


Разработка системы заметок с нуля. Часть 3: знакомство с Neo4j, работа над микросервисами CategoryService и APIService

Основы работы с графовой базой данных Neo4j на примере системы заметок, а также продолжение разработки проекта с микросервисной архитектурой.
4К открытий5К показов
Мы продолжаем разрабатывать систему заметок с нуля. В третьей части серии материалов мы познакомимся с графовой базой Neo4j, напишем CategoryService и реализуем клиента к новому сервису в APIService.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Во второй части мы спроектировали и разработали RESTful API Service на Golang cо Swagger и авторизацией.
Теперь разработаем сервис управления категориями CategoryService. Категории мы делаем в виде дерева с большой вложенностью, в теории — бесконечной. Сервис будем разрабатывать на языке Python, а в качестве хранилища используем Neo4j.
Исходный код проекта на Github
Подробности в видео и текстовой расшифровке под ним.

Запуск графовой базы данных Neo4j
Neo4j — это высокопроизводительная NoSQL база данных, основанная на принципе графов. В ней нет такого понятия, как таблицы со строго заданными полями. Она оперирует гибкой структурой в виде нод и связей между ними.
Запускать Neo4j мы будем в Docker. Готовые образы на есть hub.docker.com. Они делятся на два вида: Enterprise и Community-версии. Нам надо выбрать тег образа, который будем использовать.
Важно: никогда не используйте тег latest, чтобы избежать ситуаций, когда вы запустите обновление контейнера, он обновится на последнюю версию, и у вас все сломается. Это связано с тем, что последнее обновление может содержать несовместимые изменения с вашей текущей версией. Например, у GitLab есть целая политика обновления как мажорных, так и минорных версий. Обновиться с 11 на 13 версию сразу не получится, придётся пройти длинный путь последовательных обновлений: 11.5.0 -> 11.11.8 -> 12.0.12 -> 12.10.14 -> 13.0.12 -> 13.2.3.
Но вернёмся к Neo4j. В официальной документации есть статья про запуск в Docker-контейнере. Возьмём оттуда команду docker run и преобразуем её в простой docker-compose.
Версия docker-compose — 3.9. Затем идёт определение сервисов. У нас будет сервис Neo4j. Укажем, чтобы он всегда рестартовал, если упадет. Образ мы будем использовать с тегом 4.2.3. Далее — имя контейнера. Указываем порты, которые мы пробрасываем на хостовую машину. На порте 7474 будет доступен веб-интерфейс по протоколу HTTP, а 7687 используется для общения с Neo4j по протоколу BOLT. Далее пробрасываем volumes. Кроме тех, что указаны в команде, я ещё пробросил /var/lib/neo4j/conf, чтобы был доступ в файлу конфигурации neo4j.conf.
