Главные AI-модели декабря 2025: что нового на Hugging Face
Собрали 45 самых популярных AI-моделей декабря 2025 года с Hugging Face — от генерации изображений за секунду до агентов, которые играют в видеоигры. Разобрали по категориям — языковые модели, кодинг, генерация картинок и видео, 3D, аудио и агенты.

Каждую неделю на Hugging Face появляются сотни новых моделей, и уследить за всеми релизами почти невозможно.
Мы собрали самые популярные и интересные модели декабря 2025 года — от генерации изображений за секунду до агентов, которые играют в видеоигры. Разобрали по категориям, чтобы вы быстро нашли то, что нужно для вашего проекта.
В этом обзоре — модели от китайских гигантов (Alibaba, DeepSeek, ZAI, Tencent, Xiaomi), западных компаний (Microsoft, Google, NVIDIA, Apple) и независимых команд. Все они доступны в open-source, большинство можно запустить локально даже на одной GPU.
Большие языковые модели
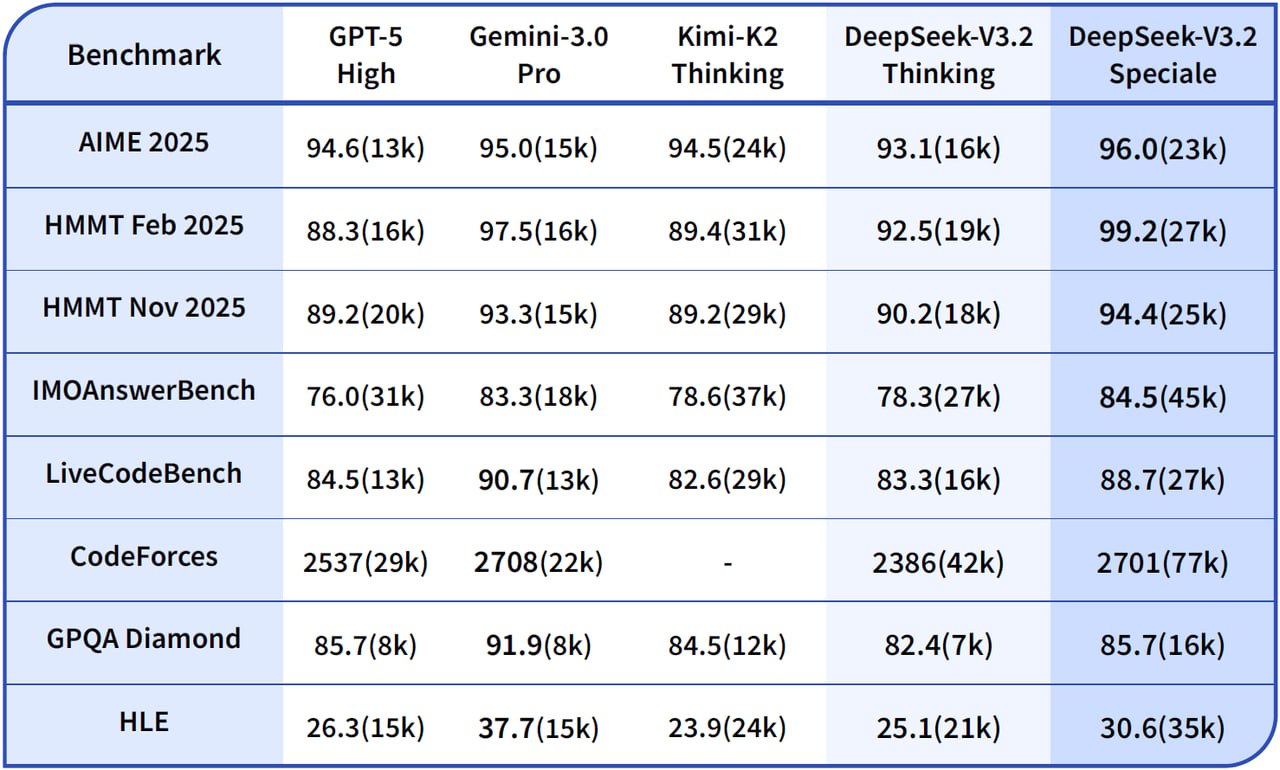
DeepSeek V3.2
1 декабря вышла V3.2 — и судя по бенчмаркам, это уже уровень GPT-5, а расширенная версия V3.2-Speciale заявляется на уровне Gemini-3.0-Pro. Модель взяла золото на IMO и IOI 2025, что для open-source LLM довольно серьёзная заявка.
