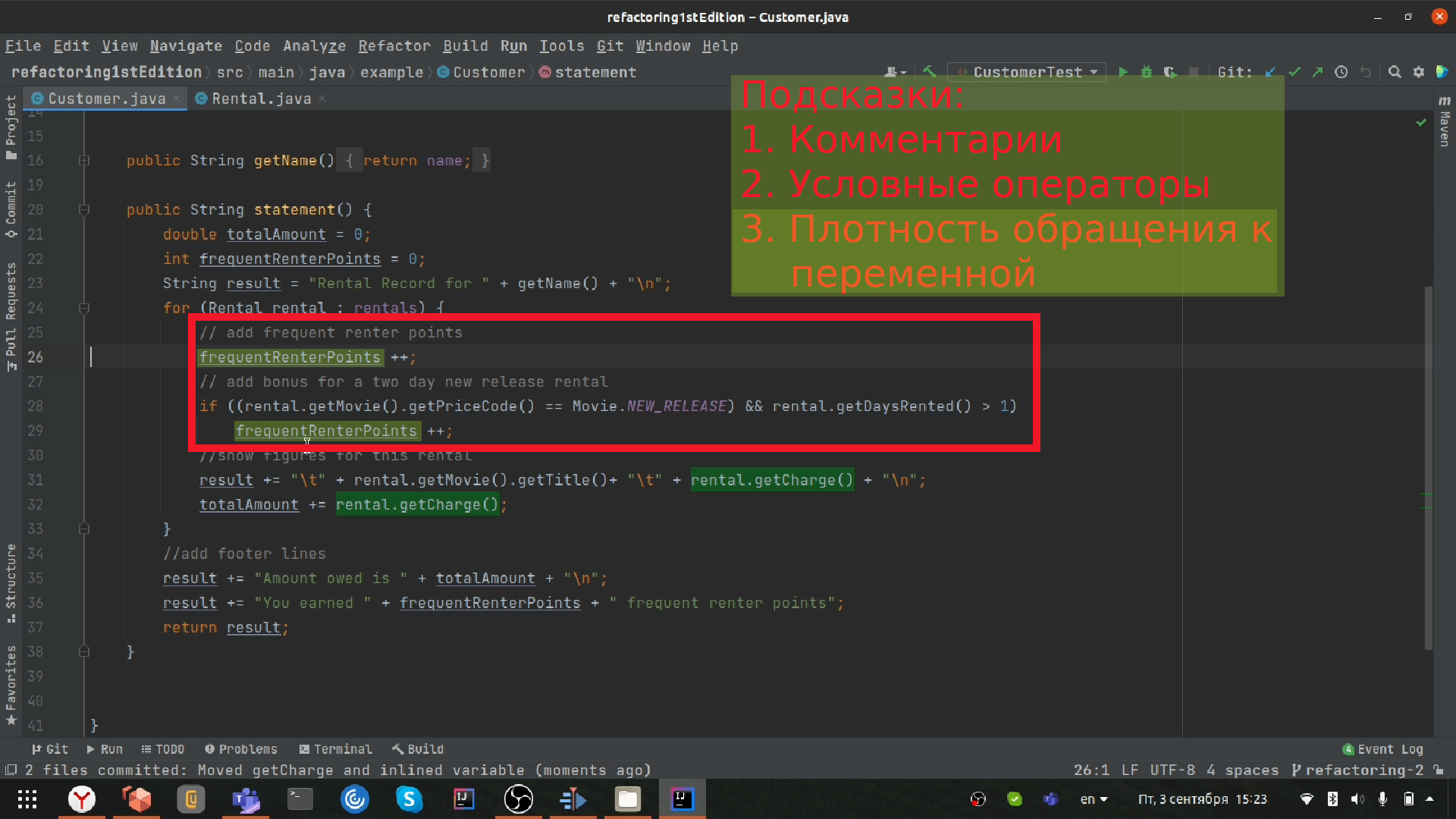
Следующий на очереди к извлечению у нас кусок кода, рассчитывающий очки лояльности, так называемые рентер-поинты.