По умолчанию Neo4j создает пользователя neo4j с паролем neo4j и при первом входе требует сменить пароль. Этот этап можно пропустить, задав пароль через переменную среду NEO4J_AUTH.

Готовый файл запускаем командой^
Дополнительно нам понадобятся процедуры APOC, которые расширяют функционал запросов к Neo4j. Для этого идём в репозиторий этих процедур, скачиваем jar-файл apoc-4.2.0.2-all.jar и кладём в наш volume ./export/neo4j/plugins.
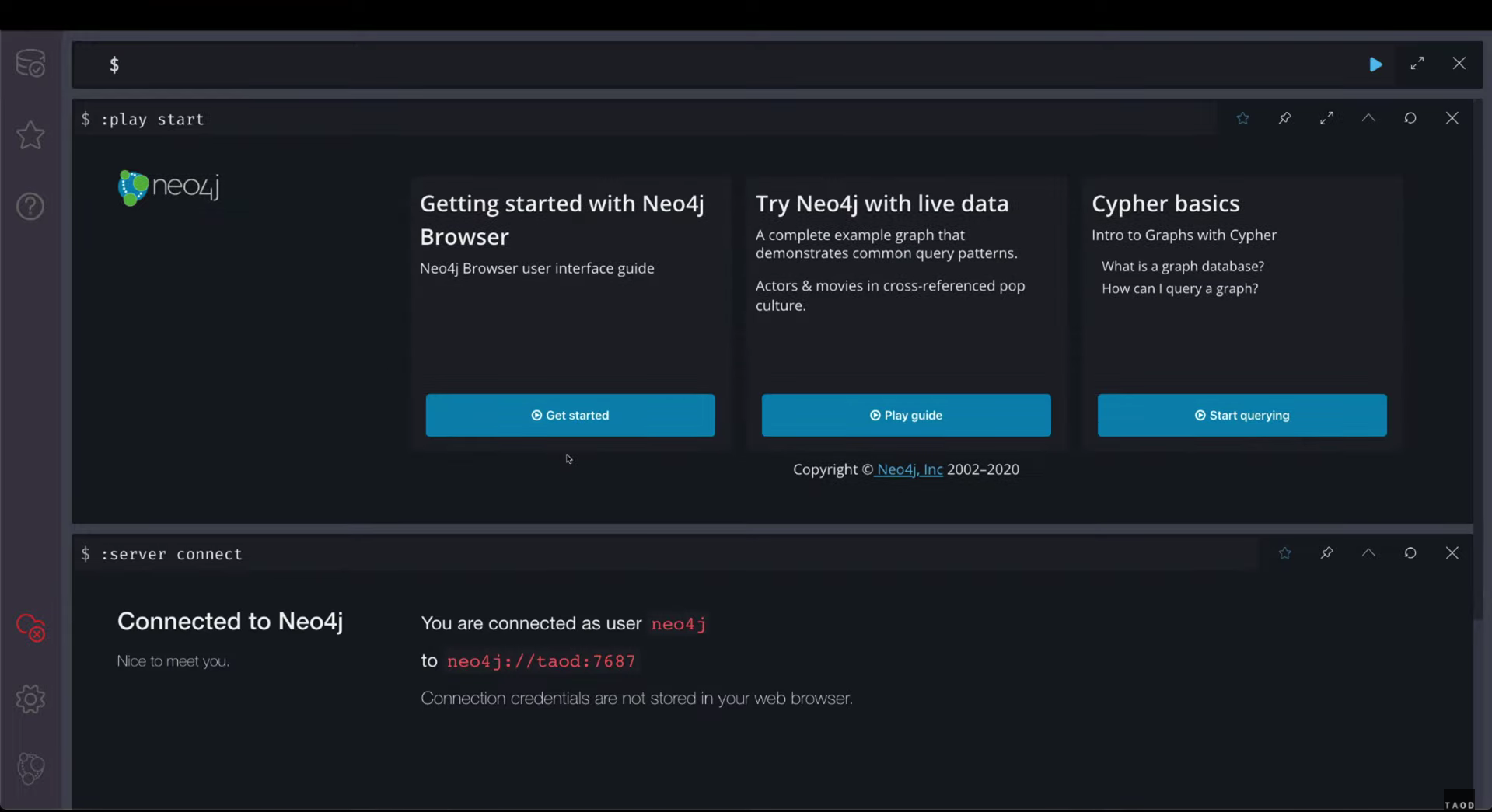
Работа через веб-интерфейс Neo4j
После установки Neo4j открываем веб-интерфейс, который висит на порте 7474. Коннектимся к дефолтной базе Neo4j. Вводим пароль, который указали в compose-файле. Нас встречает красивый интерфейс с тёмной темой. Он состоит из нескольких секций:
- Editor — здесь вводим команды на языке Cypher, чтобы работать с графом. Хоткей Shift + Enter позволяет вводить команду в несколько строк. Чтобы запустить выражение, нажмите Ctrl + Enter (CMD + Enter). Также ведётся полная история всех введённых команд.
- Stream — для отображения результата выполненной команды. Для каждой выполненной команды создаётся отдельный Stream.
- Code отображает все полученные и отправленные данные от сервера.
- Sidebar отображает мета-дату базы данных и основную информацию. Сохранённые скрипты можно раскидать по папкам. Также тут размещены ссылки на документацию и информация о лицензии.
Основные команды языка Cypher
Язык Cypher создан специально для взаимодействия с графами. Он является декларативным, похож на SQL и использует паттерны, чтобы описать граф. Давайте разберёмся с основными командами, которые нам нужны.
Это команда создания ноды, которая будет представлять пользователя. CREATE — это ключевое слово, после него идет определение ноды в круглых скобках, u — это алиас, который мы можем использовать в запросе, он не сохраняется в базу. Далее через двоеточие указываем лейбл, их можно указать несколько. Они сохраняются в базе и могут быть использованы для идентификации. После лейблов в фигурных скобках в формате JSON указываются свойства ноды.
Выполняем команду, нажимая Cmd + Enter. Создаётся новое окно стрима, где отображается результат работы нашей команды. В данном случае в стриме будет отчёт о том, что было создано.
Теперь давайте найдём нашу ноду. Пишем ключевое слово MATCH, далее определяем, какие ноды ищем и возвращаем по алиасу.
Теперь создадим ещё одну ноду и отношение с нодой пользователя.
Пишем ключевое слово MATCH и ноду, далее идёт ключевое слово WHERE — ищем пользователя с id = 1. После нахождения мы можем создать новую ноду:
- Пишем CREATE.
- Формализуем ноду «Категории».
- Указываем свойство id и вызываем функцию APOC, которая генерирует UUID. Чтобы она работала, мы копировали ранее jar-файл.
После создания ноды создаём отношение:
- Добавляем ключевое слово CREATE.