Главное техническое нововведение — DeepSeek Sparse Attention (DSA), механизм разреженного внимания, который снижает вычислительную сложность на длинных контекстах без потери качества. Ещё добавили поддержку «размышления с инструментами» — модель может думать и параллельно вызывать tool-use, что важно для агентных сценариев. Есть новый пайплайн синтеза данных для обучения агентным задачам — это улучшает работу модели в сложных интерактивных средах.
Модели: V3.2, V3.2-Speciale, тех. отчёт.
GLM-4.7 от ZAI
Новый флагман на 358 миллиардов параметров (32 миллиарда активных), MoE, заточен под агентный кодинг и сложный reasoning. Главные фичи: модель думает между действиями и сохраняет контекст размышлений в длинных multi-turn задачах. SOTA на SWE-bench Multilingual и Terminal Bench.
- LMArena Code Arena: #1 open-source, обогнала GPT-5.2
- LiveCodeBench V6: 84,8 (open-source SOTA), выше Claude Sonnet 4.5
- AIME 2025 (математика): open-source SOTA, выше Sonnet 4.5 и GPT-5.1
Документация здесь.
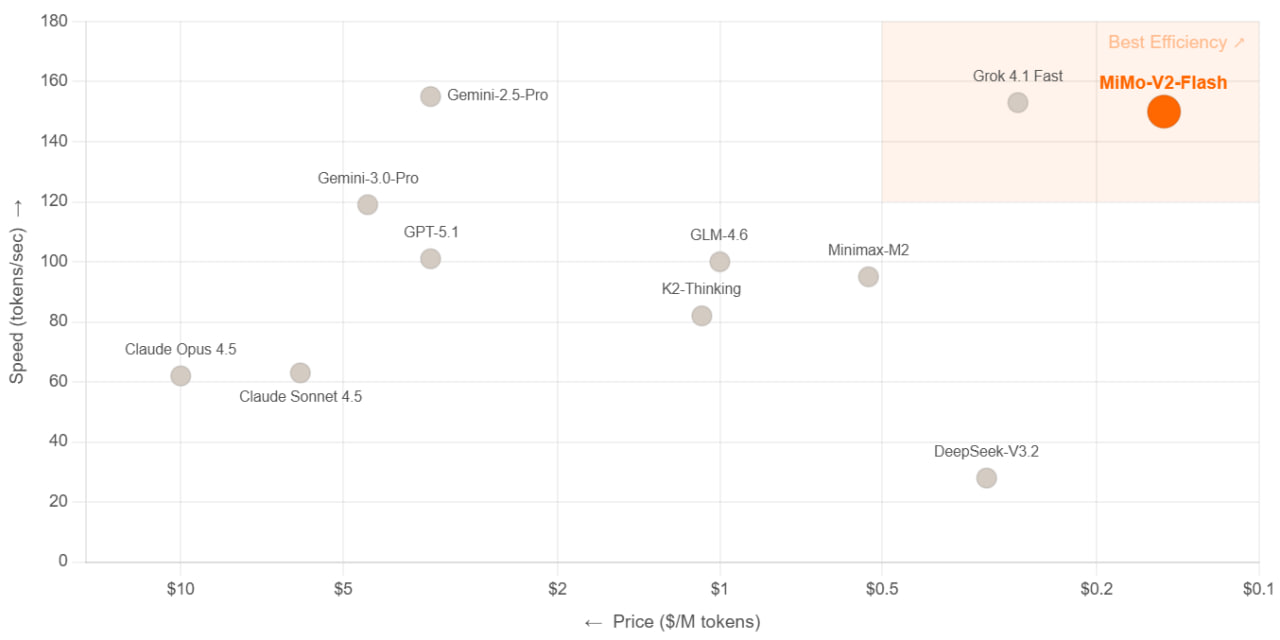
MiMo-V2-Flash
Xiaomi выкатила конкурента DeepSeek и Claude. 309B параметров, 15B активных (MoE). Гибридный attention: sliding window + full в соотношении 5:1. Контекст 256k токенов.
