Качественно новый уровень визуализации данных в Python
Когда-то для визуализации данных в Python использовали matplotlib. Однако позже появилась более удобная библиотека — plotly. Рассказываем, что она может.

Рассказывает Уилл Кёрсен, data scientist в Cortex Intel
Нам сложно отказываться от дел, на которые мы уже потратили много времени. Поэтому мы остаёмся на нелюбимой работе, вкладываемся в проекты, которые точно не «взлетят». А ещё продолжаем пользоваться утомительной библиотекой matplotlib для построения графиков, когда есть более эффективные и привлекательные альтернативы.
За последние несколько месяцев я осознал, что единственная причина, по которой я пользуюсь matplotlib, заключается в том, что я потратил сотни часов на изучение её запутанного синтаксиса. Из-за неё я жил на StackOverflow, пытаясь найти ответ на тот или иной вопрос. К счастью, для создания графиков на Python настали светлые времена, и после изучения доступных вариантов я выбрал явного победителя (с точки зрения простоты использования, документации и функциональности) в лице библиотеки plotly. В этой статье мы с ней познакомимся и научимся делать более качественные графики за меньшее время — зачастую с помощью одной строки кода.
Весь код для этой статьи доступен на GitHub. Все графики интерактивны, а посмотреть их можно на NBViewer.
Обзор plotly
Пакет plotly для Python — это open-source библиотека, основанная на plotly.js, которая, в свою очередь, основана на d3.js. Мы будем использовать обёртку для plotly под названием cufflinks, написанную для работы с DataFrame’ами Pandas.
Вообще, Plotly — это графическая компания с несколькими продуктами и open-source инструментами. Библиотека на Python бесплатна для использования, и мы можем создавать графики без ограничений в офлайн-режиме плюс до 25 графиков в онлайн-режиме.
