Многофакторное сравнение пяти популярных вычислительных движков для больших данных
Эволюция от Hadoop к cloud‑native и ИИ‑архитектурам. Многомерное сравнение Spark, Presto, Trino, ClickHouse и StarRocks по скорости, масштабируемости, кэшам, SQL/Python, HA и др.
Скорость итераций в области Big Data вновь вернулась к стремительному темпу 2015–2016 годов. Область анализа данных — самая близкая к бизнесу, часто используемая и ценная, с жёсткими требованиями к стоимости и эффективности.
Разработчики на передовой всё реже запускают новые сервисы на «тяжёлой в эксплуатации» связке сервисов Hadoop и предпочитают формат «всё в одном» — унифицированный подход, объединяющий хранение и аналитику. Если раньше архитектуру больших данных приходилось «собирать из кубиков», то теперь она всё чаще становится более монолитной архитектурой (all‑in‑one).
Кроме того, с быстрым развитием ИИ изменились и объёмы, и типы данных, поэтому на стороне вычислительных движков были проведены соответствующие оптимизации и обновления: например, для OLAP‑аналитики векторизация де‑факто стала стандартной возможностью, а форматы озёр данных эволюционируют к поддержке мультимодальности (о мультимодальном хранении — ниже).
В этой статье разберём архитектуры популярных сегодня распределённых вычислительных движков и их плюсы/минусы. Проанализировав их, мы лучше поймём, какой движок уместнее использовать в тех или иных бизнес‑сценариях.
Реализации распределённых вычислительных движков обычно состоят из компонентов «Server» и «Worker». Узлы Worker, как правило, распределяются по множеству хостов и под координацией Server выполняют параллельные вычисления. Хотя логика вычислений и оптимизации у разных движков реализована по‑разному, базовые этапы похожи.
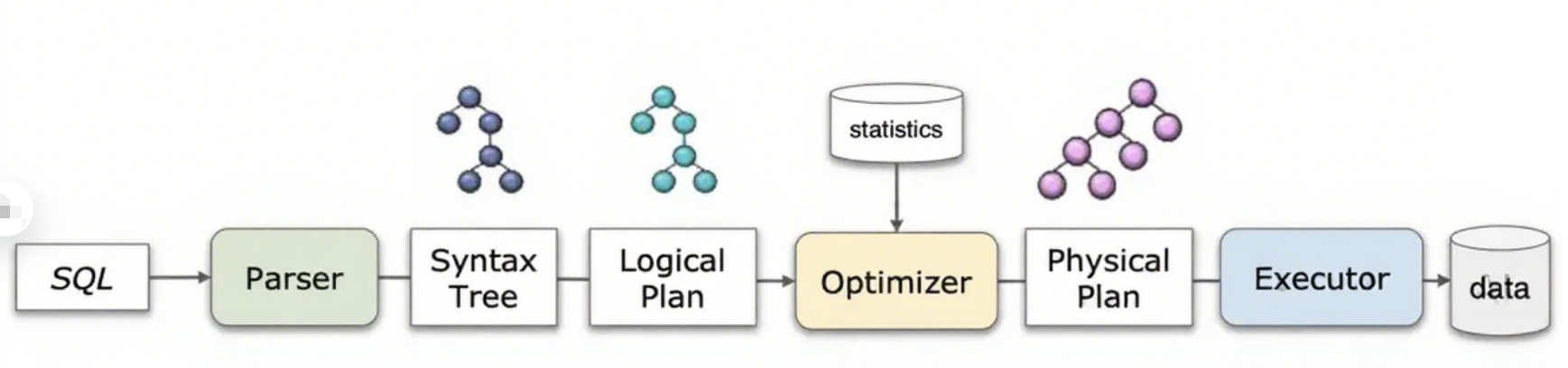
Базовые этапы выполнения запроса
- Parsing — разбор: SQL‑запрос разбирается в синтаксическое дерево для валидации структуры и выявления задействованных таблиц.
- Planning — планирование: формируется логический план, описывающий необходимые операции (например, фильтры, соединения) и их порядок.
- Optimization — оптимизация: логический план преобразуется в эффективный физический план с помощью стоимостной (CBO) или правил‑ориентированной оптимизации.
- Compilation — компиляция: физический план компилируется в низкоуровневые операции, байт‑код или аппаратно‑специфичные инструкции, подготавливаясь к исполнению.