Reasoning, код, агентские сценарии. На SWE-bench Verified (73,4%) — #1 среди open-source, на уровне GPT-5 High. На AIME 2025 (94,1%) — топ-2 среди открытых моделей. Умеет hybrid thinking: можно включать/выключать «размышления».
- 150 токенов/сек на инференсе
- $0,1 / 1M input, $0,3 / 1M output
- Self-speculative decoding через MTP даёт ускорение 2,0-2.6x
Под капотом Multi-Token Prediction (MTP) — модель предсказывает несколько токенов за раз и верифицирует параллельно. Sliding Window Attention вместо Linear Attention — фиксированный KV-кэш, проще интеграция. MOPD (Multi-Teacher Online Policy Distillation) — новый подход к post-training: <1/50 вычислений от классического SFT+RL пайплайна при сопоставимом качестве.
HuggingFace, официальный блог, API.
Отдельно новички топа
rnj-1-instruct
8 миллиардов параметров от авторов «Attention Is All You Need», заточена на агентный кодинг: 62,2% на BFCL (tool use), лицензия Apache 2.0.
nomos-1 от Nous Research
30 миллиардов параметров MoE (3 миллиарда активных), набрал 87 из 120 баллов на Putnam 2025 — это второе место среди 3988 людей. Базовая Qwen3-30B получила лишь 24 балла.
Mistral Ministral-3
Модели на 3 миллиарда и 14 миллиардов параметров для более компактного деплоя.
Arcee Trinity-Mini
26 миллиардов параметров.
FunctionGemma-270M от Google
Ультралёгкая модель специально для function calling. Разработана для on-device агентов: переводит естественный язык в API-вызовы. Работает как standalone или как traffic controller для более мощных моделей.
SamKash-Tolstoy
Загадочный проект для работы с русскоязычными литературными текстами: анализ, стилизация, генерация в духе классиков.
Модели для кодинга
Devstral 2 от Mistral — главная новинка. Две версии: флагман на 123 миллиарда параметров с 72% на SWE-bench Verified и контекстом 256 тысяч токенов, и компактный Devstral Small 2 на 24 миллиарда параметров с 68% на том же бенчмарке. Маленькая версия работает на одной GPU и обходит конкурентов класса 70 миллиардов параметров.
Devstral 2 в 5 раз меньше DeepSeek V3.2 и в 8 раз меньше Kimi K2, но показывает сравнимые результаты. В blind-тестах через Cline побеждает DeepSeek (42,8% vs 28,6%), хотя Claude Sonnet 4.5 всё ещё впереди.
Также представили Mistral Vibe CLI — терминальный агент на базе Devstral. Умеет:
- Сканировать проект и git status для контекста
- Автокомплит файлов через @, shell-команды через !
- Работать с несколькими файлами одновременно на уровне архитектуры
- Интегрироваться в IDE через Agent Communication Protocol (уже есть в Zed)
Веса, API на офф. сайте.