Весь код из этой статьи был написан в Jupyter Notebook с plotly + cufflinks, запущенными в офлайн-режиме. После установки plotly и cufflinks с помощью pip install cufflinks plotly добавьте следующие импорты в блокнот Jupyter:
Гистограммы и бочки с усами
Графики по одной переменной — стандартный способ начать анализ, а гистограмма — надёжный выбор (хоть и не без изъянов) для отображения распределения. Давайте нарисуем интерактивную гистограмму количества лайков, используя статистику моих постов на Medium (df это обычный DataFrame):
Если вы работали с matplotlib, то вы заметили, что нам пришлось добавить всего одну букву (iplot() вместо plot()), чтобы получить гораздо более красивый и интерактивный график! Можно кликнуть на данные для получения подробностей, приблизить части графика и, как мы потом увидим, выбирать отдельные категории для просмотра.
А вот так можно построить наложенные друг на друга гистограммы:
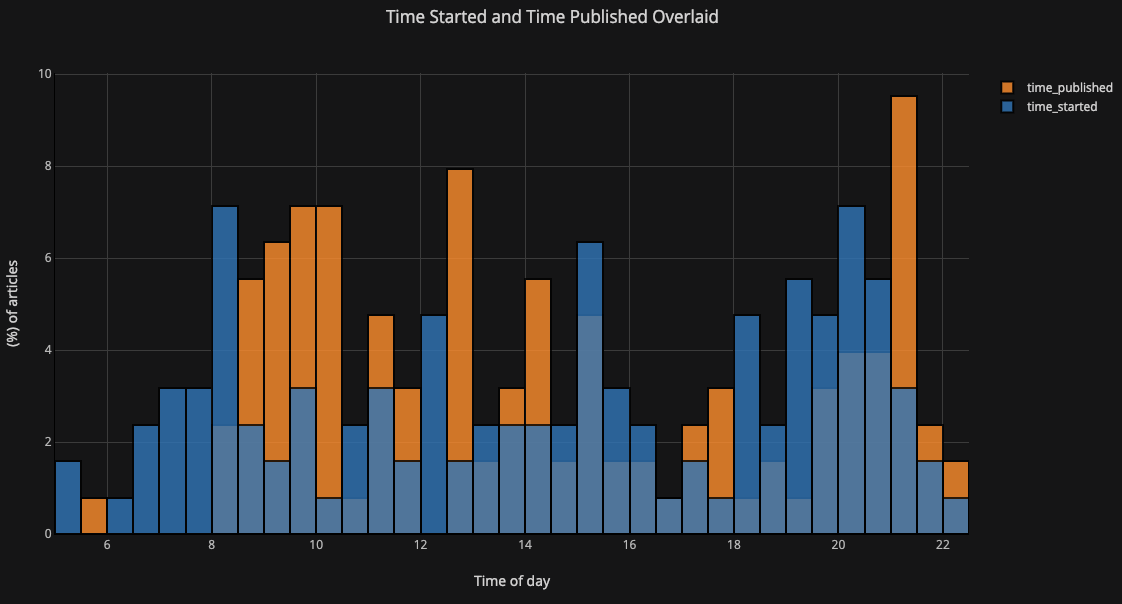
Немного поколдовав с pandas, получим столбчатую диаграмму:
Как видите, мы можем совмещать возможности pandas и plotly + cufflinks. Для графика «ящик с усами», который показывает количество лайкнувших каждый пост, мы сначала используем pivot(), а затем строим график:
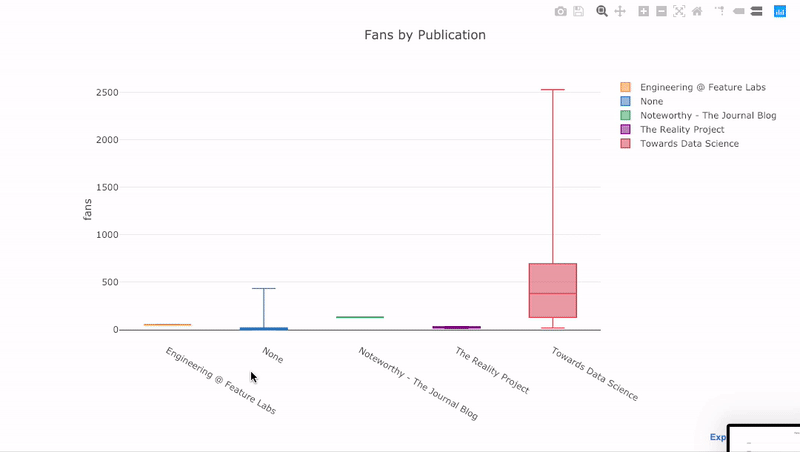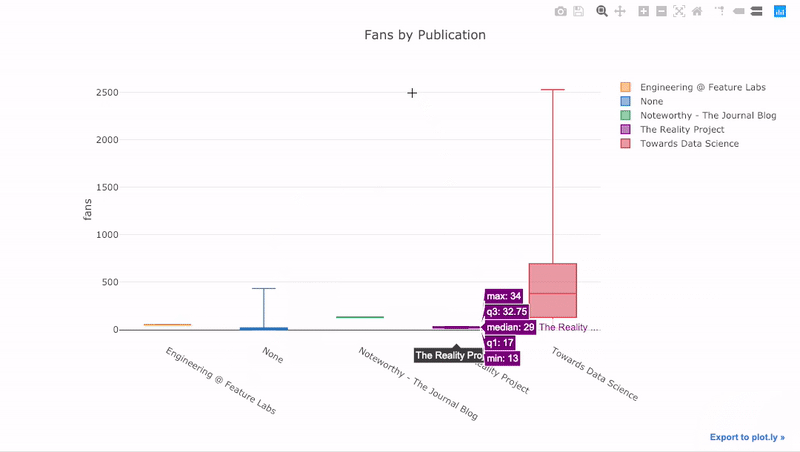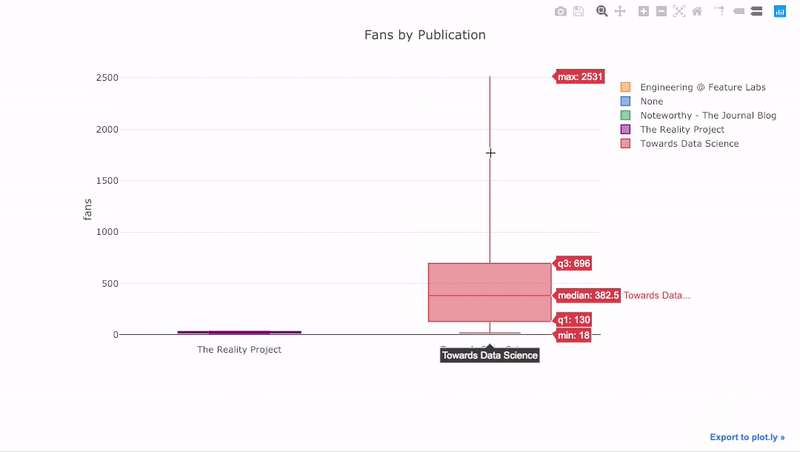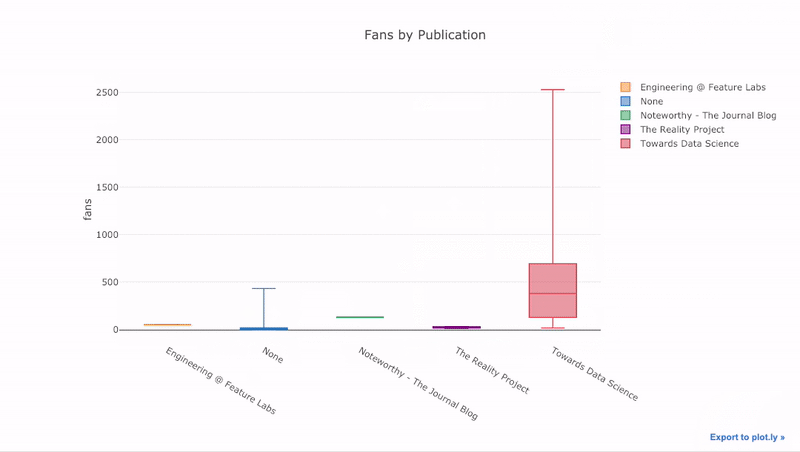
Преимущества интерактивности заключаются в том, что мы можем исследовать данные и делать их выборки любым образом. Ящик с усами содержит много информации, большая часть которой пройдёт мимо нас, если мы не сможем видеть числа!