- Execution — исполнение: план распределяется узлам Worker, которые параллельно сканируют данные, применяют преобразования и обмениваются данными; промежуточные данные/метаданные возвращаются в главный процесс.
- Result Serving — формирование и отдача результатов: результаты агрегируются, форматируются и возвращаются пользователю или нижестоящим системам (downstream).
Классификация движков по назначению
- Универсальные вычислительные движки: например, Spark, Flink, MR (MapReduce), поддерживающие пакетные и сложные вычислительные задачи, различные типы данных и множество источников.
- Интерактивные движки запросов: например, Presto, Trino — для ad hoc‑запросов, где важно быстро получать результаты и применять оптимизации, обеспечивая высокую скорость выполнения и интерактивность анализа.
- OLAP‑движки: например, ClickHouse, StarRocks, Doris и др. — для быстрого анализа постоянно меняющихся данных. Поддерживают аналитику в реальном времени, субсекундную латентность запросов и серьёзные оптимизации в оптимизаторе выполнения.
Универсальные вычислительные движки
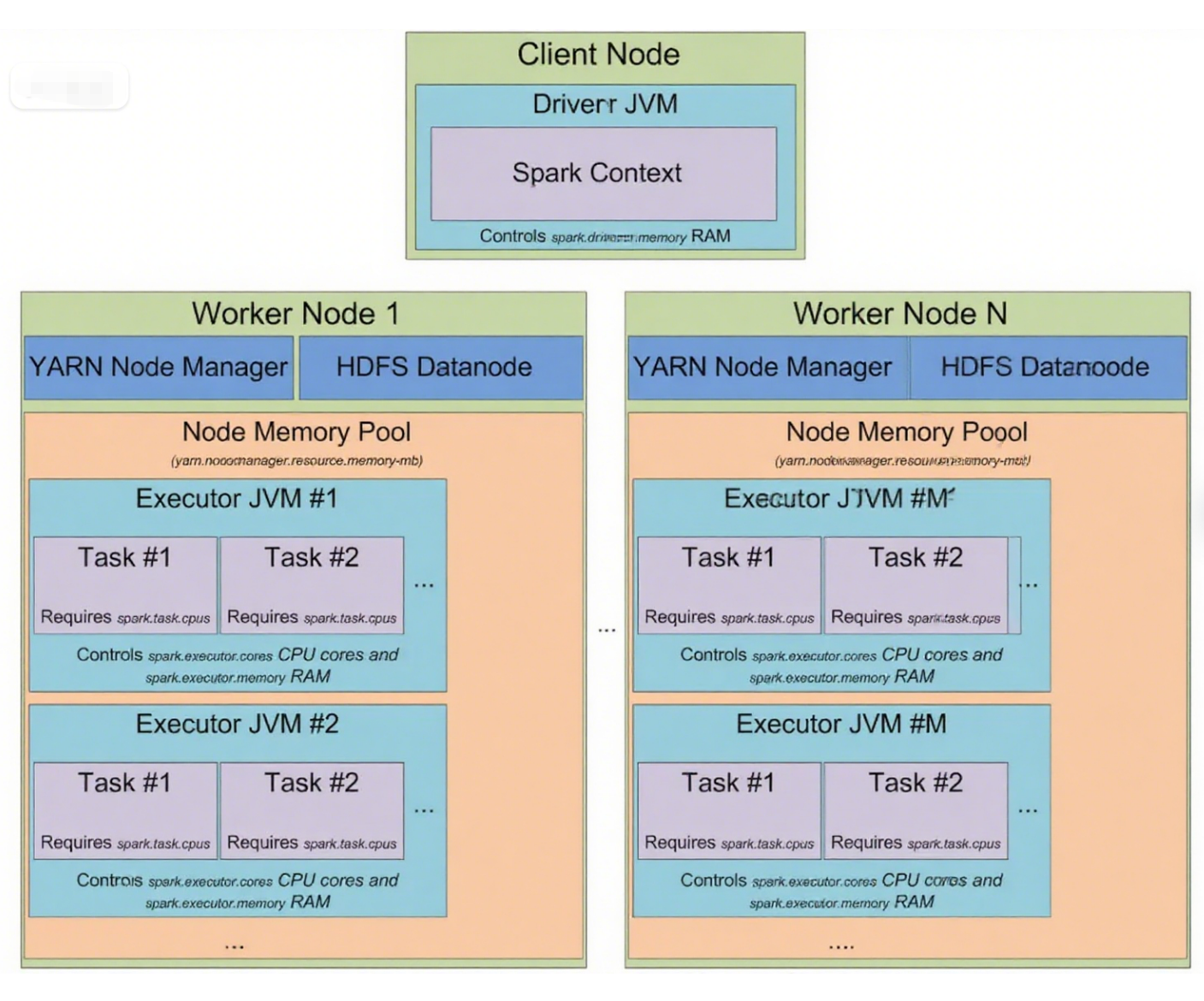
Среди универсальных движков наиболее широко используется Apache Spark: он поддерживает офлайн‑вычисления, обработку, близкую к реальному времени (near real time), и интеграцию с фреймворками машинного обучения. Spark изначально создавался для преодоления ограничений Hadoop MapReduce. Spark Driver — центральный координатор Spark‑приложения: он управляет использованием CPU и памяти, широковещательными переменными (broadcast variables, для эффективного совместного использования данных между узлами Worker) и создаёт наборы данных RDD.