- Пишем ноду нашего юзера.
- Создаём отношение.
- Возвращаем id созданной категории.
Отношение состоит из 3 элементов: направление отношения по отношению к пользователю, алиас и лейбл, направление отношения по отношению к ноде категории. То есть мы можем создать отношение как от юзера к категории, так и от категории к юзеру. У отношений также могут быть свойства. Они задаются в формате JSON. Это крайне удобно для сложных структур. Например, можно было для отношений пользователя к группам и категорий к подкатегориям сделать свойства отношения created_date.
Чтобы посмотреть, как Neo4j обрабатывает наш запрос, добавим ключевое слово EXPLAIN или PROFILE.
Мы увидим план запроса, который можно проанализировать, чтобы понять, насколько он хорош или плох.

Посмотреть историю команд можно командой :history, очистить все стримы — командой :clear.
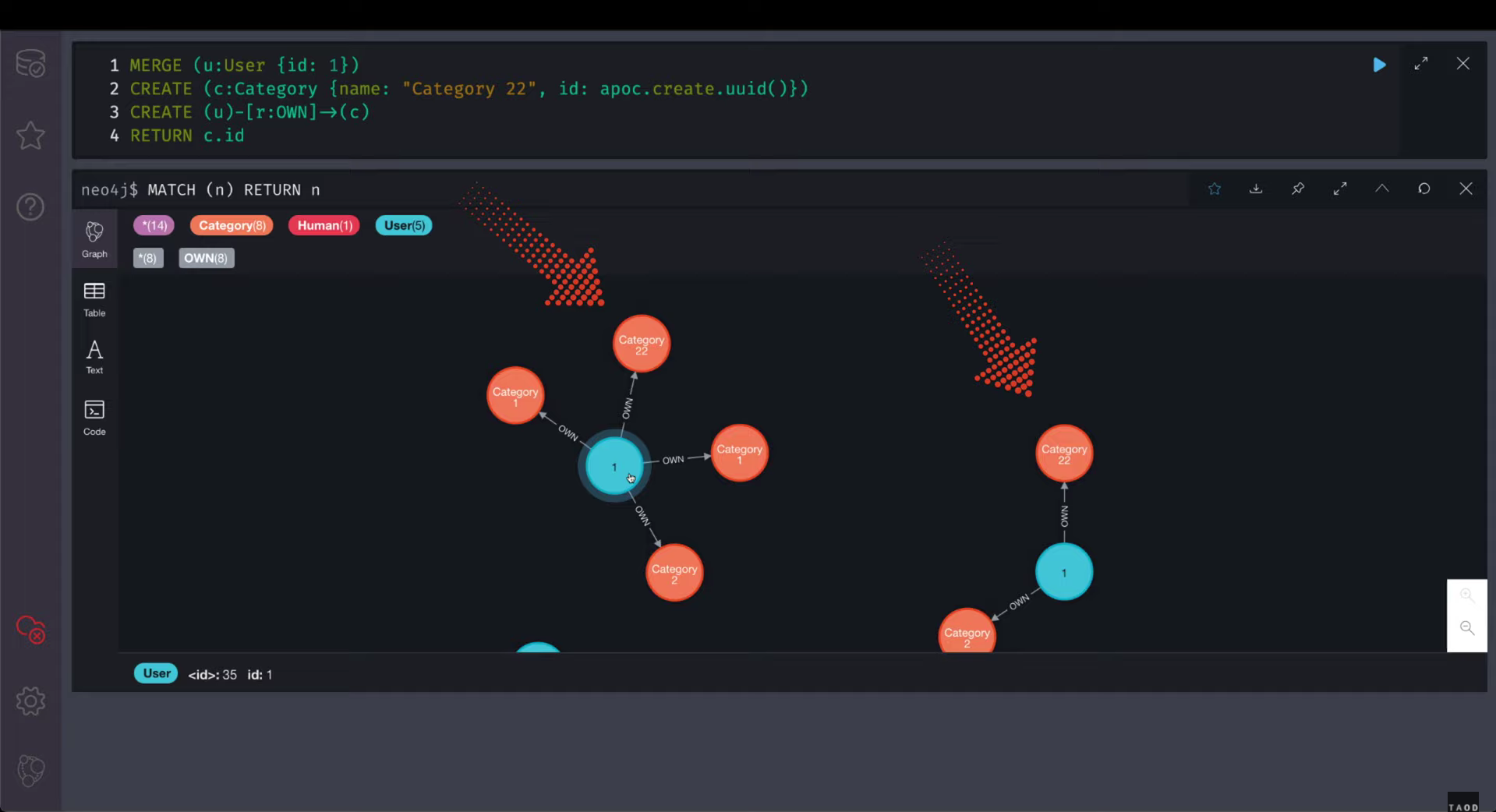
Давайте создадим ещё немного нод и отношений, чтобы можно было выполнить запрос на поиск всех нод и всех отношений:
У нас получилось создать две ноды пользователей с одинаковым полем id, так как уникальным идентификатором по умолчанию является внутренний идентификатор ноды , который генерирует сам Neo4j.