Диаграмма рассеяния
Это, наверное, наиболее часто используемая диаграмма при анализе данных. Она позволяет увидеть изменение переменной с течением времени или отношение между двумя (или более) переменными.
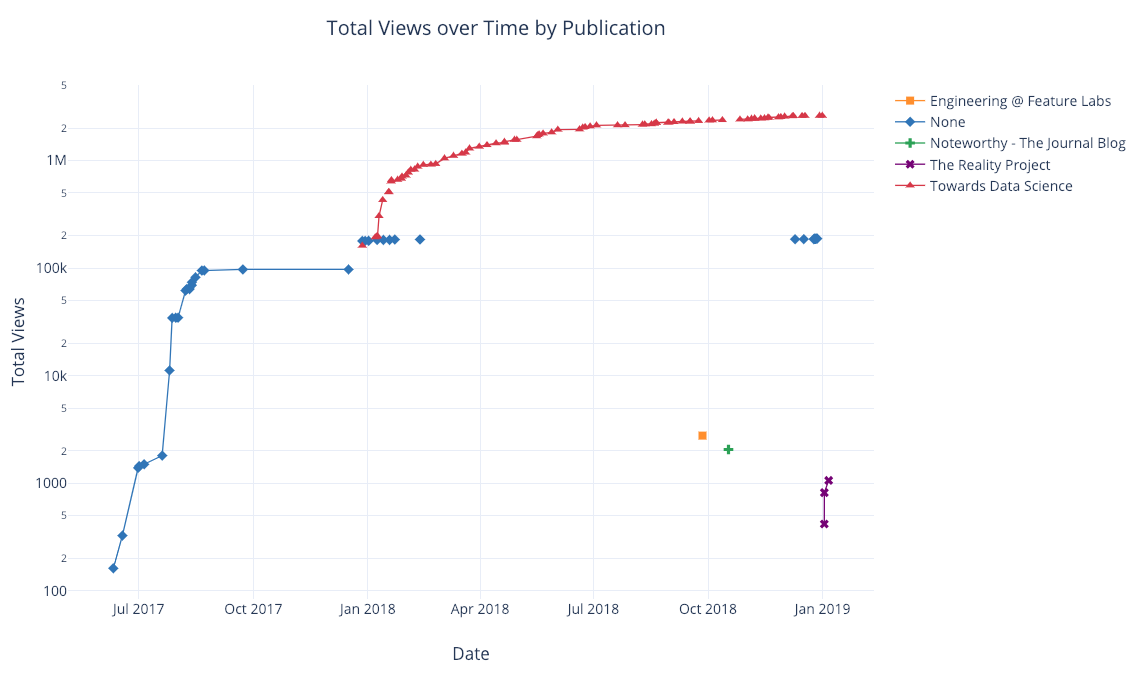
Временные ряды
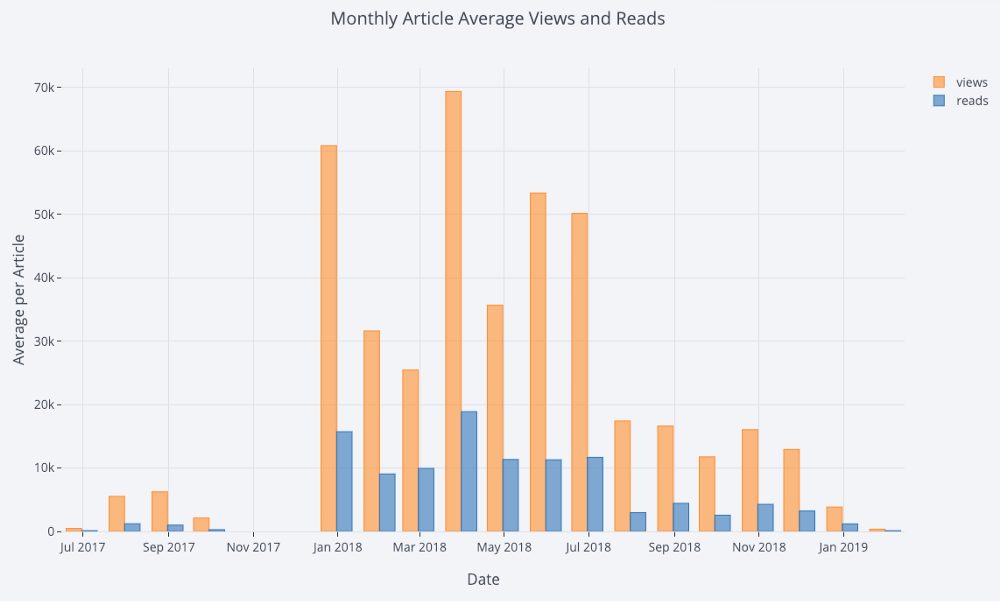
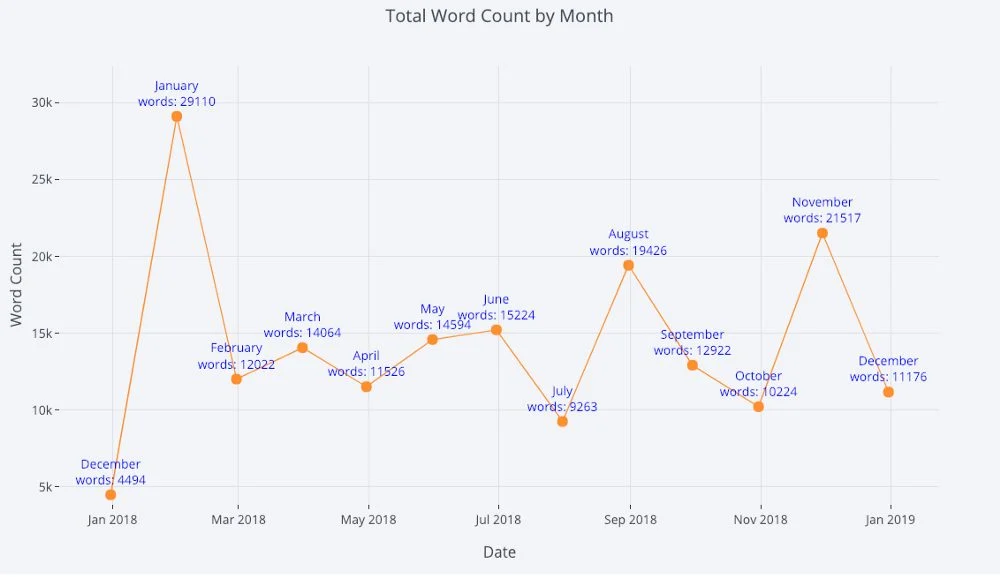
В значительной части данных содержится информация о времени. К счастью, plotly + cufflinks были разработаны с расчётом на визуализацию временных рядов. Создадим DataFrame с моими статьями и посмотрим, как менялись тренды.

Здесь мы в одну строку делаем сразу несколько разных вещей:
- Автоматически получаем красиво отформатированную ось X;
- Добавляем дополнительную ось Y, так как у переменных разные диапазоны;