Ниже — схема архитектуры Apache Spark.
Интерактивные движки запросов
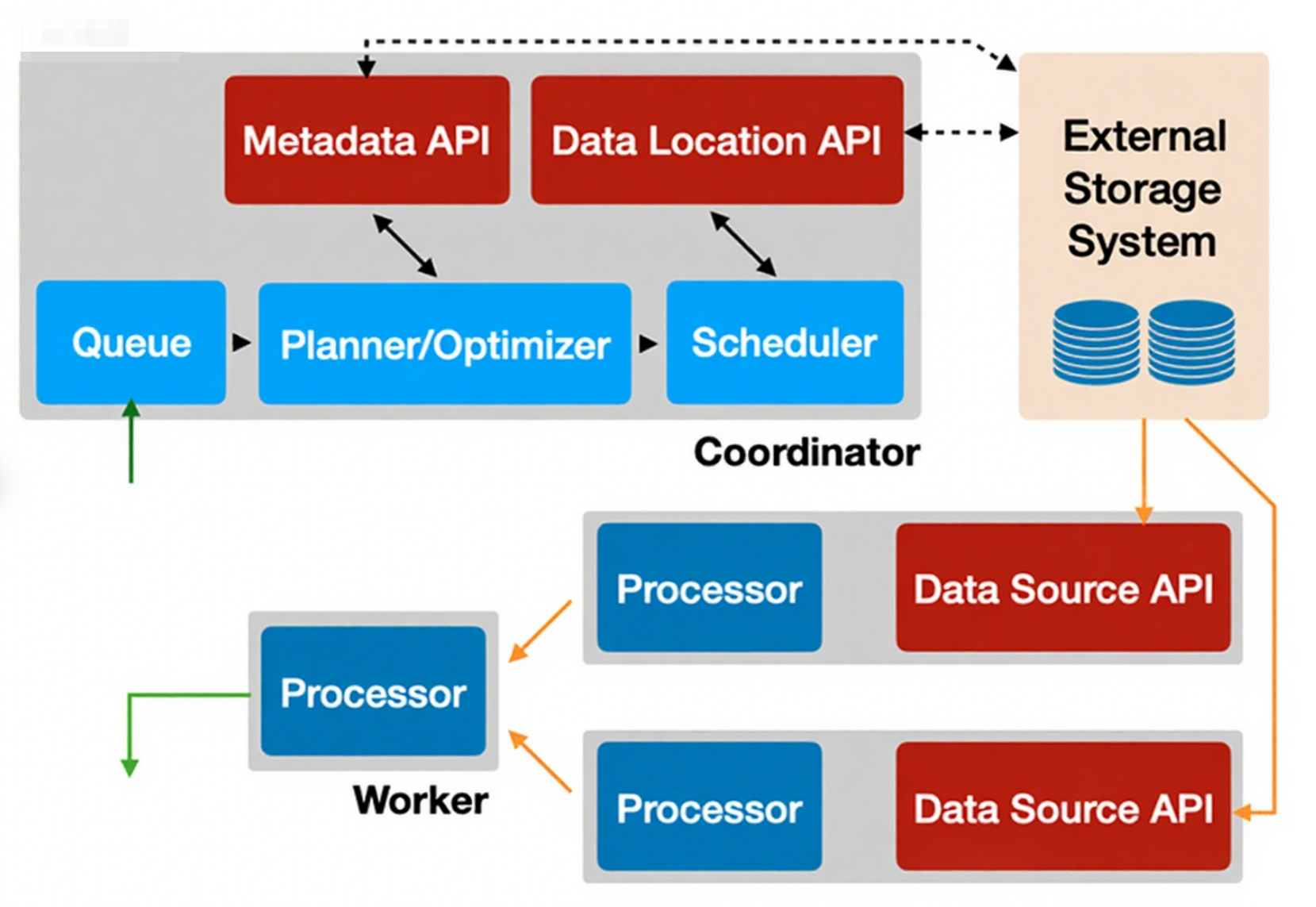
PrestoDB был создан в 2012 году в Facebook (Meta)* для предоставления быстрых распределённых возможностей SQL поверх различных источников (включая HDFS, S3, MySQL и Cassandra) без перемещения или преобразования данных. Trino появился в 2019 году как форк Presto, созданный его оригинальными авторами, с фокусом на улучшении производительности и добавлении поддержки облачных и современных Lakehouse‑архитектур. Эти движки остаются очень похожими и после форка различаются лишь в деталях.