Разделение цикла
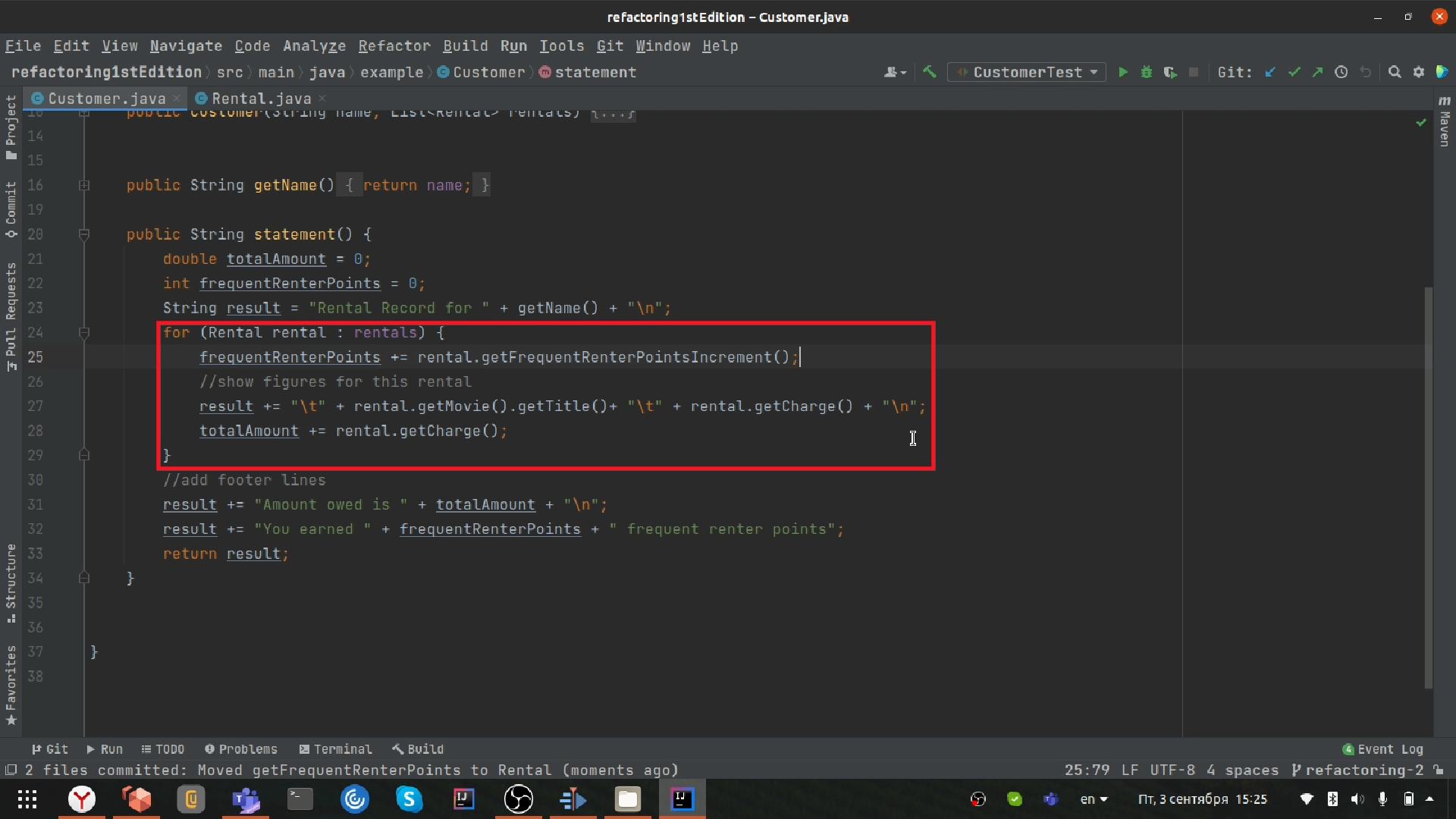
В этот раз мы воспользуемся методом рефакторинга под названием «Разделение цикла». Он нужен для того, чтобы декомпозировать один цикл на несколько более маленьких циклов.
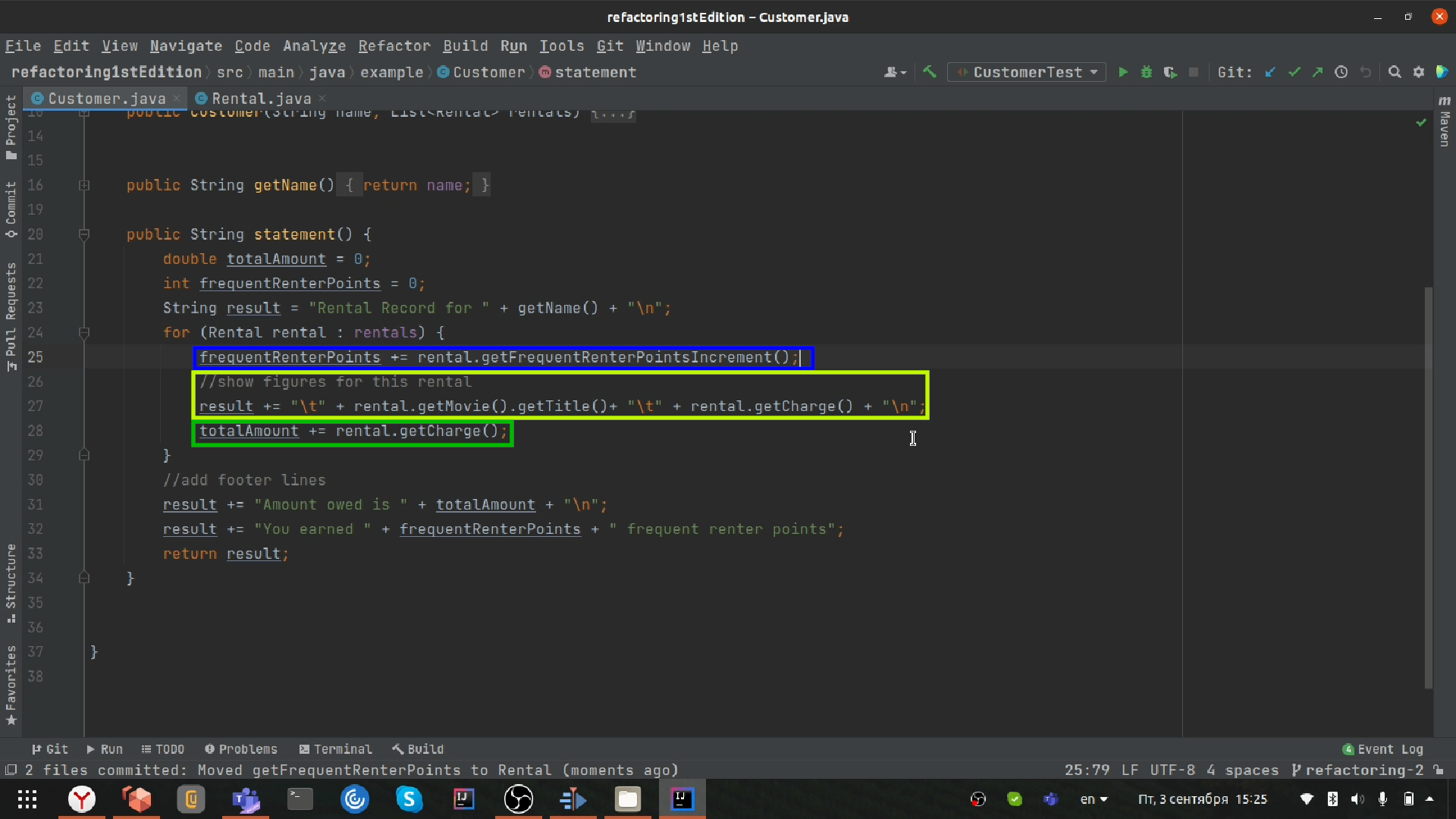
Это снова может вызвать озабоченность по поводу производительности. Ответ будет тот же самый: без замеров и реальной необходимости в оптимизации, рассуждать о производительности бессмысленно. Оптимизация — это отдельная от рефакторинга задача, которую заметно легче решать, если ваш код хорошо структурирован.