- Добавляем заголовки статей, которые высвечиваются при наведении курсора.
Для большей наглядности можно легко добавить текстовые аннотации:
А вот так можно создать точечную диаграмму с двумя переменными, окрашенными согласно третьей категориальной переменной:
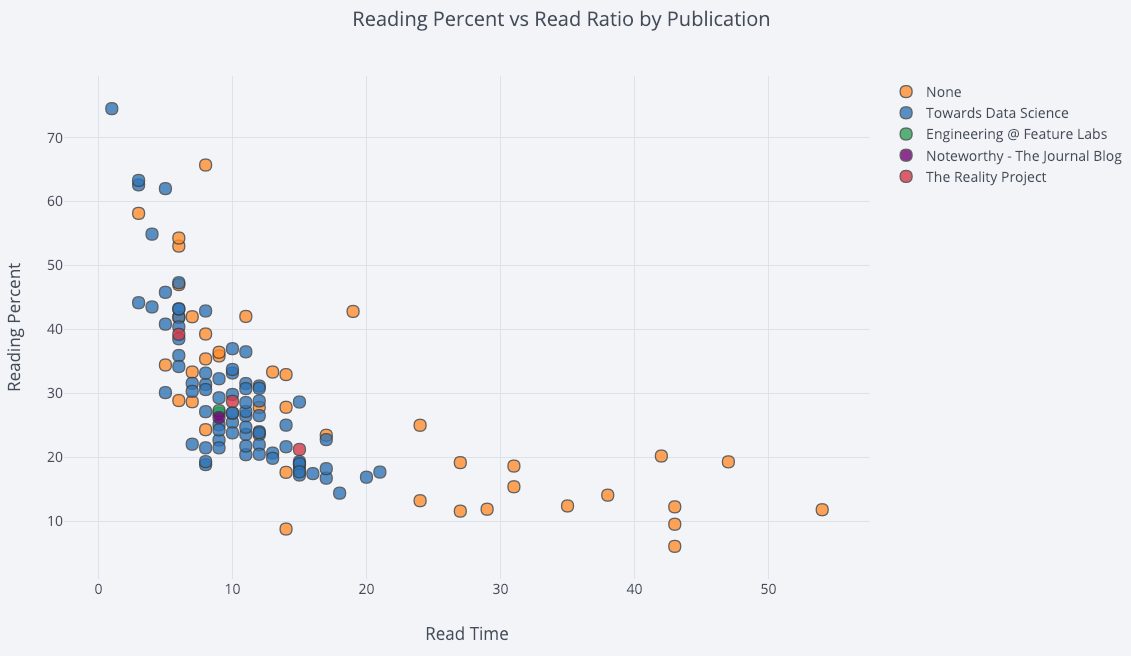
Сделаем график немного более сложным, используя логарифмическую ось (настраивается через аргумент layout, подробнее в документации) и установив размер пузырьков в соответствии с числовой переменной:
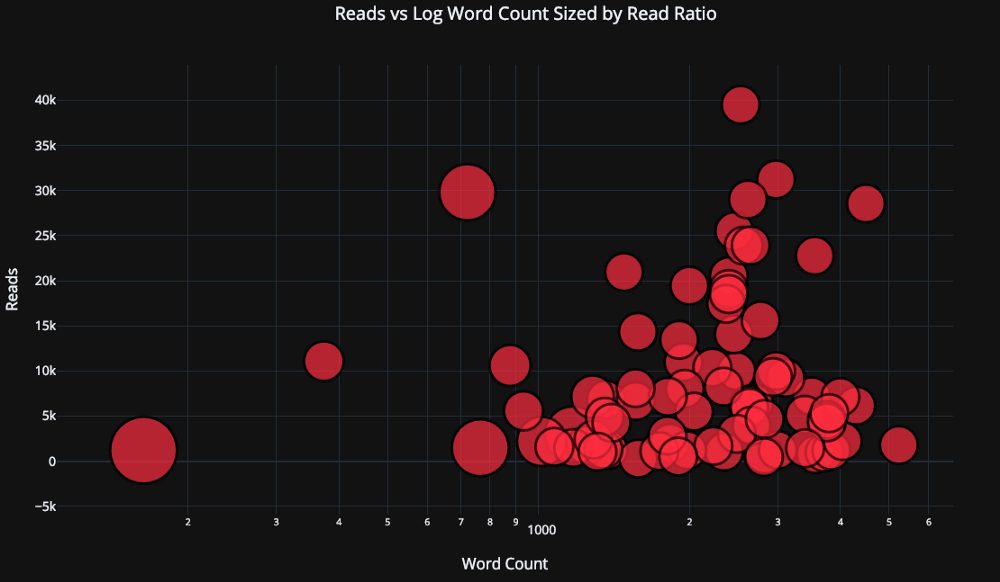
Если захотеть (подробности в блокноте), то можно уместить даже 4 переменные (не советую) на одном графике!

Как и раньше, мы совмещаем возможности pandas и plotly + cufflinks для получения полезных графиков:
Загляните в блокнот или документацию, чтобы увидеть больше примеров добавленной функциональности. Мы можем добавить текстовые аннотации, контрольные линии и линии тренда с помощью всего лишь одной строки кода и при этом сохраним всю интерактивность.
Продвинутые графики
Теперь познакомимся с несколькими графиками, которые используются не так часто, но могут выглядеть довольно впечатляюще. Мы воспользуемся plotly.figure_factory(), чтобы даже эти невероятные графики создавать в одну строку.
Матрица рассеяния
Матрица рассеяния — отличный выбор, если нам нужно изучить отношения между многими переменными:
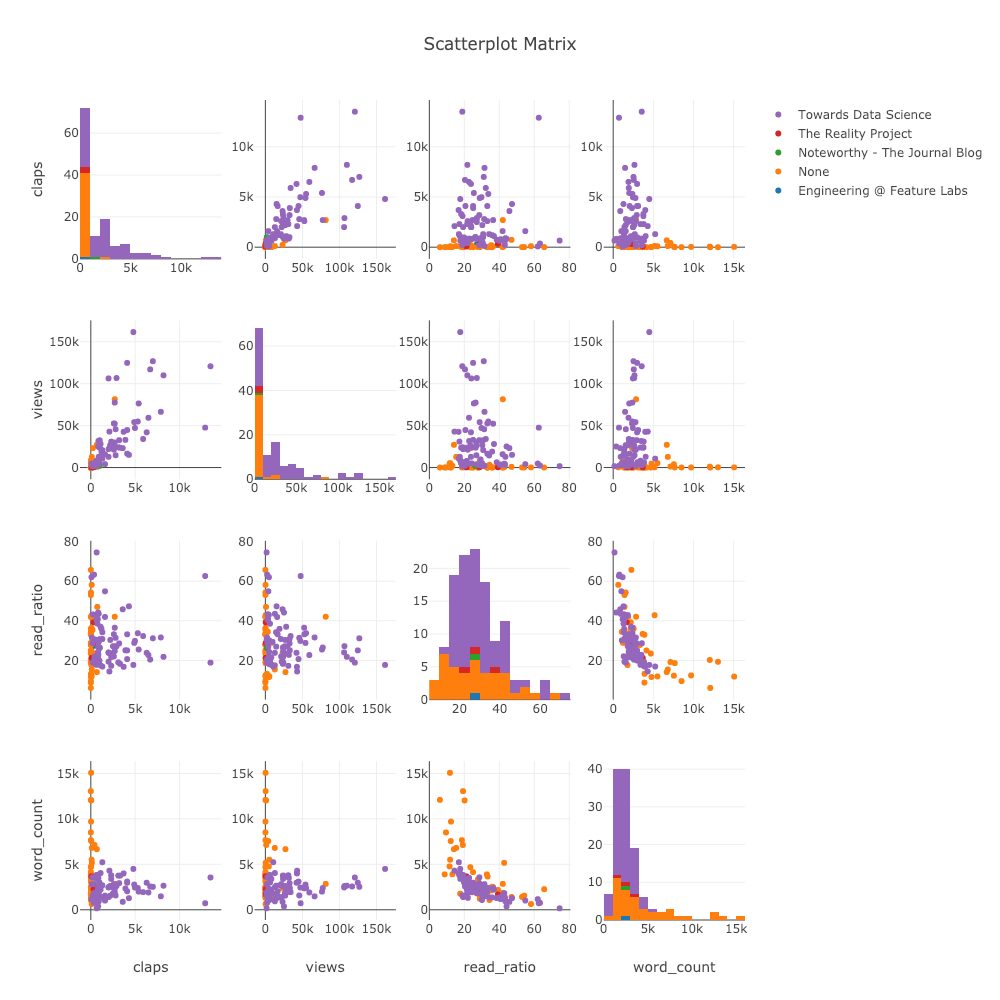
Даже этот график полностью интерактивен, что позволяет нам исследовать данные.