*Компания Meta признана экстремистской на территории РФ и запрещена
На следующей схеме показана архитектура Presto/Trino. В Presto и Trino координатор парсит и планирует запрос, затем создаёт набор задач и сплитов (splits) базовых внешних хранилищ; каждый сплит передаётся рабочим узлам для чтения соответствующих данных.
OLAP‑движки для работы в реальном времени
StarRocks — высокопроизводительное аналитическое хранилище данных (DWH), реализующее многомерную аналитику, аналитику в реальном времени и высокую конкурентность за счёт векторизации, MPP‑архитектуры, CBO, умных материализованных представлений и колоночного движка с возможностью оперативных обновлений.
Архитектура StarRocks поддерживает две модели: Shared‑nothing и Shared‑Data. В Shared‑nothing данные загружаются в формат StarRocks и хранятся непосредственно в локальном хранилище узлов StarRocks Backend. Shared‑Data позволяет напрямую запрашивать внешние источники данных без копирования их в кластер StarRocks — аналогично Presto/Trino/Spark.
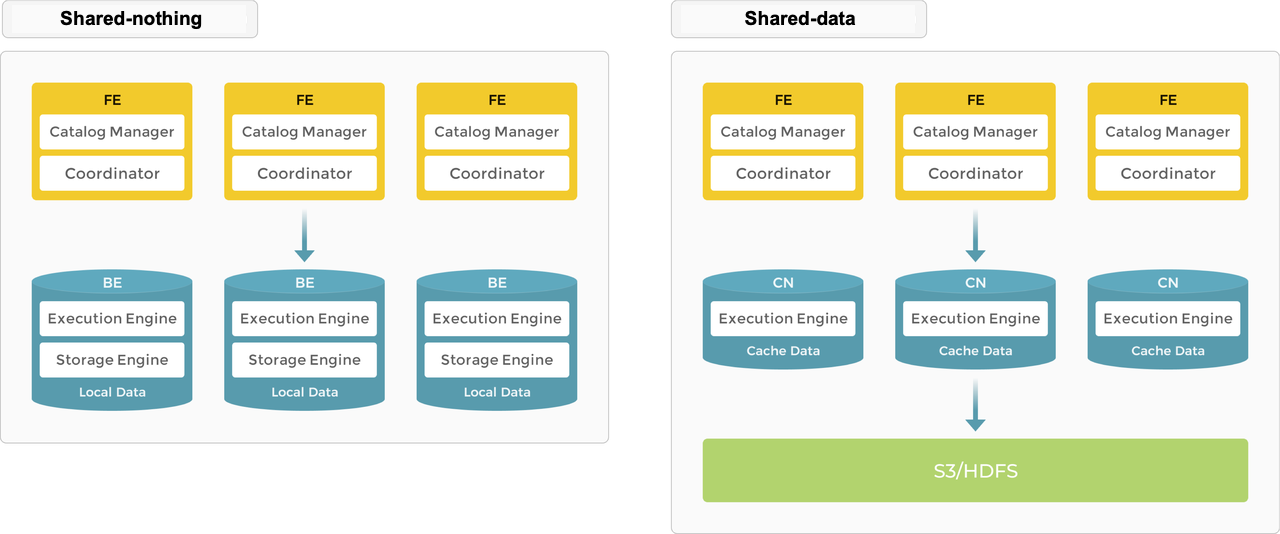
Используются два типа узлов: Frontend (FE) и Backend (BE)/Compute (CN). Узлы FE отвечают за управление метаданными и построение плана выполнения. Узлы BE исполняют план и хранят данные, ускоряя запросы за счёт локального хранения и обеспечивая высокую доступность посредством репликации. В конфигурации с общими данными (Shared‑Data) вместо BE используются вычислительные узлы (CN), которые выполняют те же функции, но не хранят данные.