Запросы, которые будут использоваться в нашем сервисе
Создание ноды пользователя мы рассмотрели. Но мы будем делать это вместе с командой создания рутовой категории следующим образом:
Используем ключевое слово MERGE, которое создаст новую ноду, если пользователя с таким id нет, или найдёт все ноды с таким id. Создаём новую ноду «Категории» и связь между нодой пользователя и категории. В результате мы видим два JSONа и две созданные ноды с одинаковым названием, потому что первый запрос на матчинг пользователя нашёл двух пользователей с id равным единице и создал две категории и два отношения.
Рутовая категория — это категория, которая имеет связь с пользователем. Под категорией я имею в виду категории, которые не связаны с пользователем.
Теперь нам нужен запрос на создание ноды подкатегории и отношения с рутовой категорией:
Находим ноду категории по идентификатору. Далее создаём категорию и отношение между категориями. Для связи используем лейбл CHILD, а не OWN как для отношения между нодами пользователя и рутовой категории.
Нам также нужен запрос, который вернёт дерево всех нод категорий со всеми подкатегориями пользователя:
Мы ищем от стартовой ноды, пока не дойдём до ноды, у которой нет выходных связей. В MATCH мы пишем path =. Таким образом мы создаём объект с типом Path, в котором находятся все найденные ноды. Это упрощает возврат всего графа всех категорий. Этот запрос отлично выводит граф в Neo4j в браузере, но для кода нам нужен на выходе древовидный JSON. Для этого соберём path в список и отдадим его функции apoc.convert.toTree, чтобы получить выходной древовидный JSON. Но перед его выводом удалим вторую ноду пользователя по внутреннему идентификатору:
Теперь модифицируем нашу команду для получения дерева категорий. Добавляем ключевое слово WITH, собираем наш путь в список нод и вызываем функцию apoc.convert.toTree, передавая на вход список нод. В результате получаем древовидный JSON.
Ещё нам нужно проверять наличие родительское категории, чтобы понимать, сможем ли мы создать подкатегорию. Сделать это можно при помощи следующего запроса:
В результате выполнения запроса вернётся true или false.
Также нам нужно каскадно удалять категории. Чтобы сделать это, мы ищем все ноды от стартовой категории, которую хотим удалить, убираем связи и удаляем их.
Во время разработки мне очень пригодился запрос на удаление всех нод. Ключевое слово DETACH позволяет удалять связанные ноды каскадно.
Создание CategoryService
Писать будем на Python.
Маленький disclaimer: я на Python пишу в таком же стиле, как на Java, так как Java был моим первым языком программирования. Знаю, что это не дзен и что так не принято, но такой код легче тестировать, в нём меньше ошибок, он более читаемый.
Сначала создадим venv и установим нужные библиотеки. Будем использовать:
- Flask как минималистичный веб-фреймоворк.
- Flask-CORS для возможности обращения с разных доменов.
- Flask-RESTful, чтобы было удобнее создавать классы с ресурсами. Этот проект забросили, если знаете достойную замену, напишите, пожалуйста, в комментариях.
- Flask-Injector для реализации паттерна Dependency Injection, чтобы не было глобальных импортов.
- PyYAML для работы с форматом данных YAML.
Начнём с главного файла app.py и с конфига приложения.
- Создаём класс конфига. Почти везде я буду использовать слоты для классов. Это уменьшает вес объектов, но лишает объекты свойства dict, об этом нужно помнить.
- Конфиг мы будем вычитывать из YAML-файла. Поэтому в конструкторе получаем путь до файла и сразу вызываем функцию read, которая вычитает файл.
- Проверяем, что такой файл есть. Если его нет, то выбрасываем ошибку.
- В контексте открываем файл и вычитываем содержимое. Тут же парсим его при помощи библиотеки PyYAML.
- Проходимся по содержимому.
- Далее мы будем вызывать метод setattr, чтобы засетить слоты в нашем классе. Если ключ есть в слотах, мы сеттим этот атрибут.
Создадим YAML-файл с конфигурацией. В нашем конфиге будет переменная debug. Она нужна для разработки, например, дополнительного логирования или перехвата ошибок.
Для констант создаём файл constants.py. Там мы будем хранить все константы приложения, например, путь до конфиг-файла и путь до папки с логами.
Возвращаемся к app.py. Следующий важный компонент — это логирование.
- Создаём дефолтный логер с уровнем DEBUG.
- Создаём FileHandler, чтобы наши логи попадали в файл.