Как только мы разделили цикл на несколько, мы можем извлечь цикл в новый метод.
Замена цикла конвейером
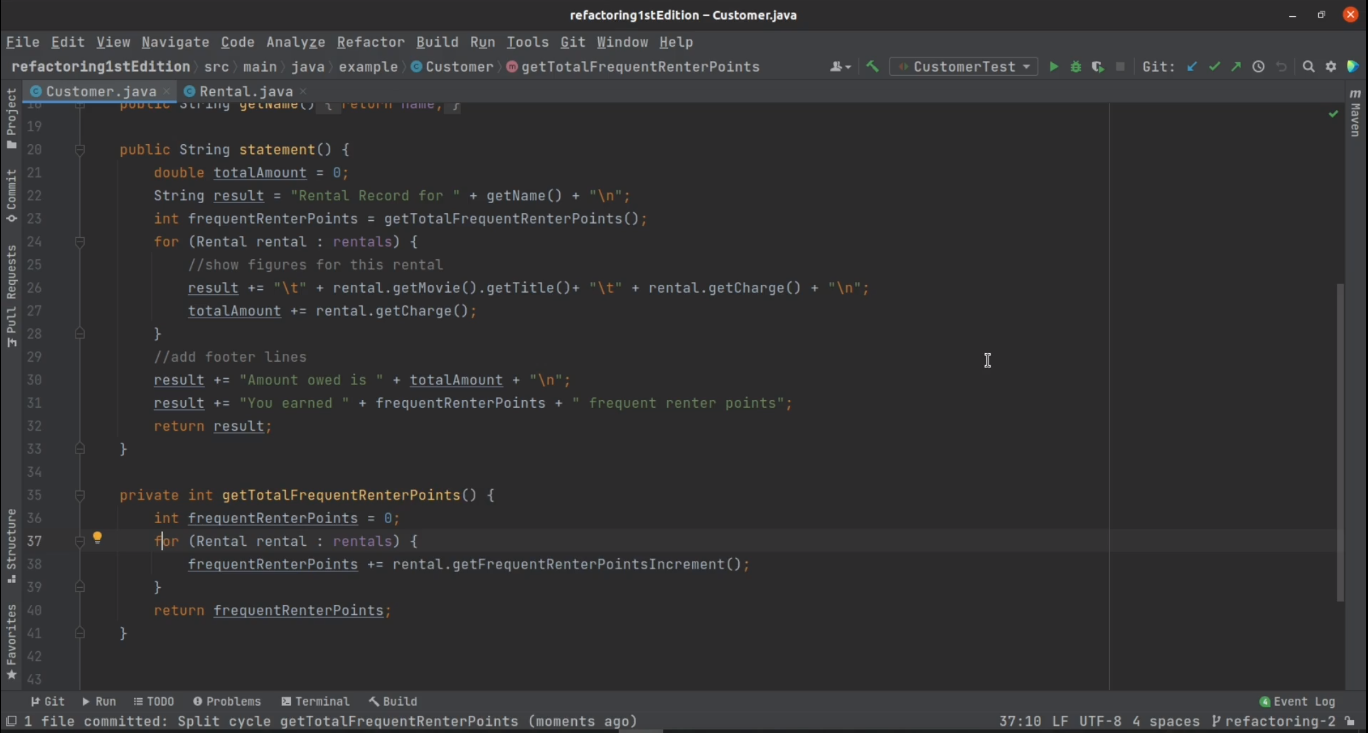
Следующий рефакторинг — замена цикла конвейером, он просто приводит ваш цикл к функциональному стилю. С одной стороны, это чистая вкусовщина. С другой стороны, замена цикла конвейером позволяет вам избавиться от локальных переменных и держать ваши циклы как можно более короткими. Впрочем, должен признать, что содержимое подобных конвейеров иногда бывает трудно прочесть.

На этом этапе уже можно встать на паузу и посмотреть на получившийся код. У нас есть метод, собирающий текст итогового счета, и есть отдельные методы, которые считают нужные нам данные. Этого нам УЖЕ достаточно, чтобы добавить новую фичу вывода данных в HTML. По сути, все, что осталось в этом коде — заменить текстовые строки на HTML-теги.