ClickHouse был разработан в 2009 году, изначально для сервиса Yandex.Metrica — высоконагруженной веб‑аналитической платформы, обрабатывающей миллиарды событий в день с низкой задержкой. Существующие базы данных не справлялись с таким масштабом для аналитики в реальном времени с высокой конкурентностью, особенно на сложных фильтрах, агрегациях и соединениях. В ответ появился ClickHouse — быстрая OLAP‑СУБД для решения этих задач.
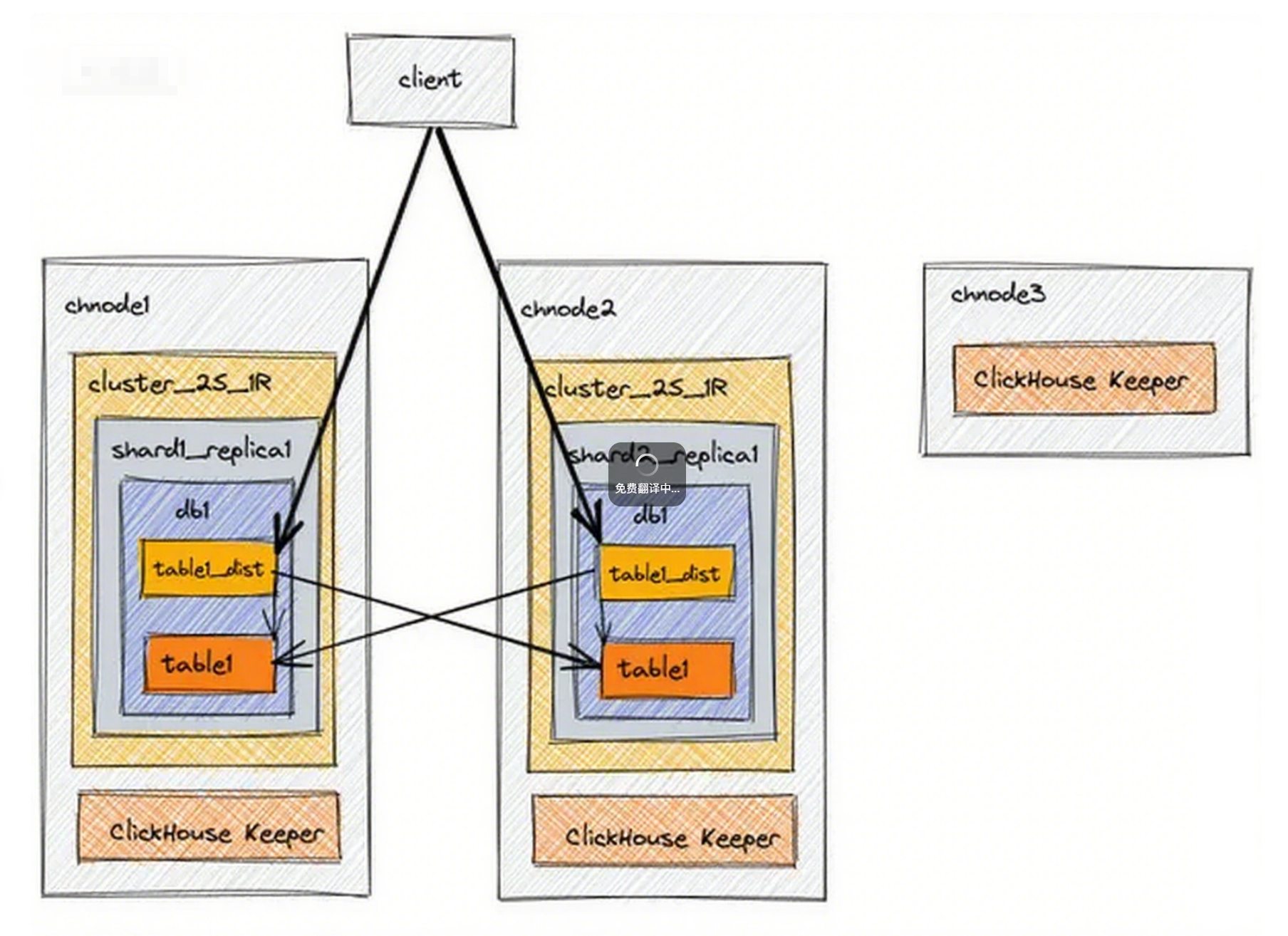
Архитектура ClickHouse использует колоночное хранение; операции выполняются над векторами (колоночными блоками), а данные векторов размещаются в реплицируемых шардах ClickHouse, что обеспечивает быстрое выполнение запросов и отказоустойчивость. Кроме того, ClickHouse позволяет запрашивать данные из облачных хранилищ, аналогично внешним таблицам в традиционных DWH.