Генерация изображений
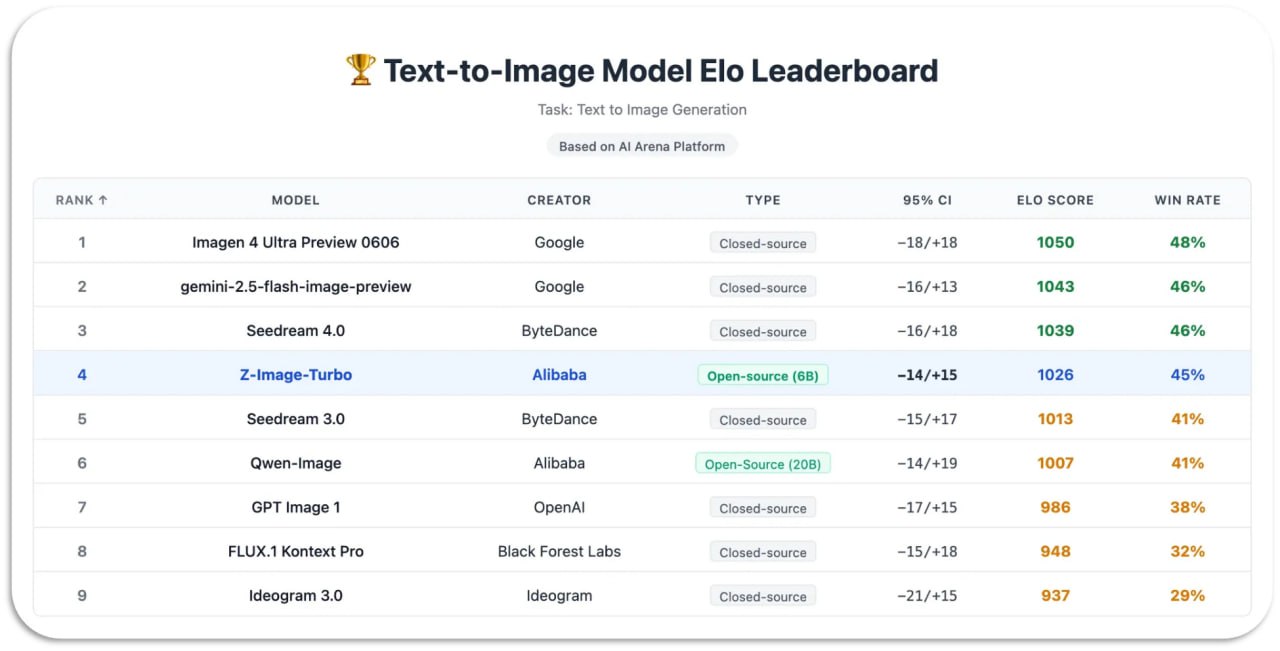
Z-Image-Turbo от Alibaba
Новая открытая текст‑в‑картинку модель от Alibaba, всего 6B параметров, но по качеству и пониманию промптов её уже сравнивают с куда более тяжёлыми монстрами. Это турбо-версия семейства Z‑Image: дистиллированная, работает всего за 8 шагов диффузии и даёт очень быстрый отклик при сохранении фотореализма, аккуратного света/материалов и хорошей работы с текстом в кадре.
По технике там интересная смесь: single‑stream Diffusion Transformer, который в одном трансформере обрабатывает и текст, и семантику, и изображение, плюс дистилляция через Decoupled‑DMD и дообучение DMDR, чтобы в 8 шагов выжать максимум качества. В результате модель выдаёт картинку за ~секунду на H800 и нормально живёт на обычной 16 GB видеокарте, так что её реально крутить локально, а не только в облаке.
Отдельно новички топа
Z-Image-Turbo-Fun-Controlnet-Union-2.1
ControlNet-адаптер для Z-Image-Turbo от Alibaba.
FLUX.2-dev от Black Forest Labs
Image-to-image версия их флагмана, когда нужно преобразовать одно изображение в другое.
LongCat-Image
6 миллиардов параметров, билингвальная (китайский-английский), SOTA в рендеринге китайских иероглифов, умеет и генерировать, и редактировать, влезает в 16 GB VRAM.
NewBie-image-Exp0.1
3,5 миллиарда параметров DiT на архитектуре Next-DiT, заточена под аниме. Использует XML-формат промптов для лучшего связывания атрибутов. Легче Z-Image, работает даже на 8 GB VRAM.
Qwen-Image-i2L
Генерирует LoRA из изображений без обучения. Закинули картинку — получили готовую LoRA для стилизации.