- Формат записи в логе мы определяем при помощи форматтера. У него особый язык, который описан в документации.
- Добавляем в логер наш хендлер.
- Создаём основной объект нашего приложения app, настраиваем его, а конфиг сеттим внутрь нашего объекта. Это позволит конфигурировать сам Flask через наш конфиг.
- Оборачиваем объект приложения объектом Api из библиотеки Flask-RESTful. Теперь мы сможем регистрировать ресурсы в объекте api.
- Оставляем место, где у нас будет injector для Dependency Injection.
- Пишем глобальную обработку ошибок.
Метод errorhandler будет перехватывать все исключения типа AppException и вызывать функцию app_exception_handler. Теперь нам нужно создать такой класс исключения. Наследовать его будем от класса Exception. Также мы сделаем систему ошибок в нашем приложении. AppException в конструкторе будет принимать на себя параметр exc_data, который может являться enum AppError и состоит из полей error: сообщение об ошибке, error_code — код ошибки и developer_message — сообщение для разработчика.
Различные кастомные обработчики я обычно называю помощниками. Поэтому создаю пакет helpers и там в файле flask.py реализую функцию обработки AppException. Также, если приложение не в дебаг-режиме, то мы перехватываем вообще все исключения, даже те, которые не обрабатываем. Например, где-нибудь мы поделим на 0 и не обработаем. Это нужно для продакшен-режима, когда пользователь не должен видеть разные HTML-страницы с ошибками или трейсы. Для этого создаём функцию uncaught_exception_handler, которая пишет в лог и вызывает функцию обработки AppException с ошибкой системы. У нас её как раз нет, поэтому возвращаемся и реализовываем enum AppError, добавляем в него SYSTEM_ERROR.
Мы будем добавлять в enum ошибки по мере их появления. Запускаем приложение и проверяем, что в конфиге есть все наши настройки.
Разработка DAO-слоя для доступа к Neo4j
Мы будем реализовывать классический DAO-паттерн. Будет абстрактный класс Storage, который является по сути интерфейсом с абстрактными методами, и конкретная реализация с Neo4j. Это позволит не привязываться к конкретному хранилищу. Если возникнет необходимость его сменить, это можно будет сделать, создав ещё одну реализацию и изменив класс в контейнере зависимостей.
В классе с реализацией для Neo4j мы создаём объект Graph и передаём ему параметры для подключения. Для понимания того, что надо передать классу, чтобы присоединиться, есть два пути: смотреть в документацию или в исходники. Оба имеют право на жизнь.
Выполнение любого запроса для Neo4j — это исполнение команды Cypher. Создаём метод execute_cypher и все методы реализуем одинаково: вызываем метод execute_cypher и возвращаем прочитанные данные из курсора. С первого взгляда выглядит как костыль. Но это условность, которая даёт гибкость в смене хранилища, при этом проблем с реализацией или тестируемостью нет.
Далее создаём ресурсы категорий. Библиотека Flask-RESTful даёт возможность создавать ресурсы в виде классов с методами get, post, put, delete. Создав метод get, понимаем, что нам нужен сервис управления категориями, а создав класс сервиса, понимаем, что ему нужен DAO для доступа к категориям. Создаём класс-интерфейс CategoryDAO, который мы и будем инжектить, и реализацию этого класса под Neo4j.
Пришло время запросов, которые мы рассмотрели ранее.
- Идём в Neo4j и ещё раз проверяем, что запросы работают корректно.
- Переносим запрос поиска всех категорий пользователя из Neo4j в код сервиса. Попутно везде проставляем возвращаемые значения, где забыли.
- Возвращаемся в сервис, добавляем в конструктор логер и реализуем метод получения категорий.
- Разбираемся с методами сервиса и DAO-слоя. Основная логика простая: сервис вызывает метод DAO и получает данные, с которыми он может что-то сделать и вернуть.
Надо протестировать хотя бы получение всех категорий. Но для этого нам надо в сервисе получить реализацию интерфейса CategoryDAO. Это значит, что пришло время Dependency Injection.
- В основном файле app.py создаём объект Injector, который на вход принимает массив.
- Создаём объект FlaskInjector, которому отдаём наш объект app и созданный Injector.
- Создаём отдельный файл di.py.
- В файле di.py создаём классы модулей для наших зависимостей.
В случае со StorageModule для создания объекта Neo4jStorage нам нужны данные подключения к Neo4j из конфига. Поэтому в конструкторе передаем конфиг, а в методе configure уже используем его для создания экземпляра класса Neo4jStorage и биндим интерфейс Storage на объект нашей реализации. Также указываем параметр scope со значением singleton, то есть один объект на все приложение. Кроме того, там можно указать request, и тогда объект будет создаваться на каждый запрос к API. Таким же способом биндим интерфейс CategoryDAO на реализацию Neo4jCategoryDAO. Далее создаём подобный модуль для логера, чтобы и его можно было инжектить в конструкторе классов.