Каждый распределённый исполнительный движок имеет свои сильные стороны: хотя почти все исполняют один и тот же SQL, детали реализации заметно различаются — исполнительные подсистемы, подходы к оптимизациям, обработка shuffle, кэширование, уровни векторизации и т. п.
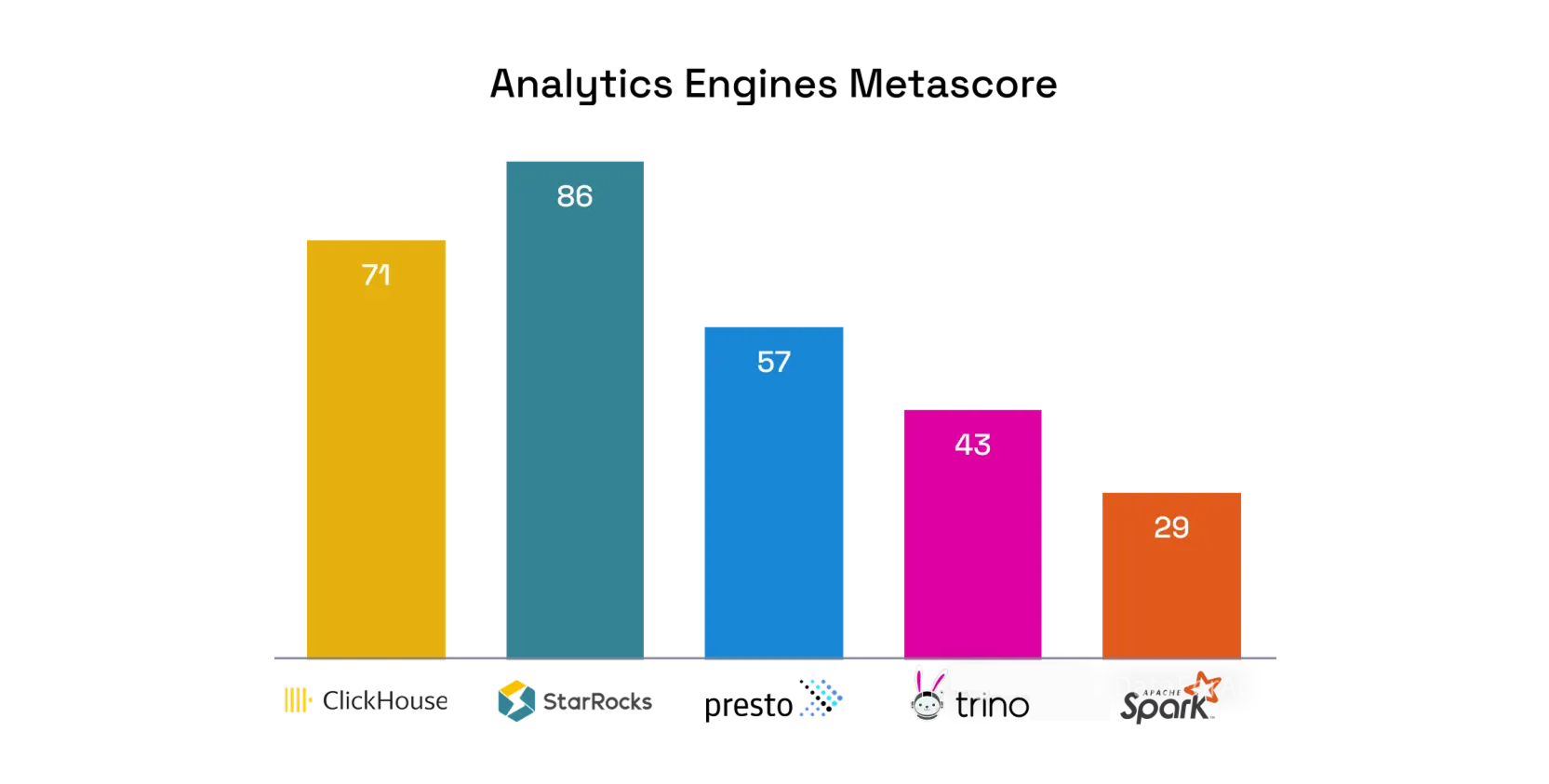
В сводной таблице ниже (по мотивам сравнения на сайте Onehouse и описанных в тексте критериев) каждому движку присваивается оценка: A = лучший вариант; B = хороший вариант; C = ниже среднего. Каждой оценке соответствует балл: A = 3, B = 2, C = 1. metascore — нормализованная сумма баллов по всем категориям.