Switch case
Приступим к внедрению второй фичи: нам нужно добавить еще несколько типов фильмов. Мы могли бы поступить следующим образом: добавить новый код, например «драма», пойти в класс аренды и в switch-case добавить отдельное условие. И, если потребуется, добавить еще одно условие в метод расчета очков лояльности.
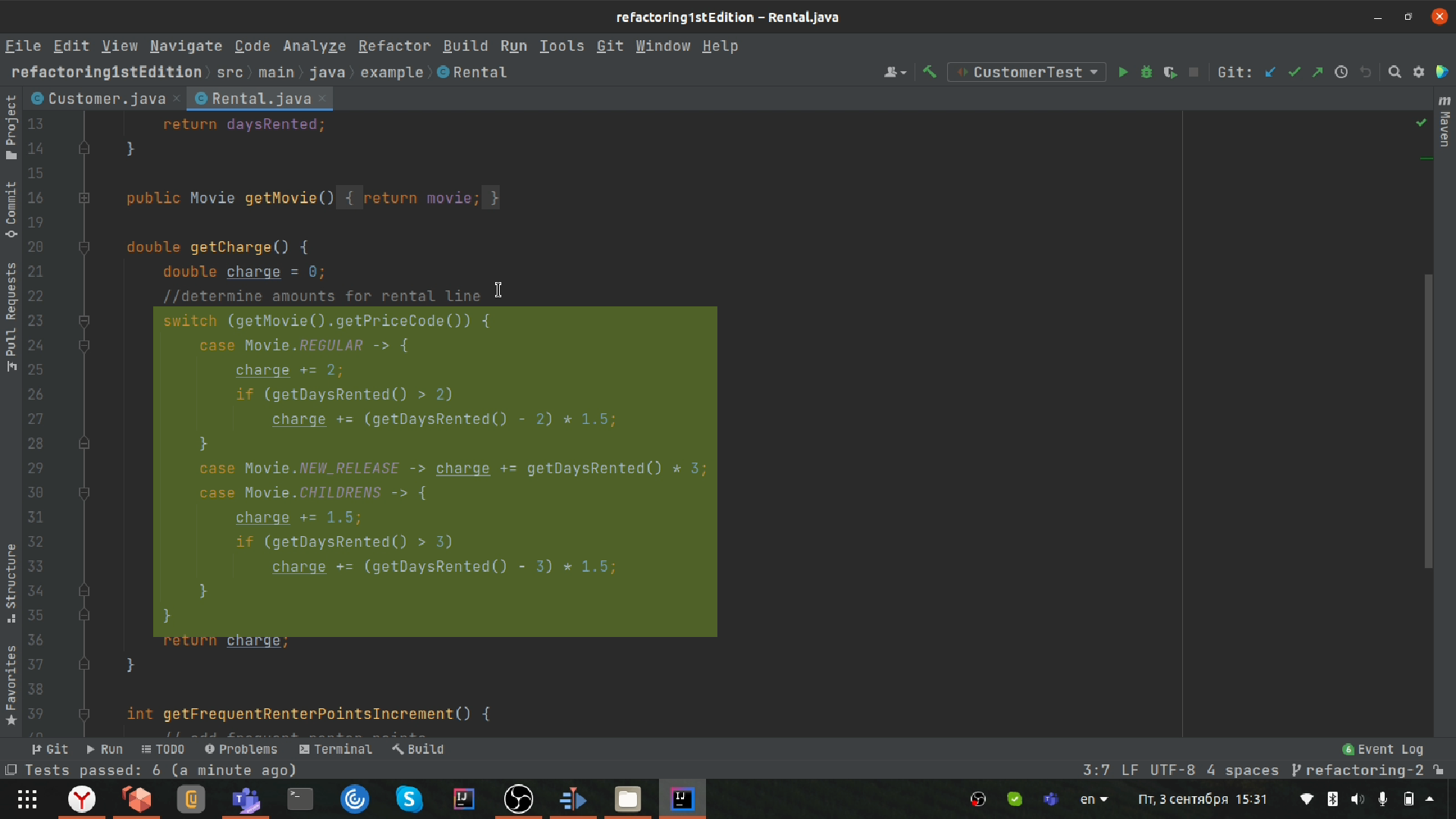
Здесь на нашем пути встает еще один код-смелл: switch-case. Это канонический пример нарушения Open-Closed принципа из всем известных SOLID-принципов.
Главная проблема свитч-кейсов кроется в дублировании: часто мы находим один и тот же свитч-кейс, разбросанный по всему коду, и при добавлении нового условия необходимо потом мучительно искать все эти свитчи. Другая проблема кроется в том, что при каждом новом условии нам придется расширять этот свитч и добавлять в него логику. Думаю, многим доводилось видеть подобные свитчи, разросшиеся на целые сотни строк.
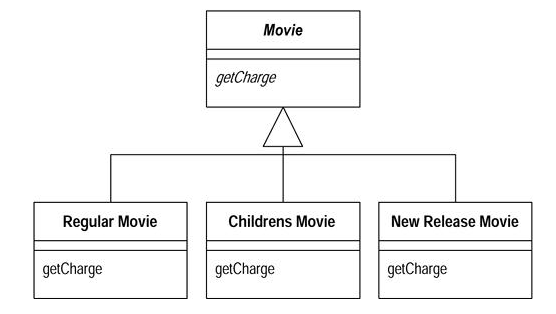
Решением этой проблемы становится полиморфизм. В данном случае мы можем создать нескольких наследников для класса «фильм», перегрузив метод расчета чека. То есть, это будут классы Regular Movie, Children’s Movie и NewReleaseMovie
Но есть одна проблема. Мартин Фаулер, автор книги и нашего примера, пишет, что схема с полиморфным фильмом всем хороша, но не всегда работает. По его словам, фильм в течение своей жизни может менять свой тип: новый релиз может перестать быть таковым и просто стать детским. Взамен Мартин предлагает воспользоваться шаблоном проектирования State Pattern: в класс Movie будет добавлено поле Price с тремя наследниками: RegularPrice, ChildrensPrice и NewReleasePrice.
