


Как мы разрабатываем систему голосового управления презентациями на базе Whisper и GigaChat
Как создать инструмент, который позволяет переключать слайды с помощью голосовых команд и контекстного анализа речи. В статье разбирается микросервисная архитектура на React и Python (FastAPI), использование модели OpenAI Whisper для транскрибации в реальном времени и интеграция LLM GigaChat для интеллектуального ведения презентации. Также описываются проблемы нестабильности нейросетей в живых выступлениях и реализованные решения: режим байпаса и навигация по ключевым словам.
237 открытий11К показов

Наша команда разрабатывает инструмент для интеллектуального управления презентациями.
Пользователь может транслировать презентацию через "AI Кликер", а сервис будет записывать и транскрибировать речь спикера и аудитории. Спикер может переключать слайды простыми голосовыми командами или ключевыми словами, привязанными к конкретным слайдам.
Интеграция LLM позволяет реализовать интеллектуальные функции - переключение слайдов по описанию, контексту, генерация нового контента в реальном времени. Целевая аудитория — учителя, преподаватели и спикеры, на постоянной основе работащие с презентациями.
Архитектура решения
Наша команда использует JavaScript с React на фронтенде и Python c FastAPI на бэкенде. Мы используем PosgtreSQL как базу данных и S3 как объектное хранилище для хранения презентаций. Мы строим микросервисную архитектуру в нашем приложении.
Первый сервис - REST API для авторизации, управления личным кабинетом и контентом пользователя. Развернут на отдельном дешевом сервере за прокси NGINX, запросы шифруются HTTP
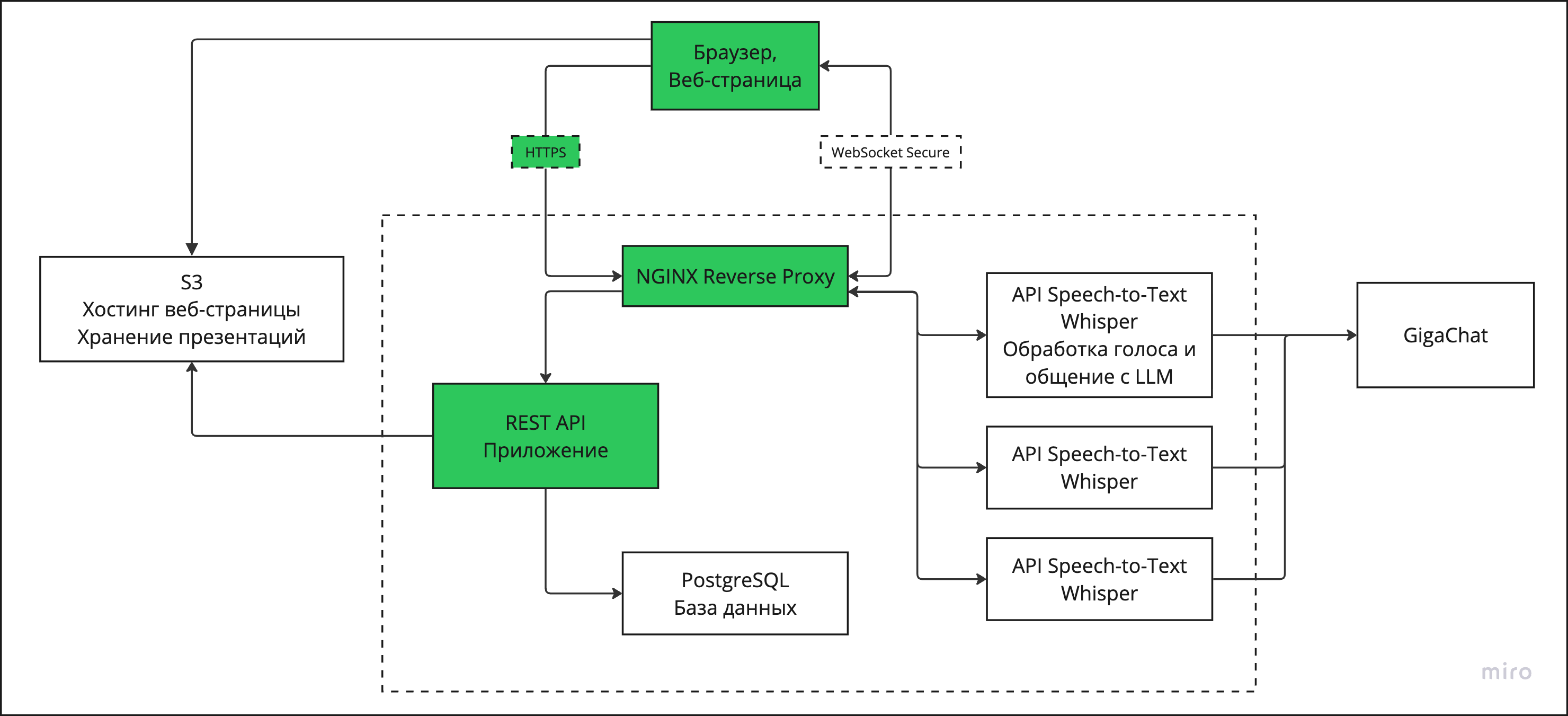
Второй сервис - API трансляции презентации. Двустороннее взаимодействие браузера и этого сервиса (передача звука и отдача команд по переключению слайдов) идет по протоколу WebSocket Secure. Отдельный сервис для трансляции позволяет нам динамически управлять дорогими серверами с GPU, уничтожать их, поднимать, экспериментировать с конфигурациями, не переживая о сохранности основного приложения. Модель OpenAI Whisper используется для транскрибации речи и GigaChat от Сбера как LLM для анализа контекста выступления и генерации команд и контента.
Работа Whisper
В AI-кликере распознавание речи - фундамент всей системы. Пока человек говорит, система должна получить текст, проверить команды, сопоставить с ключевыми словами, передать в LLM. Для этого обычного Whisper недостаточно — он отлично работает с файлами, но плохо подходит для живого потока.
Поэтому в проекте используется связка Whisper + WhisperLiveKit — библиотека, которая позволяет кормить модель аудио чанками в реальном времени, а не загружать готовые записи.
Байпас: ручное управление голосом
Одна из ключевых фич — байпас-режим. Это механизм, который позволяет управлять презентацией жёсткими голосовыми командами, в обход всей нейросетевой логики.
Когда Whisper отдаёт текст, он сначала проверяется не через LLM, а через механизм сопоставления фраз:
Дальше всё работает просто:
- если пользователь сказал фразу, похожую на “кликер вперёд” → слайд листается вперёд;
- если “кликер назад” → слайд листается назад.
Данная реализация позволяет пользователю в любой момент перебить автоматику и принудительно перелистнуть слайд. Это критично для надёжности: если LLM вдруг “поплыла”, у спикера всегда есть жёсткий голосовой руль.
Ключевые слова: автоматический переход на нужный слайд
Вторая важная часть — режим ключевых слов. Это уже не просто “вперёд/назад”, а сопоставление речи с конкретными слайдами.
Логика такая:
- Для презентации загружается набор ключевых фраз, который группируется по номеру слайда.
- Когда приходит новый фрагмент речи — он сравнивается с ключевыми словами и в случае успеха отправляет команду на переключение:
То есть фактически система работает как голосовой навигатор по презентации:
- сказал фразу, связанную со слайдом 5 → система предлагает перейти на 5;
- сказал фразу из блока 10 → прыжок сразу туда
При этом переход отправляется в очередь и дополнительно проверяется по порогу уверенности:
Слайд переключается только если вероятность достаточная. Это защищает от случайных совпадений и шумов.
Работа с LLM (Гигачат) - промпты, контексты, очереди
Если Whisper в AI-кликере отвечает за то, чтобы услышать, то GigaChat отвечает за то, чтобы понять, о чём сейчас говорит спикер и какой слайд этому соответствует. Вся работа с LLM построена асинхронно: распознанная речь не блокирует систему, а складывается в очередь и обрабатывается в фоне. Каждый фрагмент речи:
- попадает в очередь,
- добавляется в историю пользователя,
- отправляется в GigaChat,
- а результат в виде вероятностей по слайдам уходит дальше в очередь переключения.
Такой подход позволяет не тормозить распознавание речи, не зависеть от времени ответа нейросети, обрабатывать несколько фрагментов параллельно.
В чём возникла основная проблема?
Текущая концепция работы LLM строится на предугадывании номера слайда по смыслу речи. И именно здесь в реальных условиях всплыла главная боль проекта. На живых выступлениях выяснилось, что GigaChat может путаться между похожими слайдами и менять своё решение от фразы к фразе. В итоге презентация иногда начинала хаотично перелистываться, даже если спикер говорил последовательно и спокойно. Для пользователя это выглядит как будто “нейросеть сошла с ума и живёт своей жизнью”.
Пока проблема не решена полностью, в системе есть страховочный механизм — временное отключение GigaChat при ручном управлении. Если пользователь даёт жёсткую голосовую команду (байпас), то нейросеть временно игнорируется, а управление полностью возвращается человеку. Через несколько секунд автоматика включается обратно, что позволяет не ломать выступление даже в моменты, когда LLM начинает вести себя нестабильно
Практика показала, что угадывать слайд по смыслу — слишком нестабильная стратегия для живого продукта. Поэтому сейчас происходит переход к новой модели:
- было - нейросеть угадывает номер следующего слайда.
- станет - нейросеть находит слайд по его описанию. После определенной команды, система слушает пользователя, пока он не закончит предложение (как умная колонка) и тогда один раз выбирает и переключает слайд. Это снижает вероятность случайных переключений и делает поведение системы более предсказуемым.
Итоги
Мы продолжаем реализацию проекта и планируем скорый выход на рынок. Реализация местами еще сырая, но мы стараемся тестировать решение с фокус-группой профессионалов, работающих с презентациями, чтобы выработать лучшие решения, удобные для них. У нас получилось выиграть небольшой студенческий грант на реализацию, это поможет нам оплатить сервера и работу разработчиков.

237 открытий11К показов

ChatGPT научился редактировать фото и генерировать изображения через GPT-4o — теперь доступно в Pro-версии и скоро в API

ИИ-сервисы для генерации изображений быстро набирают популярность. В нашем обзоре — лучшие программы для создания картинок по фото и голосу, советы по выбору и полезные функции для профессионалов и творческих проектов.

Разбираем, чем отличаются WAF и Firewall, как они работают и когда их применять. Простые объяснения для начинающих разработчиков и аналитиков.

После ухода иностранных облачных провайдеров защита и ускорение веб-ресурсов стали насущным вопросом для e-commerce, SaaS-сервисов, госорганизаций и финтеха. Мы собрали три ключевых российских аналога Cloudflare — NGENIX, DDoS-Guard и StormWall — и сравнили их по возможностям, тарифам, особенностям и реальным кейсам.