Сводная таблица сравнения (оценки A/B/C и metascore)
Примечания:
- A = 3 балла, B = 2 балла, C = 1 балл.
- metascore рассчитан как сумма баллов по 5 категориям, нормализованная к максимуму 15 (деление на 15 и умножение на 100%).
- Таблица отражает выводы текста: «лучший/худший» в классе по каждой категории и качественные комментарии по архитектуре.
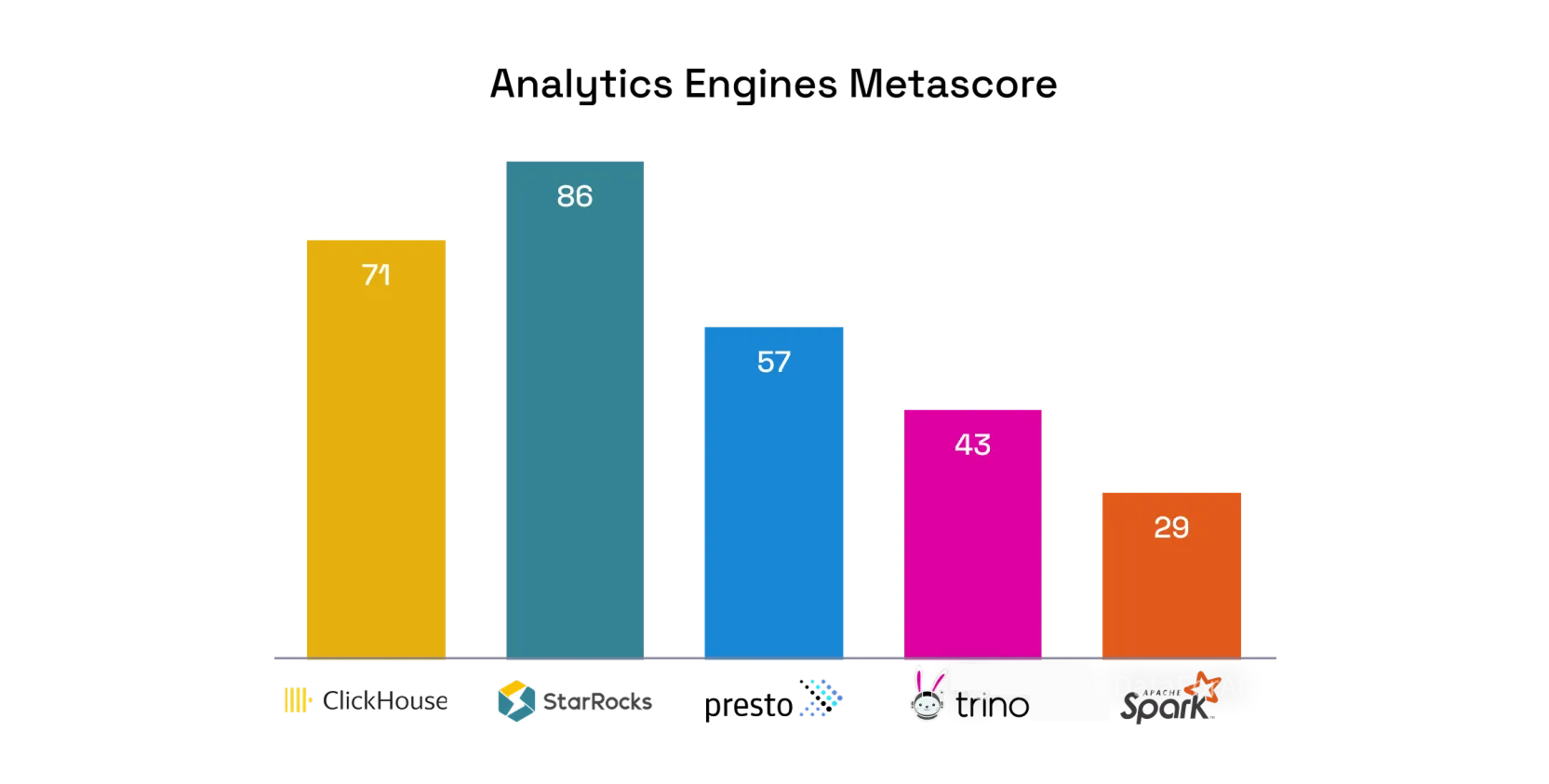
Рейтинг по metascore
- StarRocks — 73%
- ClickHouse — 73%
- Presto — 67%
- Apache Spark — 60%
- Trino — 60%
Сравнение по ключевым критериям
Скорость выполнения. Одним из ключевых критериев качества вычислительного движка выступает время ответа на запрос; также важны пропускная способность, отказоустойчивость и ресурсоёмкость.