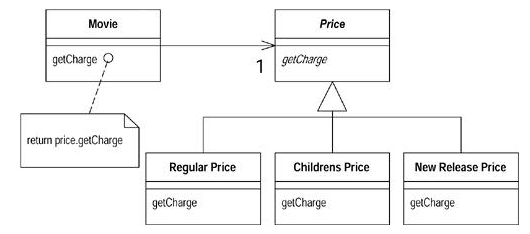

Теперь добавление нового типа фильма превратилось в банальное создание нового класса с перегрузкой одного или двух методов.
«Что дальше?»
Давайте посмотрим на первоисточник.
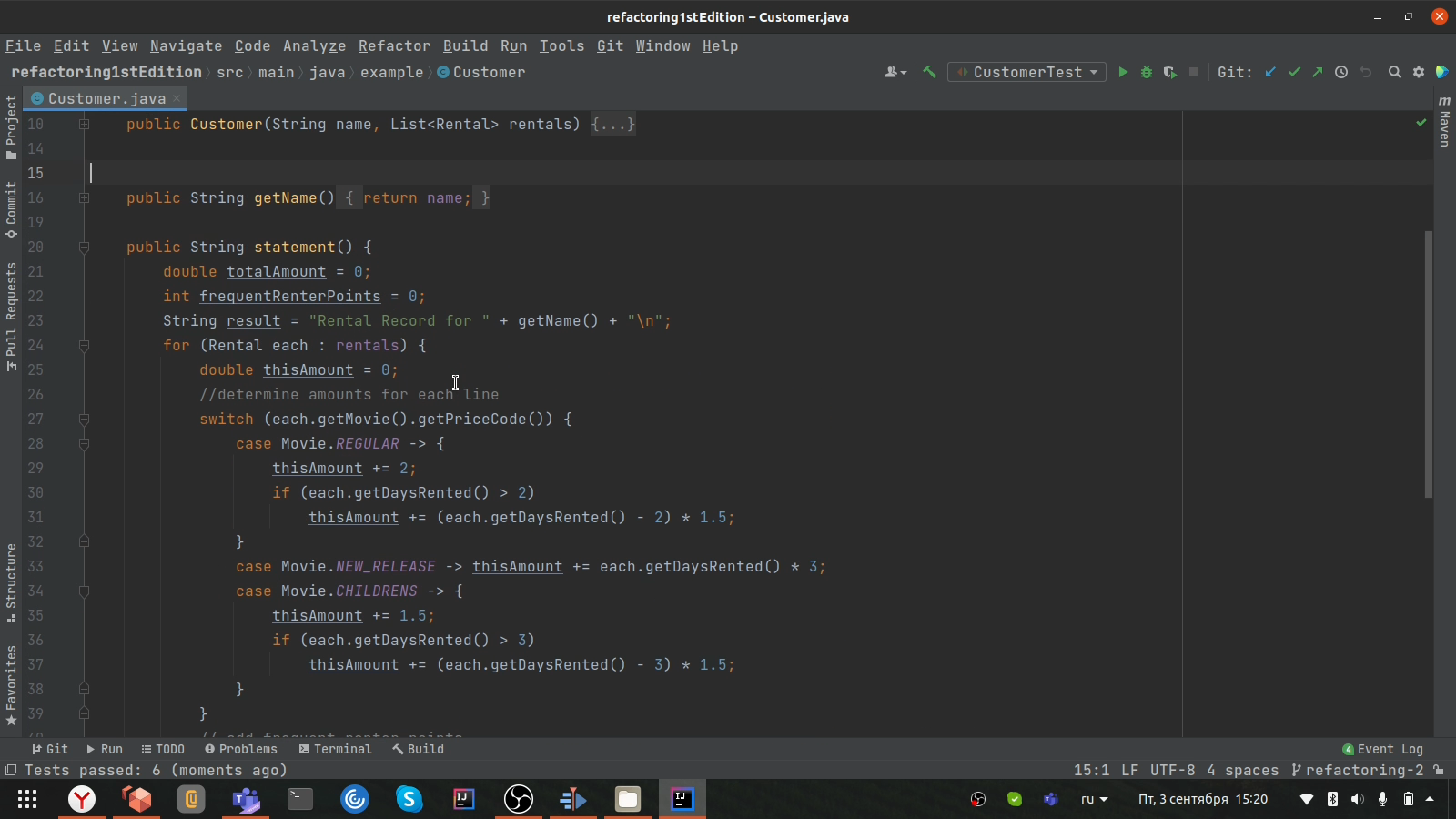
Единственным способом добавить в него HTML-вывод было бы просто скопировать тело метода и заменить текст на теги. Но в таком случае при каждом изменении правил ценообразования или при добавлении нового жанра нам пришлось бы править все в двух местах. А добавляя новые жанры в этот метод, мы бы сделали его огромным и неподдерживаемым источником багов. Теперь этот код выглядит так:
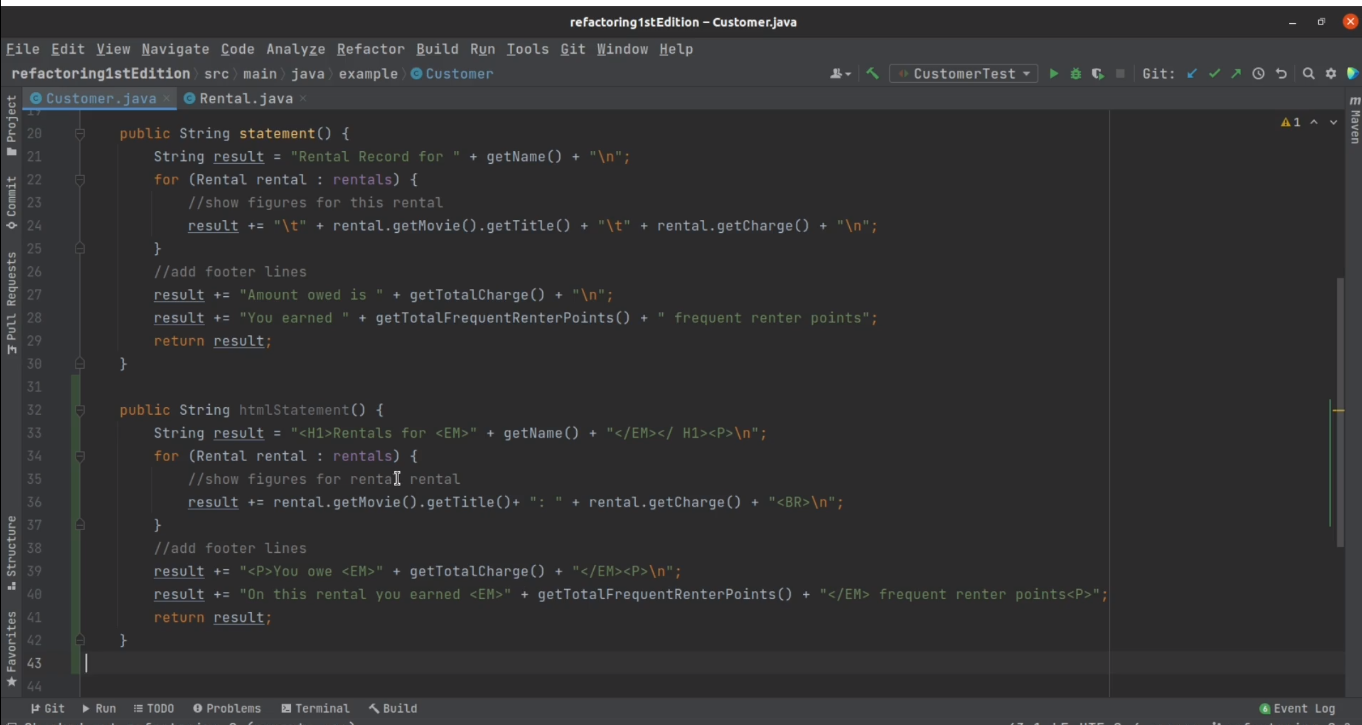
Самое примечательное, что в процессе рефакторинга мы не придумывали хитрые решения, не разрабатывали сложные схемы, чтобы добавить новые фичи. Все, что мы делали, — просто устраняли код-смеллы. И в результате каждая новая фича сама собой ложилась в структуру кода. Именно эта способность хорошо