Разработка системы заметок с нуля. Часть 1: проектирование микросервисной архитектуры

Серия материалов, в которой мы придумаем техническое задание, спроектируем систему и выстроим микросервисную архитектуру проекта.
Начинаем серию материалов, в которых мы спроектируем и разработаем систему заметок. Это история не про написание кода, а про микросервисную архитектуру и инфраструктурную обвязку вокруг нее.

Техническое задание
Давайте придумаем техническое задание и спроектируем систему на бумаге. Первым делом распишем функциональность, чтобы было понятно, что получится в итоге.
Основные возможности:
- регистрация и авторизация в системе,
- создание/изменение/удаление заметок,
- прикрепление файла,
- категоризация и тегирование заметок,
- полнотекстовый поиск.
Сделаем версию под браузер, приложения на Android и iOS могут появиться в будущем.
Основные страницы UI:
- авторизация,
- регистрация,
- список заметок,
- карточка заметки.
Заметки должны поддерживать формат Markdown и состоять из заголовка и тела. В ТЗ намеренно нет нефункциональных требований, таких как производительность, надёжность, катастрофоустойчивость и так далее, чтобы не усложнять систему.
Проектирование системы
Итак, функциональность нам известна, давайте проектировать. Начнём с выбора инфраструктуры.
CI/CD
Собирать систему и деплоить код будем при помощи CircleCI или GitHub Actions. Все сервисы будем упаковывать в Docker-контейнеры и запускать при помощи Docker-compose.
Система контроля версий
Уже есть репозиторий на GitHub. Он будет использоваться как монорепозиторий. Это ускорит разработку и уменьшит количество дополнительной работы с гитом. Весь код будет в свободном доступе под лицензией GPLv3.
Zipkin
Нам нужно дебажить сетевое взаимодействие между сервисами, поэтому мы используем стандарт Opentracing и в качестве реализации возьмем Zipkin. У него много готовых библиотек и для Python, и для Golang.
Search and filter
Для полнотекстового поиска и фильтрации мы возьмём стек ELK, а именно Elasticsearch и Logstash. На данном этапе это как стрелять из пушки по воробьям, вполне можно было организовать этот функционал на хранилище, но:
- в качестве обучения и демонстрации возможностей микросервисов это будет отличным примером;
- если сервисом начнут пользоваться люди, то мы уже подумали о масштабировании и производительности.
Для наполнения Elasticsearch данными будем настраивать ETL-процессы и использовать Apache Airflow.
Logs
Так как у нас уже есть Elasticsearch, мы будем туда заливать логи всех сервисов. Чтобы отслеживать пересечения логов бизнес-процессов по разным сервисам, будем добавлять в лог TraceId, который нам останется от Zipkin. Логи будем собирать агентом Telegraf или FileBeat.
Service Discovering and Configuration
Для Service Discovering используем Consul и его DNS-сервер. Логика следующая: сервис обращается к другому сервису по хостнейму, а резолвить хостнейм будет Consul.