Оптимизации на базе SIMD (Single Instruction, Multiple Data), позволяющие одной инструкции CPU обрабатывать сразу несколько элементов данных, дают заметное преимущество над поэлементной обработкой.
— 🏆 Лучший в классе: StarRocks, ClickHouse
— ❌ Худший в классе: Spark
Масштабируемость. Способность масштабировать кластер вверх/вниз на старте и по завершении запроса — важная составляющая отличной производительности и оптимизации затрат. Архитектуры с разделением хранения и вычислений упрощают масштабирование. Presto обеспечивает наиболее простую операционную модель на больших масштабах. Локальное хранение у StarRocks/ClickHouse усложняет масштабирование. Spark чаще используется для крупномасштабных ETL‑заданий и менее удобен для эластики интерактивных нагрузок.
— 🏆 Лучший в классе: Presto
— ❌ Худший в классе: Apache Spark
Конкурентное чтение/запись. Нужна эффективная обработка больших объёмов одновременных запросов с приоритизацией, чтобы важные запросы не блокировались. ClickHouse предоставляет самый тонкий и гибкий контроль над исполнением запросов. В отношении транзакций большинство движков ориентированы на OLAP и уступают типичным OLTP/онлайн‑БД.
— 🏆 Лучший в классе: ClickHouse
— ❌ Худший в классе: Apache Spark
Поддержка хранения. В эпоху открытых табличных форматов (Data Lake) по стратегии Lakehouse важно уметь читать/писать множество форматов. Spark поддерживает самый широкий спектр: через источники данных — Parquet, JSON, ORC, Avro, CSV и др.
— 🏆 Лучший в классе: Apache Spark
— ❌ Худший в классе: ClickHouse
Поддержка языков запросов. В эпоху ИИ и аналитики главные способы работы — SQL и Python. Apache Spark с PySpark обеспечивает лучший опыт работы с Python и позволяет выражать бизнес‑логику в Python‑функциях; другие движки обычно требуют определять логику на SQL через клиентские обёртки. Spark можно бесшовно использовать как Python‑библиотеку и как распределённый SQL‑движок.
— 🏆 Лучший в классе: Apache Spark
— ❌ Худший в классе: Trino, Presto
Выводы
Выбор оптимального движка для решения бизнес‑задач не ограничивается желаемыми техническими целями — он должен учитывать будущие потребности бизнеса и направление эволюции архитектуры.
Каждый движок имеет свои сильные стороны:
- Apache Spark обладает самой широкой поддержкой хранилищ и языков; он может подключаться к практически любым типам данных и работать с ними.
- Trino — отличный интерактивный SQL‑движок для ad hoc‑аналитики.
- Presto имеет общую историю с Trino, предоставляет превосходный интерактивный SQL и эффективно масштабируется.
- StarRocks предлагает сверхбыстрый векторизованный движок, но поддержка форматов файлов у него не так широка.
- ClickHouse также даёт сверхбыстрый векторизованный движок для ускорения OLAP, но ему не хватает эластичности масштабирования.
Независимо от выбора движка, настоящая сила — в умении комбинировать движки, масштабировать их и интегрировать с другими компонентами экосистемы под задачи бизнеса, не заковываясь в единственную архитектурную парадигму.