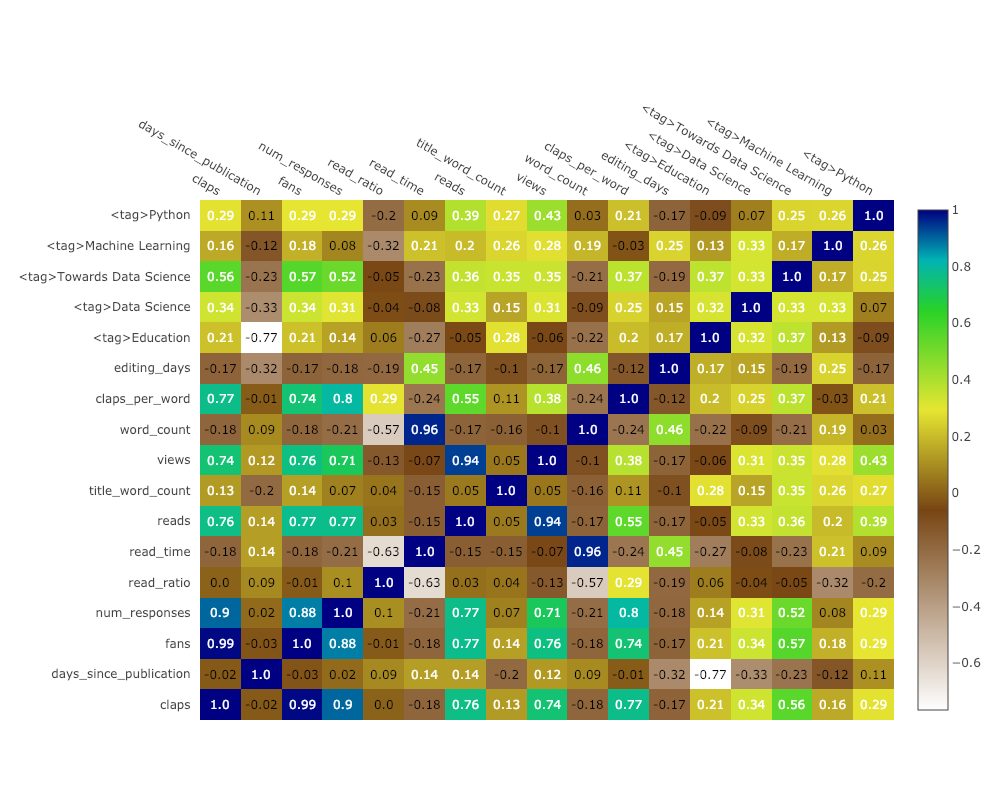
Корреляционная тепловая карта
Чтобы отобразить взаимосвязи между числовыми переменными, сначала посчитаем коэффициенты корреляции, а затем создадим аннотированную тепловую карту:
Cufflinks также предлагает несколько тем, которые можно использовать для получения совершенно другого стиля, не прилагая усилий. Например, ниже можно увидеть графики с темами «space» и «ggplot»
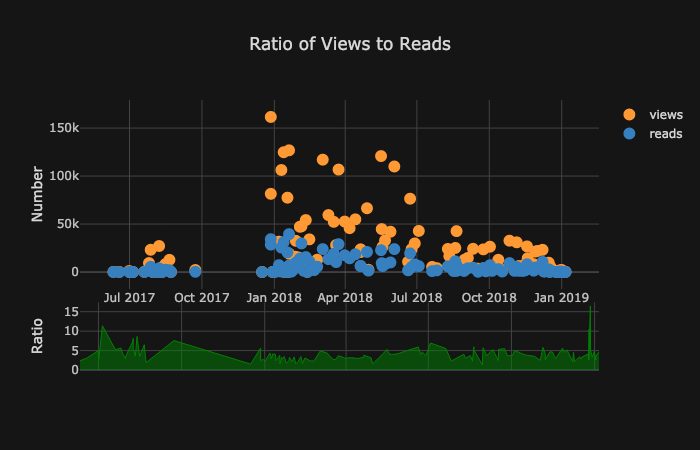
Не 2D единым:
Ну и куда без круговой диаграммы?