Qwen-Edit-2509-Light-Migration
LoRA для Qwen-Image-Edit-2509 для работы со светом на картинках: перенос света с одной картинки на другую, установка света, удаление освещения. От того же автора, что сделал управление виртуальной камерой.
Qwen-Image-Layered
Новинка от Qwen, которая раскладывает изображение на RGBA-слои как в Photoshop. В отличие от SAM, не просто сегментирует, а генерирует полные слои с альфа-каналом и дорисовывает скрытые области за объектами. Поддерживает переменное число слоёв (3-8+) в зависимости от сложности сцены.
AWPortrait-Z
Для генерации портретов.
3D-генерация
TRELLIS.2-4B от Microsoft
Модель обучена на датасете из 500 тысяч объектов и выдаёт результат в нескольких форматах: Radiance Fields, 3D Gaussians и готовые меши.
Что умеет:
- Генерит 3D из одной картинки или текстового промпта
- Экспорт сразу в GLB и PLY — можно тащить в движок
- Локальное редактирование: меняешь часть объекта, не пересоздавая с нуля
- Есть веб-демо на Gradio — можно потыкать без установки
До сих пор качественный image-to-3D был либо закрытым, либо слабым. TRELLIS — редкий случай, когда большая модель (2B параметров) идёт с открытым кодом и нормальной документацией. Для инди-разработчиков и 3D-художников как минимум то, что нужно попробовать.
Веса на Huggingface, код на GitHub, исследование на arxiv.
Sharp от Apple
Превращает плоское фото в интерактивную 3D-сцену меньше чем за секунду. С помощью технологии 3D Gaussian Splatting создаёт эффект глубины и параллакса, позволяя «вращать» камеру и видеть объём там, где раньше был обычный снимок.
Видео и интерактивные миры
HY-WorldPlay от Tencent
Первая open-source модель интерактивного мира с генерацией в реальном времени (24 FPS). Управление через клавиатуру и мышь, текстовые триггеры событий на лету (например, «car crash», «sudden rain»). Ключевая фича — долгосрочная 3D-консистентность: сцены сохраняются при возвращении в локацию.
STARFlow от Apple
Для генерации видео на normalizing flows.
LongCat-Video-Avatar
Генерация видео-аватаров.
Мультимодальные модели
SAM3
Новая версия модели, которая по текстовому или визуальному запросу находит, выделяет и трекает нужные объекты на картинках и видео. Главный сдвиг: модель понимает абстрактные «концепты» вроде «жёлтый автобус» или «люди в касках» и сразу сегментирует все такие объекты, а не один, как в старых SAM.
Новое для этой версии:
- Promptable Concept Segmentation: пишешь фразу или даёшь пример‑картинку, и SAM 3 находит и сегментирует все экземпляры этого класса, в том числе по кадрам видео.
- Объединены текстовые и визуальные подсказки: можно и написать «автомобиль», и прокликать мышкой спорные объекты в одном и том же интерфейсе.
- Открытый словарь: модель не привязана к фиксированному списку классов и работает с любыми осмысленными запросами, которые можно визуально приземлить.
Код в репо, веса на хагинфейсе.
STARFlow от Apple
Модели для генерации картинок и видео, но не на диффузии, а на normalizing flows. Это первый раз, когда NF-подход дотянули до качества современных диффузионных моделей.
Главная фишка — генерация за один проход вместо итеративного деноизинга. На практике это даёт заметный выигрыш: 81 кадр 480p видео генерируется за 42 секунды на H100, тогда как диффузионный WAN-2.1 тратит на это 210 секунд. Используется Jacobi iteration — обновления внутри блоков параллелятся, что хорошо ложится на GPU.
Архитектура deep-shallow: глубокий causal transformer обрабатывает сжатые латенты для глобальных зависимостей, а shallow flow blocks работают независимо над каждым кадром для локальных деталей. Это помогает избежать накопления ошибок при авторегрессионной генерации видео.