отрефакторенного кода принимать новые фичи — главное преимущество рефакторинга. Потратив немного времени на рефакторинг сейчас, вы втрое сэкономите себе время потом, когда вам понадобится новая фича.
Перечисленных здесь код-смеллов и методов рефакторинга хватает для большинства задач.
Тесты и требования к ним
Однако этих знаний недостаточно, чтобы можно было сразу браться за рефакторинг реальной кодовой базы. Во-первых, для такого рефакторинга нужны весьма конкретного вида тесты. Во-вторых, необходимо понять, как встроить рефакторинг в свой рабочий процесс — то есть ответить на вопросы: когда его делать и как договориться об этом с другими.
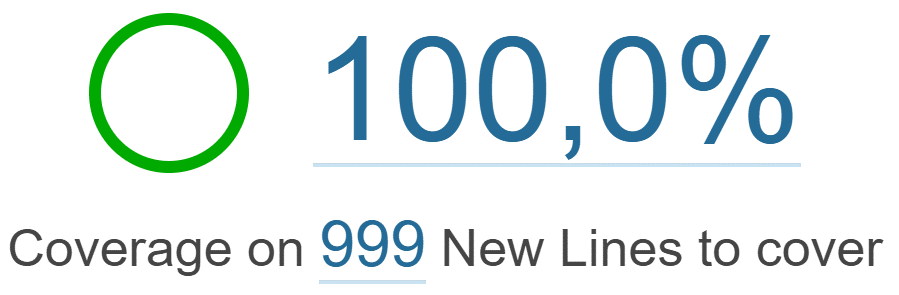
Начнем с тестов. Первая проблема современных кодовых баз — уровень покрытия. В командах обычно принято какое-то правило, например «80% покрытия тестами», что сразу вызывает вопрос: неужели это нормально, что 20% программы не работает?
Конечно, нет. Рефакторинг требует уверенности.
