Google открыла доступ к самой большой базе мировых достопримечательностей Google-Landmarks

В рамках соревнований по машинному обучению от Kaggle Google открыла доступ к двухмиллионной базе мировых памятников культуры Google-Landmarks. На её основе участникам предстоит разработать системы для распознавания и поиска достопримечательностей.
1 марта Google открыла доступ к большой базе данных для распознавания мировых памятников искусственного и природного происхождения. Набор «знаний» получил название Google-Landmarks и представлен в рамках соревнований от Kaggle на лучшие системы по распознаванию и поиску достопримечательностей.
Особенности Google-Landmarks
Набор данных содержит более 2 миллионов изображений, описывающих около 30 тысяч уникальных культурных памятников со всего мира. Количество классов, на которые разбиты картинки, примерно в тридцать раз больше, чем обычно используется в базах для распознавания.
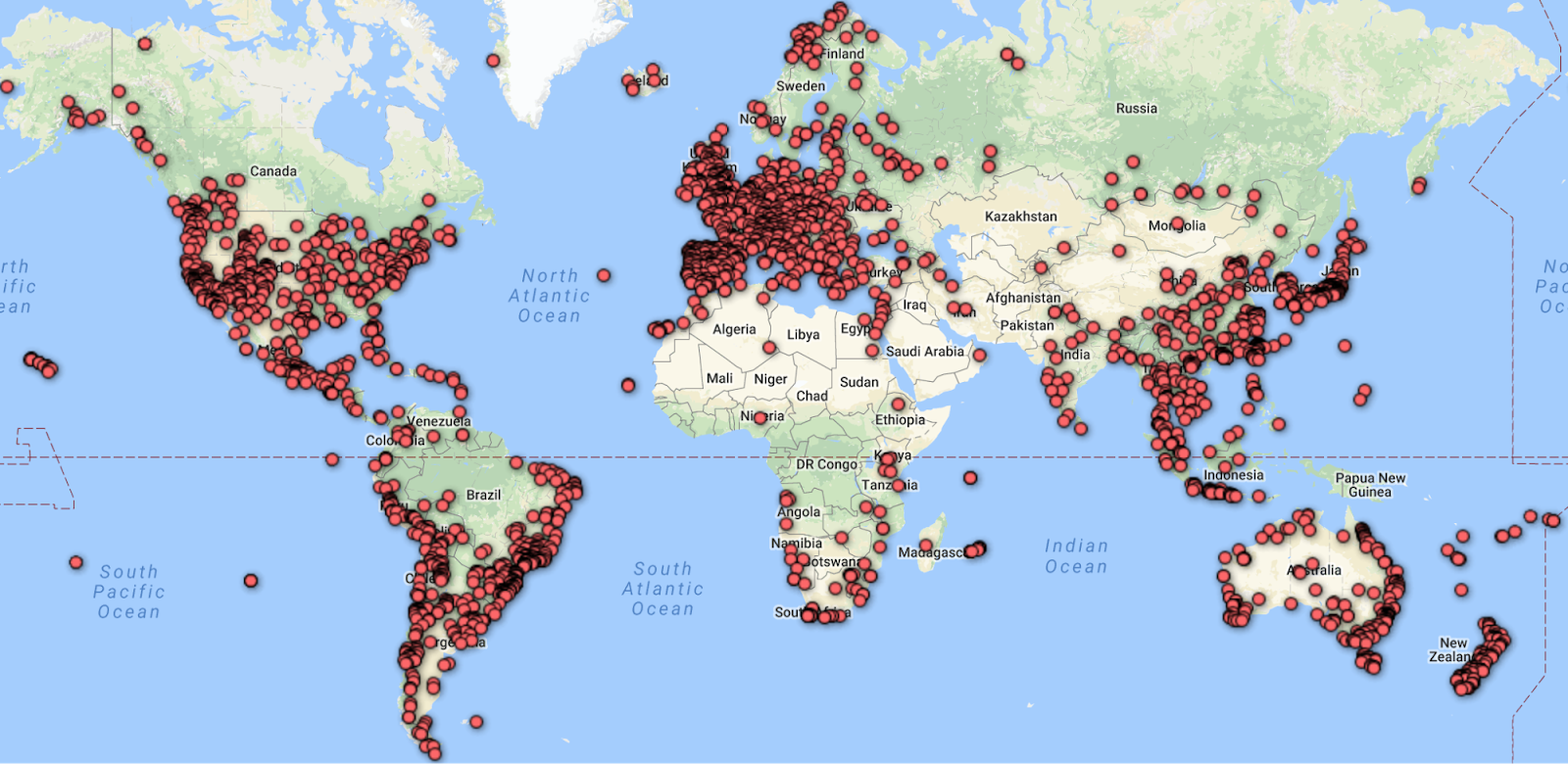
Вдобавок к этому, создатели Google-Landmarks открыли исходный код DELF — инструмента, определяющего и описывающего семантические локальные свойства, которые можно геометрически выразить между двумя изображениями одного объекта.
Сложная задача
По словам специалистов Google, распознавание достопримечательностей стоит особняком среди актуальных проблем машинного обучения. Например, даже такого большого набора данных недостаточно, чтобы описать множество менее известных памятников. Это связано с тем, что достопримечательности, как правило, представляют из себя неподвижные предметы, и их внутриклассовая вариация крайне мала. Это усложняет поиск ключевых особенностей распознаваемых объектов, так как их зачастую просто нет. Разнообразие можно воссоздавать искусственно, делая снимки памятника с различных ракурсов, однако такой подход ведёт к разрастанию баз данных. С подобной проблемой также приходится сталкиваться разработчикам систем распознавания произведений искусства.

Для решения этих проблем Kaggle устроила специальное соревнование, разделённое на две ветви. Участникам первого «челленджа» предстоит разработать модель, умеющую распознавать достопримечательность из предложенной базы, а их коллегам — создать систему, способную извлекать из набора данных все фотографии, на которых изображён требуемый памятник культуры.
Google принимает активное участие в развитии открытых проектов в области искусственного интеллекта. Напомним, что в середине февраля компания открыла доступ к базе серийных фотоснимков HDR+ в формате RAW, которую использует в собственной системе обработки изображений.

4К открытий4К показов

Рассказываем, как в Газпромбанке научились оживлять нарисованных человечков с помощью Data Science и трёх групп ML-моделей.

Разобрали API Kandinsky 3.0 и автоматизировали процесс генерации изображений с примерами кода. Код написан на Python.

Угроза для аутентификатора 2FA. Рассказываем, что не так с облачной синхронизацией Google Authenticator и как отреагировали в Google.

Энтузиаст портировал легендарную DOOM 1993 года на банковский терминал. Причем неотъемлимая часть геймплея завязана на использовании карты