Редактирование в Plotly Chart Studio
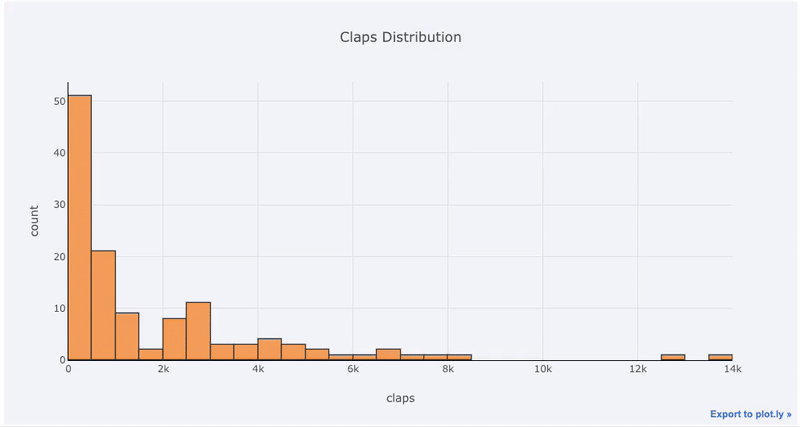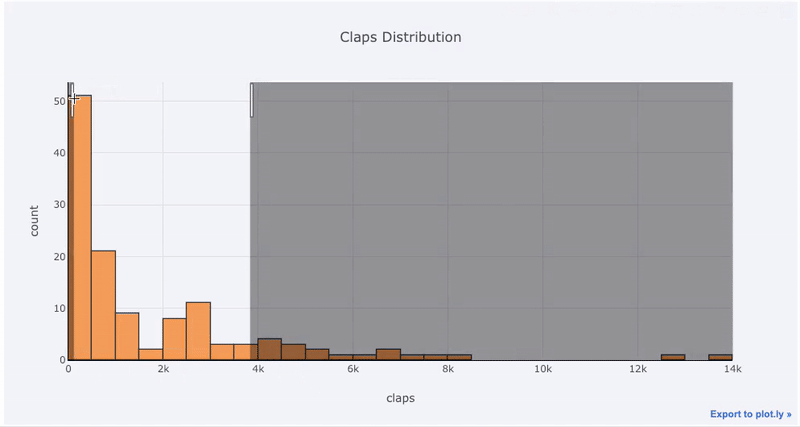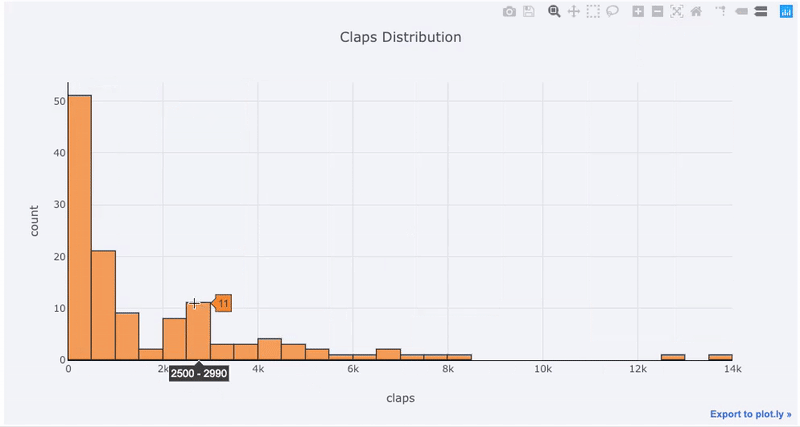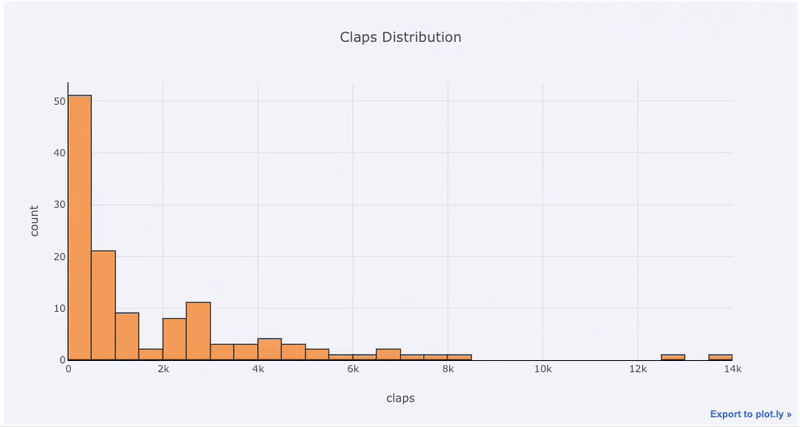
В процессе создания этих графиков в блокноте можно заметить маленькую ссылку в правом нижнем углу, которая гласит «Export to plot.ly». После перехода по ней вы попадёте в редактор графиков, где вы можете внести финальные штрихи в график перед презентацией графика. Вы можете добавить аннотации, выбрать цвета и в целом сделать из графика конфетку. Затем можно опубликовать график и поделиться ссылкой на него.