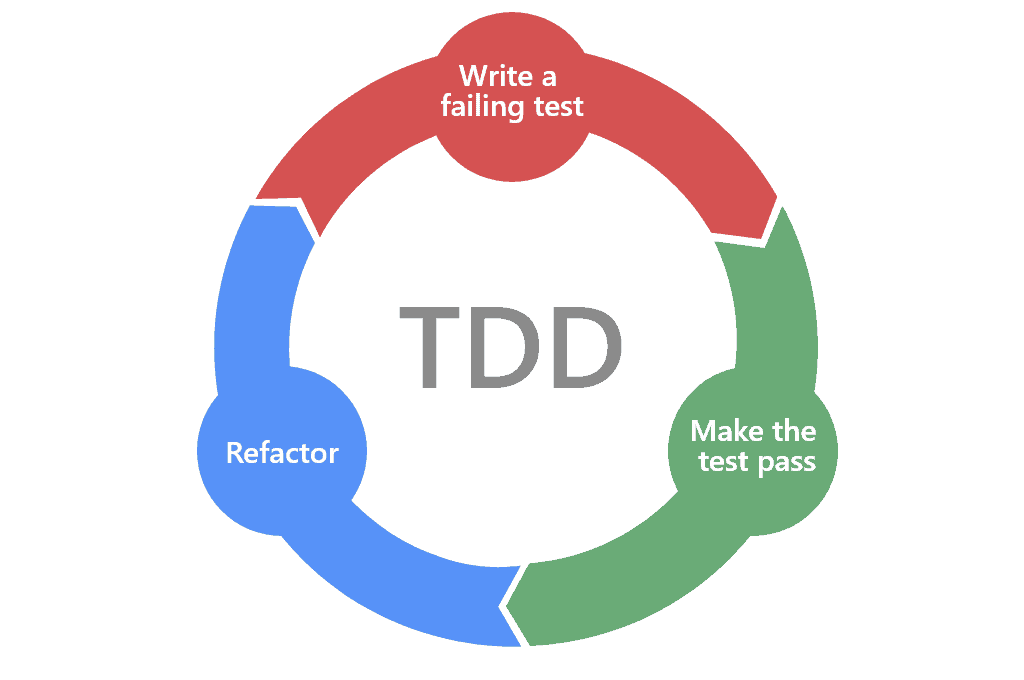
Самый лучший способ добиться полного покрытия — просто не писать код, на который не написан тест. Это может звучать невероятно глупо, но, поверьте, это работает, и работает очень круто. Этот подход, описанный Кентом Беком, называется Test-Driven Development.
Второе требование к тестам — тесты не должны быть хрупкими!
Помню, как я смотрел свой первый курс лекций по юнит-тестам. Именно там я узнал, что в словосочетании юнит-тест «юнит» — это класс. Я начал писать классы парами: продакшн класс и тестовый класс. Все взаимодействия с другими классами в такой ситуации необходимо было закрывать моками. Потом, прочитав книжку по рефакторингу, я начал активно рефакторить все подряд. И какова же была моя боль, когда при каждом переносе метода или извлечении класса мне приходилось мучительно переписывать тесты.
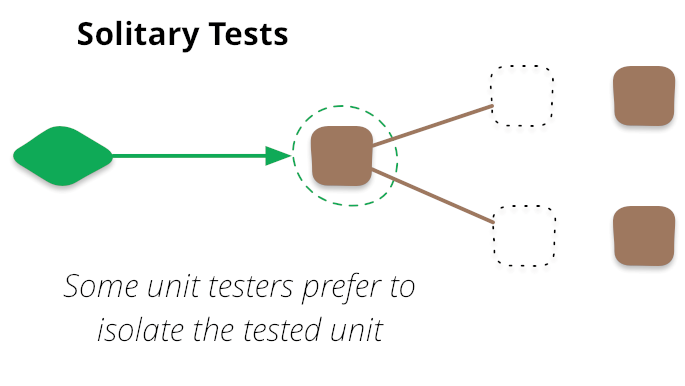
Так я впервые столкнулся с проблемой «хрупких тестов». Тесты не помогали рефакторить, как предполагалось. Наоборот, они невероятно сильно мешались под ногами. Это очень глупая ситуация, ведь тесты только для того и нужны, чтобы быть уверенным, что поведение написанного кода не изменилось при редактировании. А это и есть определение рефакторинга — изменение кода без изменения поведения. В итоге я попал в ситуацию, когда тесты свою задачу практически не выполняли.

Через некоторое время я узнал, в чем была проблема. Уже упомянутые Мартин Фаулер и Кент Бек, как оказалось, пишут тесты совсем иначе. В словосочетании «юнит-тест» для них слово «юнит» означало не «класс» и не «метод», а «поведение» — наименьший неделимый фрагмент функциональности.
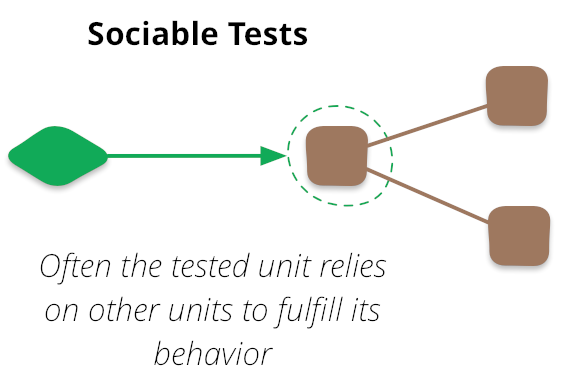
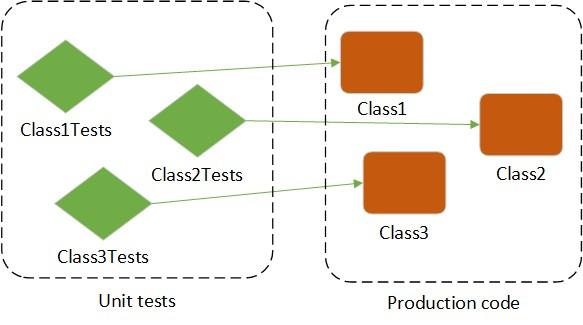
Они не глушили тестируемый класс со всех сторон: наоборот, такие юнит-тесты проверяли целые связки классов. Это не значит, что они не использовали заглушки и моки, просто заглушки использовались только для замены внешних слоев приложения, не относящихся к бизнес-логике, то есть глушились классы взаимодействия с базами, очередями, вебом и иными внешними системами, а также, например, пользовательский интерфейс — другими словами, слои ввода и вывода данных.