Две модели:
- STARFlow 3B — text-to-image, 256×256, запускается на потребительских картах
- STARFlow-V 7B — text-to-video, до 480p, 5–30 секунд видео, нужно 40GB VRAM (RTX 4090 с 24GB не хватит, нужен A100/H100)
По качеству пока не топ-1, но в одном ряду с causal diffusion моделями. Зато есть exact likelihood и инвертируемость — можно делать редактирование через инверсию.
Код на GitHub, веса на HuggingFace, примеры работы на отдельном лендинге.
Отдельно новички топа
GLM-4.6V от ZAI
Флагман на 106 миллиардов параметров, SOTA на 42 бенчмарках визуального понимания среди открытых моделей. Контекст 128 тысяч токенов, впервые нативный function calling для VLM — мост между «увидел» и «сделал». Лёгкая версия GLM-4.6V-Flash на 10 миллиардов параметров с 67 тысячами скачиваний для локального деплоя.
Tencent HunyuanOCR
319 тысяч скачиваний, модель для распознавания текста на изображениях.
Apriel-1.6-15b-Thinker от ServiceNow
15 миллиардов параметров, reasoning модель, которая набирает 57 баллов на AA Intelligence Index наравне с Qwen-235B и DeepSeek-v3.2-Exp, будучи в 15 раз меньше.
Nemotron-3-Nano-30B-A3B от NVIDIA
Модель, заточенная под эффективную работу в мультиагентных системах, по сути промежуточные шаги, где нужна скорость без высоких затрат.
t5gemma-2 от Google
Понимает картинки и текст одновременно. Показываете фото, задаёте вопрос — получаете ответ.
Аудио-модели
Microsoft VibeVoice-Realtime-0.5B
Real-time TTS на 1 миллиард параметров, но только английский. На втором месте общего топа с 131 тысячей скачиваний, но всё ещё только английский, без поддержки русского.
GLM-ASR-Nano-2512
Компактная ASR модель на 1,5 миллиарда параметров для продакшна с поддержкой диалектов. Только английский и китайский.
sam-audio-large
Свежий релиз «сегментации всего» для аудио. Можно кликнуть на человека на видео и отфильтровать только его голос, или выделить гитару из музыки.
chatterbox-turbo от ResembleAI
TTS-модель, только английский.
Fun-CosyVoice3-0.5B
Компактная TTS на 0,5 миллиарда параметров с поддержкой русского языка. Звучит очень неплохо, но иногда галлюцинирует. F5-TTS в этом плане куда стабильнее.
medasr от Google
ASR-модель для медицины, когда врачи или исследователи что-то надиктовывают и много специальных терминов.
AI-агенты
NVIDIA Nemotron-Orchestrator-8B
Модель-оркестратор для координации других моделей в агентских сценариях.
AutoGLM-Phone-9B от ZAI
Агент для управления Android через естественный язык. Понимает UI, кликает, навигирует по приложениям через ADB. Есть мультиязычная версия.
BU-30B-A3B-Preview
Первая open-source модель от Browser Use для веб-агентов. 30 миллиардов параметров, 3 миллиарда активных, файнтюн Qwen3-VL-30B. Обещают 200 задач на 1 доллар — в 4 раза эффективнее их предыдущей версии.
NitroGen от NVIDIA
Vision-to-action модель, которая играет в видеоигры по сырым кадрам. Обучена на более чем 40 тысячах часов геймплея с YouTube и Twitch. Работает с action RPG, платформерами, рогаликами и показывает до 52% лучшие результаты на незнакомых играх по сравнению с моделями, обученными с нуля.
Декабрь 2025 года показал явное доминирование китайских компаний в open-source AI. ZAI особенно активен — 6 моделей из топ-20 на середину месяца. Alibaba лидирует в генерации изображений с Z-Image-Turbo, которая не покидает первое место весь месяц.
Проблема с поддержкой русского языка остаётся: большинство аудио-моделей работают только с английским и китайским. Исключение — Fun-CosyVoice3-0.5B, которая поддерживает русский, но иногда галлюцинирует.
