Ниже показаны два графика, которые я подправил в Chart Studio:
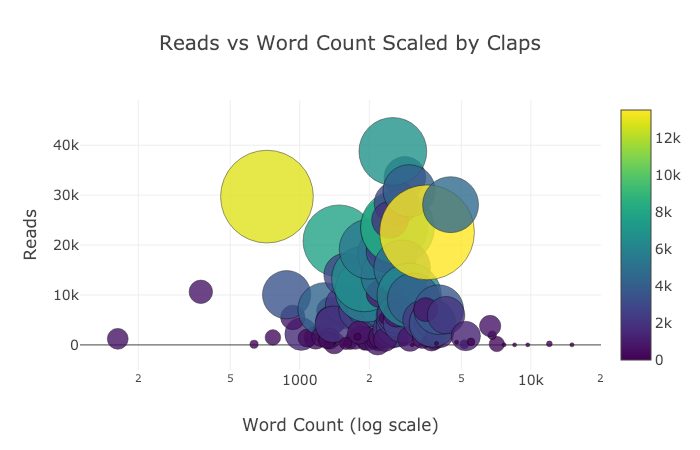
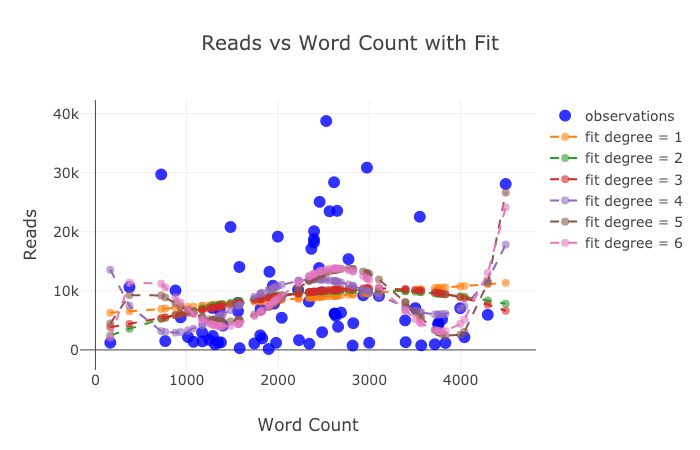
Мы упомянули много всего, однако мы всё ещё не раскрыли весь потенциал библиотеки! Настоятельно рекомендую заглянуть в документацию plotly и cufflinks, чтобы увидеть ещё более потрясающие графики:
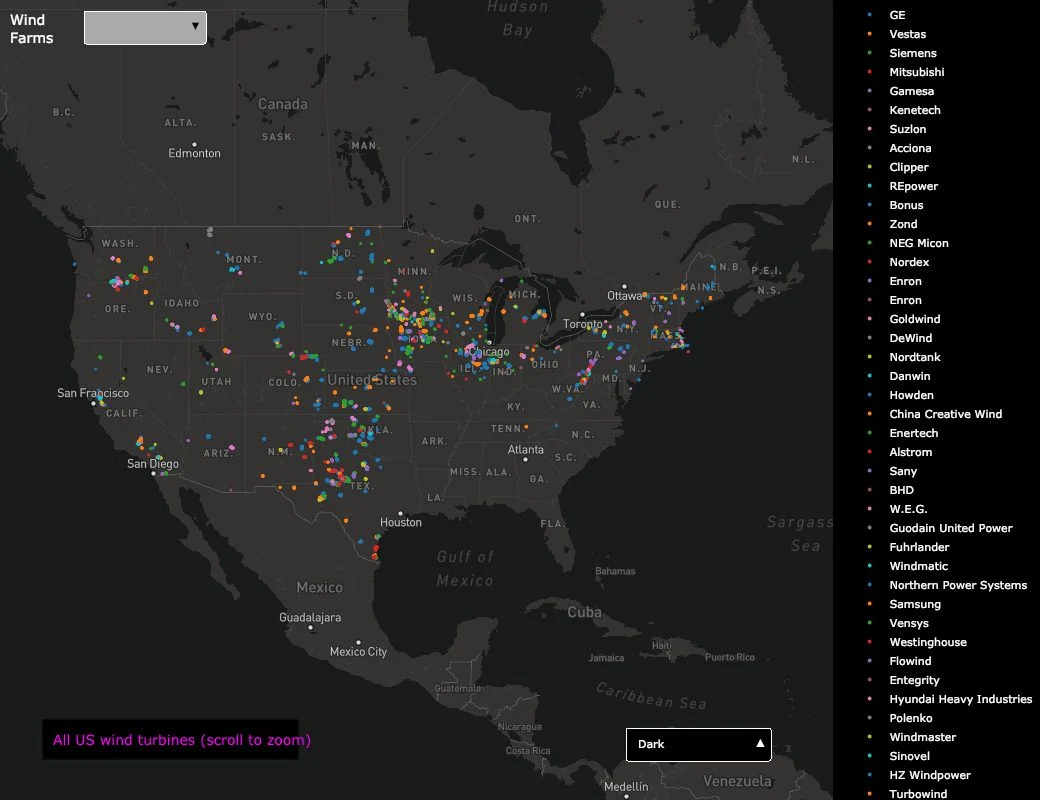
Заключение
Когда речь заходит о библиотеках для построения графиков, есть несколько вещей, которые зачастую нужны разработчику:
- Быстрое построение графиков в одну строку.
- Интерактивные элементы для получения более узкой выборки.
- Возможность углубиться в детали при необходимости.
- Простая настройка для конечной презентации.
На данный момент лучше всего для этих целей в Python подходит plotly. Plotly позволяет быстро визуализировать данные и благодаря интерактивности помогает лучше в них разобраться. И давайте начистоту — визуализация должна быть одной из самых приятных частей data science! С использованием других библиотек построение графиков превращалось в утомительное занятие, однако plotly возвращает радость от этого дела.
Смотрите также: Основы статистики с Python