Покажу на примере. Возьмем типичное корпоративное приложение со множеством интерфейсов ввода и вывода. В центре такого приложения всегда лежит бизнес-логика. Код, связывающий бизнес-логику со внешними системами, упакован в отдельные слои — gateway. Это могут быть репозитории, DAO, или, например, сложный клиентский код внешней системы.
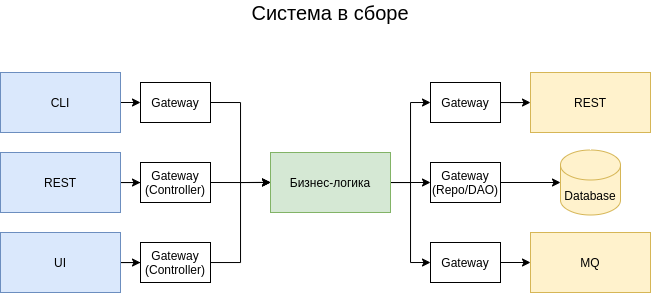
Все, что необходимо глушить для того, чтобы тесты не мешали рефакторингу — это gateway. А чтобы код самих gateway тоже можно было рефакторить, пишутся отдельные тесты — интеграционные.
Как встроить рефакторинг в свой рабочий процесс?
Обычно самый первый вопрос — как правильно выделить время под рефакторинг. Заводить ли для этого отдельные таски и когда рефакторить, если фичи в приоритете?
Ответ такой: рефакторинг должен проводиться непрерывно на всем этапе разработки.
Обычно это выглядит так:
— Вы взяли задачу и начали читать код. На этом моменте обычно вам уже придется что-то подрефакторить.
— Потом вы приступили к разработке. Буквально через 5-10 минут, максимум полчаса-час, у вас должен быть рабочий кусок кода, покрытый тестом. Тут же надо его рефакторить.
— Снова разработка, снова покрытый тестами кусок кода через непродолжительный отрезок времени.
И такими вот циклами и движетесь вперед до решения задачи. Как только вы наткнулись на кусок кода, в который ваша фича не лезет никак — останавливаетесь в прогрессе и начинаете рефакторить.
Если вы делаете это в парадигме TDD, то этот подход будет называться Red-Green-Refactor. То есть сначала пишете красный тест на какой-то фрагмент функционала, потом пишете код, который делает ваш тест зеленым, потом рефакторите.
Отсюда и следуют ответы на другие вопросы:
— Заводить ли под рефакторинг отдельные таски?
— Нежелательно, запланированный рефакторинг должен быть вынужденной редкостью, а не постоянной практикой.
— Когда рефакторить, если надо делать фичи?
— Плохой код делает вас медленнее. Поэтому рефакторинг — это один из главных способов ускорить доставку новых фич. Но в плохой кодовой базе очень легко погрязнуть в рефакторинге надолго, поэтому и было придумано правило бойскаута: просто оставляйте код в лучшем состоянии, чем он был до вас. И рано или поздно вы обнаружите себя во вполне чистой кодовой базе.
Как договориться с коллегами?
Может оказаться, что менеджеру не понравится, что вы ковыряетесь в старом коде вместо того, чтобы делать новый. А может быть, и коллегам не понравится, что вы трогаете старый код с риском сломать его — особенно если это их код.
Что ж, самое простое тут — это менеджер. Рефакторинг — способ двигаться быстрее, так что можно попробовать зайти с экономической стороны вопроса. Но, в целом, можете просто ничего про рефакторинг не рассказывать, не его это дело. Фича готова? Готова. А как именно — это уже детали реализации. Самое главное — помнить, что вы профессионал и вам лучше видно, как делать свою работу.
Если против вас ополчилась команда и договориться не удалось никак, то тут все плохо. Обычно такие глубокие разногласия приводят к разводам — кто-то уходит, а кто-то остается. Вопрос лишь в том, кто у руля.
На этом мы, пожалуй, и закончим знакомство с НАСТОЯЩИМ рефакторингом.
И теперь у вас уже достаточно инструментов, чтобы безопасно и качественно приводить свою кодовую базу в порядок.

20К открытий21К показов
Объяснили localStorage и его методы. Рассказали, как использовать localStorage для сохранения, доступа, удаления и изменения данных.

Максим Арокен делится советами с чего начать изучение веб-разработки, как не забросить в самом начале и какую дополнительную технологию изучить, чтобы легче находить заказы на фрилансе.

Рассмотрели инструменты CSS для создания дизайна в стилях неоморфизма и глассморфизма, генерации сеток, макеток и CSS-анимаций.
Президент UFC Дана Уайт заявил, что Илон Маск и Марк Цукерберг "абсолютно смертельно серьезно" настроены сразиться друг с другом на UFC.