Для конфигурации всех сервисов будем использовать встроенное в Consul key-value-хранилище. Возьмём утилиту Consul Template. Она будет следить за файлом шаблона и генерировать конфигурацию сервиса, которую он будет использовать при старте, а при изменении значений в Consul Consul Template будет рестартовать сервис.
Сервисы
Теперь посмотрим, какие сервисы у нас будут.
NoteService
Сервис с бизнес-логикой основной сущности. Реализуем основные операции: получение, создание, обновление и удаление. Использовать будем Golang, REST API, формат данных — JSON.
У сервиса будет своё хранилище. Возьмем документоориентированную MongoDB. Она легко масштабируется, формат данных — документ в виде JSON плюс шардирование «из коробки» — опять же пригодится, если будет нагрузка.
FileService
Для управления файлами заметок сделаем отдельный сервис. Скорее всего, это будет совместимое с S3 хранилище MinIO. Файлы будем хранить на файловой системе.
CategoryService
Для управления категориями сделаем отдельный сервис со своим хранилищем. Категории будем хранить в древовидной структуре, поэтому возьмем Neo4j — графовую базу данных. Её основная особенность в том, что коннекты между данными хранятся, а не вычисляются во время запроса. Также она использует язык запросов Cypher, который гораздо проще, чем SQL для написания запросов с неограниченной вложенностью.
Сервис будем делать на языке Python 3 и фреймворке Flask. Асинхронность здесь не так важна, к тому же запускать приложение мы будем при помощи Gunicorn, который сможет распараллелить инстансы сервиса.
APIService
Мы будем делать только веб-приложение без мобильных клиентов, но так как в будущем они могут появиться, нам нужен отдельный сервис с API.
API у нас по большей степени простой CRUD, различного функционала немного, и весь он вращается вокруг заметок. Основных сущностей также мало, поэтому будем готовить обычный REST API.
SearchService
Для полнотекстового поиска сделаем SearchService. Именно он будет обладать доступом в Elasticsearch. Работать с Elasticsearch проще на Python, поэтому выбор очевиден.
UserService
Для пользователей системы будет отдельный сервис также с REST API и хранилищем PostgreSQL.
WebApplication
Для создания веб-приложения используем Vue.js или React.js.
В итоге мы получили такую архитектуру:
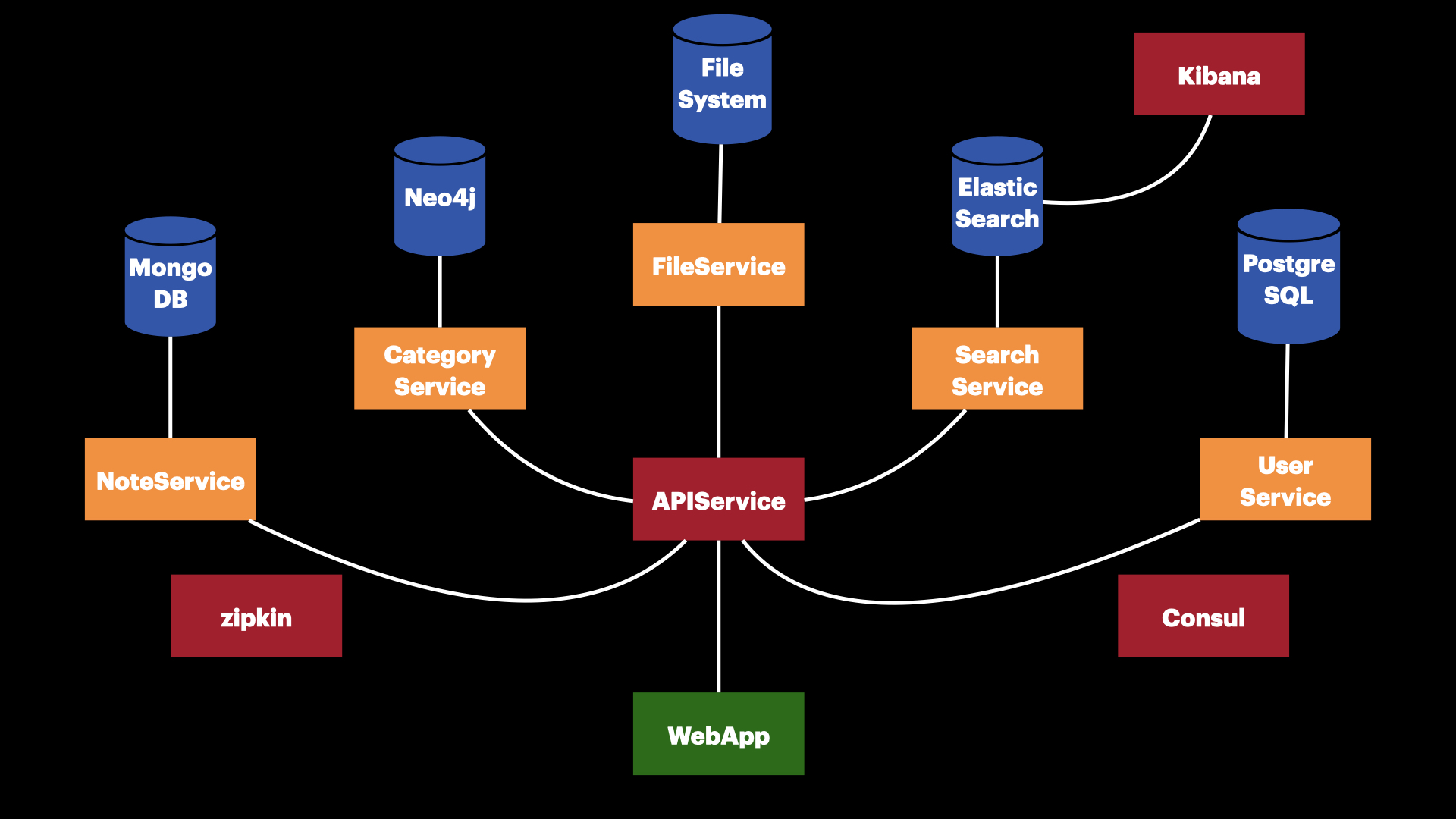
Если в системе появятся асинхронные операции, например, отчёты, то мы легко внедрим в эту архитектуру очереди событий.
В следующей части мы начнём разработку системы. Будут показаны основные моменты процесса разработки и конфигурации используемых продуктов.
Группа автора «ВКонтакте», Telegram, Twitter.

6К открытий6К показов

Рассказали, какие рекомендательные системы используют и как их улучшают в онлайн-сервисе для читающих людей от МТС.
Рассмотрели функцию print в Python и рассказали о её работе. Описали, что такое аргументы print, зачем они нужны и как их использовать.

Сравнили GPT4, LLaMA, Yandex GPT2, GigaChat c позиции разработчика-внедренца: стоимость, число параметров, цену и проч.
В этой статье мы рассмотрим 5 бесплатных UI-шаблонов для ChatGPT на GitHub, которые можно использовать при интеграции ChatGPT в приложения.