Заполняем массив Injector в файле app.py нашими модулями и проставляем декоратор @inject над конструкторами, куда инжектим наши классы. В ресурсах мы инжектим CategoryService, в CategoryService инжектим CategoryDAO, а в реализации Neo4jCategoryDAO инжектим Storage.
У нас будет два ресурса: CategoriesResource и CategoryResource.
- Реализуем метод GET у ресурса списка категорий.
- Вызываем сервис категорий, чтобы получить список категорий пользователя.
- Протестируем этот метод. Создаём HTTP скетч и делаем запрос.
- Первый тест сразу покажет все ошибки и опечатки. После исправлений проходимся в дебаге по всему процессу и смотрим, что происходит.
- Мы успешно получили данные из Neo4j. Парсим полученные данные от стораджа.
Тут надо отметить, что ключ value — это стандартный ключ, генерируемый Neo4j, а вот ключ own — это уже связь между пользователем и его рутовой категорией. У категории есть ключ child, что обозначает связь между рутовой категорией и подкатегорий.
Чтобы распарсить древовидный JSON, нам очевидно нужна рекурсивная функция.
- Создаём функцию _parse_categories и понимаем, что нам не хватает модели Category.
- Создаём пакет model в DAO и в нем организуем три файла: base.py для базовой модели методов, dto.py для реализации паттерна DTO и model.py для данных из БД.
DTO — это паттерн для оперирования входными данными от пользователя. Они упаковываются в класс DTO. Сервисы работают с ними, а модель — это уже полное представление данных из БД. Реализовывать модели и DTO будем на data-классах.
При реализации модели Category есть один нюанс. Так как категория содержит в себе подкатегории, то модель должна содержать поле с массивом это же класса. Python так не позволяет сделать, так как он не видит этого класса, для него он не создан. Обойти это можно строковой аннотацией и объектом List из пакета Typing. Все классы будем наследовать от базового класса Base. У него будут общие методы, например, преобразование объекта в словарь, исключая пустые поля. Это нужно, чтобы в итоговом JSON не было пустых полей.
DTO создаются на каждое действие пользователя. В нашем случае это Create, Update и Delete. Разные DTO содержат разные данные и разные обязательные поля. Например, для CreateCategoryDTO не нужен uuid категории, так как его еще не существует. В вот для Delete и Update uuid категории обязательно нужен.
Возвращаемся к парсингу категорий. Тут всё просто.
- Проходим по списку, собираем категорию.
- Если у категории есть дети, рекурсивно вызываем функцию, чтобы получить список категорий детей категории.
- Доделываем метод get_categories у сервиса категорий.
- Делаем проверку на то, что пользователь, чьи категории запрашиваются, существует, иначе отдаем 404 и ошибку USER_NOT_FOUND.
- Реализуем методы создания, обновления и удаления категории. Я вызываю несуществующие методы, чтобы понять, какие методы будут нужны. Также попутно дополняю DTO-классы необходимыми полями, после чего массово объявляю все нужные методы в интерфейсе CategoryDAO и потом реализую эти методы в DAO-реализации для Neo4j.
- Запросы всё так же тестируем в веб-интерфейсе Neo4j. Графы выглядят очень красиво, а язык Cypher крайне удобен, нет проблем с запросами бесконечной вложенности.
Есть информация, что Neo4j падает при 1 миллионе нод и 500 связей между ними. Я не тестировал, но думаю, что если применить масштабирование и/или шардирование, то эту проблему можно решить.
После реализации всех методов в DAO возвращаемся к ресурсам.
Получаем user_uuid из Query Path. Запускаем и проверяем получение всех категорий без указания user_uuid. Получаем код 500 вместо 404. Cтандартная ошибка вместо нашего User not found. Начинаю разбираться, почему ошибка не моя:
- Проверяю функции обработки ошибок.
- Понимаю, что в ошибке не хватает HTTP-кода возврата.
- Нахожу ошибку в классе исключения. Я не забирал данные из переданной ошибки в исключении.
- После исправления я всё-таки перехватил ошибку. Но метод jsonify упал с ошибкой, так как не смог сериализовать объект AppException. Поэтому передаем в jsonify не сам объект, а вызываем у него magic-метод dict. Теперь всё хорошо, кроме HTTP-кода.
Проблема была в месте присваивания HTTP-кода в классе AppException. Ошибка корректная. Теперь проверяем получение всех категорий с заданным user_uuid. Видим, что все объекты получены корректно. Но теперь код падает на сериализации списка категорий. Проблема в том, что стандартный сериализатор JSON не знает, что делать с классом Category, надо ему рассказать об этом.
Создаём в пакете helpers файл json.py. В нём создаём класс CustomJSONEncoder с методом default. Здесь мы пытаемся создать универсальный сериализатор, который будет уметь сериализовать строки, энамы, словари, итерируемые объекты, объекты со слотами или без слотов, но с объектом dict. Функция должна рекурсивной, чтобы сериализатор корректно работал с вложенными объектами. Поэтому выделяем код в отдельный метод to_dict и рекурсивно вызываем на каждый объект внутри объекта, а метод to_dict вызываем в методе default. Проверяем еще раз — успех. Мы получили древовидный JSON.
Тут можно спросить, зачем я десериализую JSON от Neo4j в объекты, а потом опять сериализую его в JSON, чтобы отдать клиенту. Ответ простой: если потребуется реализовать какую-то логику по обогащению данных или изменится структура в хранилище, структура и модели данных не изменятся, а значит не изменится и контракт сервиса. В материале про микросервисы я уже объяснял, что очень важно проектировать сервисы таким образом, чтобы их контракты не менялись даже при изменении логики работы самого сервиса.
Методы создания, обновления и удаления категории
Далее реализуем метод post для создания категории. Я не хочу вручную получать данные из body и создавать DTO. Поэтому применяю маршалинг. Пишу декоратор masrshal_with, в котором указываю, что вернёт метод, и декоратор use_kwargs, для которого указываю, какую DTO я жду на входе. То есть этот декоратор возьмет body из запроса и провалидирует его относительно data-класса, который я ему задал в параметрах.
Чтобы это работало, нужно реализовать метод to_schema во всех DTO. Для этого в классе Base реализуем метод to_schema. Воспользуемся библиотекой marshmallow_dataclass и методом class_schema. Теперь в сигнатуре метода хендлера я могу объявить аргумент валидируемой DTO. В методе post создания категории мы ничего не возвращаем, кроме заголовка Location с URI до созданной категории. Из этого заголовка будет легко получить uuid созданной категории. Пишем тест на создание рутовой категории (то есть без параметра parent_uuid) и проверяем. Видим, что наша DTO десерелиазована и все данные на месте. Главное, что категория создана. Теперь пишем тест на создание подкатегории, указывая parent_uuid в body, и проверяем, что такая категория была создана.
Теперь создаём ресурс для работы с конкретной категорией, а также методами patch для обновления и delete для удаления. Пишем для них тесты, проверяем функционал. Также добавим наследования классов ресурсов от класса MethodResource. Это нужно для корректной работы декораторов и возможности последующей генерации swagger-файла на основе кода. Запускаем тест и получаем ошибку в формате HTML. Давайте обработаем такие ошибки отдельно. Создаём функцию handle_request_parse_error с декоратором parser.error_handler. В случае такой ошибки выполняем функцию abort и передаём ей ошибки схемы валидации. Повторяем тест и получаем JSON с ошибкой валидации схемы. Далее финальное тестирование, фиксим опечатки. Сервис готов.
Ещё можно сделать валидацию пользовательских данных, например, проверку формата uuid для полей user_uuid и parent_uuid. Также можно провалидировать имя категории, чтобы это была строка, ограничить её по длине, нормализовать и сделать ограничение на спецсимволы.
Доработка APIService
Теперь нужно сделать реализацию клиента к новому CategoryService в нашем APIService.
- Создаём папку rest в pkg.
- Создаём файл client.go, в котором у нас будут общие структуры для общения с RESTful-сервисом.
- Добавляем FilterOptions — это структура для возможности фильтрации список, которая состоит из поля, оператора и значений.
- Делаем метод BuildURL, который будет формировать итоговый URL из базового URL ресурса, к которому мы обращаемся, и фильтров, которые, по сути, являются ключами и значениями Query Path. В BuildURL мы парсим базовый URL, добавляем в него ключи и значения из фильтров.
- Создаём метод ToStringWF у фильтра, чтобы склеить оператор и значения.
- Добавляем структуру ошибки API с полями Error, ErrorCode и DeveloperMessage. Это те же поля, что были в классе AppError в CategoryService.
- В internal создаём папку client.
- В директории client создаём папку category и файл client.go.
- В директории category создаём файлы model.go и service.go.
- В файле model.go описываем структуру «Категории». Здесь уже нет проблемы с указанием собственного класса в полях класса, как это было в Python.
- Применяем паттерн DTO и создаём DTO-модели.
Код можно немного зарефакторить. Идея следующая: в папке rest будет общий клиент для всех RESTful-сервисов в файле client.go, а в файле url.go — уже построение общего URL и структуры API.
- Базовый клиент состоит из URL, HTTP-клиента и мьютекса для многопоточной работы.
- Создаём метод SendRequest, который будет отправлять запрос и возвращать ответ.
- Лочим мьютекс.
- Запускаем отложенный анлок при помощи defer.
- Проверяем, есть ли HTTP-клиент.
- Выставляем заголовки, которые при желании можно получать на входе в функцию.
- Выполняем запрос.
- Проверяем статус-код у ответа. Если он плохой, то пытаемся прочитать из тела ответа ошибки. Также не забываем запустить отложенное закрытие тела ответа, так как это поток.
- Реализуем метод Close, который обнуляет HTTP-клиент.
Теперь реализуем клиента к сервису категорий.
- Создаём функцию NewClient, которая на вход получает URL сервиса.
- Реализуем все нужные нам методы: получение, создание, обновление и удаление категорий.
Реализация довольно простая: получаем на вход нужные параметры, контекст и фильтры, дополняем фильтры нашей логикой. В случае получения категорий добавляем туда параметр user_uuid. Далее билдим URL и запрос, добавляем в запрос контекст и отправляем запрос. Закрытие тела в методе SendRequest надо делать, только если статус-код плохой. Иначе мы не вычитаем тело в нашем методе. Вычитываем тело ответа, ожидая там увидеть список категорий. Здесь нужно запустить отложенное закрытие потока тела ответа. Затем возвращаем список категорий. Добавляем щепотки логирования и реализуем остальные методы.
В Golang контекст является агрегацией действий и процессов. Он позволяет отменить их все. Например, пользователь сделал запрос, вы его получили, запустили в общем контексте два запроса и ещё несколько фоновых операций. В процессе работы пользователь отменил запрос. Нам нужно отменить операции. Чтобы не закрывать их все руками, вы просто вызываете метод Cancel у контекста. Все сделанные запросы также прервут своё выполнение.
В методах CreateCategory, UpdateCategory и DeleteCategory мы используем библиотеку structs, которая позволяет нам сгенерировать map из входной DTO-структуры. Полученный map мы маршалим. Получаем байты, которые отдаём запросу в виде буфера через конструкцию bytes.NewBuffer.
Когда клиент готов, добавляем его в структуру нашего хендлера категорий. В самом хенделере пишем код, который вызывает методы клиента сервиса категорий.
Во всех хендлерах, если вызов метода клиента категорий привел к ошибке, я отдаю код ответа «418 I’m a teapot». Использую его, чтобы обозначить, что запрос не выполнился из-за ошибки в коде, а не проблемы среды или недоступности БД. Также при получении списка категорий я начал реализовывать маршалинг структуры массива категорий и неожиданно понял, что просто так делаю сериализацию и десериализацию списка категорий.
В APIService я точно не буду обрабатывать данные списка категорий, а просто отдам их клиенту. Поэтому я вовремя одумался и зарефакторил код клиента, чтобы отдавать массив байт. В клиенте я их вычитываю методом ReadAll из пакета ioutil, а в хендлере сразу отдаю клиенту методом w.Write. Также удалил модель Category, так как она не нужна. При создании категории по всем правилам REST я отдаю заголовок Location с uuid созданной категории. Я мог бы не парсить заголовок от CategoryService, так как ендпоинты совпадают, но они могут перестать совпадать. Чтобы избежать багов, я решил распарсить сразу.
Также из контекста я забираю значение по ключу httprouter.ParamsKey и кастую в httprouter.Params. Значение в контекст кладёт библиотека роутера, которую я использую. Это удобный и быстрый способ получить значения из Query Path. В методах удаления и обновления категории я отдаю код ответа «204 No Content», а при создании категории отдаю «201 Created». Также в методе генерации токена доступа JWT я захардкодил UUID пользователя, который был создан в БД, чтобы протестировать решение. Этот хардкод уберётся, когда появится UserService.
В точке входа app.go я создаю клиента к CategoryService. Мне нужен URL до API сервиса. Его мы будем забирать из конфига, поэтому добавим эту настройку в конфиг, в код и в YAML- файл. Далее пишем тесты на все ручки хендлера и запускаем.
В следующей части мы займёмся разработкой микросервисов NoteService, TagService и UserService.
Группа автора «ВКонтакте», Telegram, Twitter.

4К открытий5К показов

Рабочий подход к тестированию трансформации данных в ETL-процессах. На примере Python-проекта с pytest, allure и psycopg2 демонстрируется, как автоматизировать создание и наполнение таблиц, хранить схемы и данные, а затем сравнивать результат.

Алексей Власов, партнер и коммерческий директор ИТ-интегратора Notamedia, рассказывает, с какими киберугрозами сталкиваются B2B- и B2G-сектора и как организациям защитить свои данные.

Особенности файловой системы в ОС Linux, как ей управлять и что такое монтирование. Типы файлов и файловых системы в Линукс.

Что такое Sharding. Показываем, как работает шардинг в базах данных. Рассматриваем пошаговую инструкцию и основные нюансы ✔ Tproger